专题研究¶
- C 语言的实现原理
- C++的内存对象
- python 源码解读
- 语言的设计
stage of GCC¶
对于程序的各个过程现在才有更深的认识,以前停留在浅层的认识。尤其是在IDE上更是不知道怎么回事。真实的过程。就拿C语言来说。 首先要区分的那就是编译与链接。编译的时候,是以文件为单件的,相互独立的。最终链接成一个应用程序。但是这个应用程序也非得完全意义的应用程序。根据不同的操作系统,会有不同要求。例如每一个库会公用的,哪些需要独立提供的。例如操作系统是如何操作一个应用程序的。
预编译¶
宏替换是全局的,所以要想保证唯一就要加各种各样的前缀,也可以gcc来查看各个宏的定义。
如何解决编译的问题¶
找不到头文件 ,是因为 -isysroot ,或者 -I 没有设置需要的路径。到底设置了哪些路径,可以通过gcc -v 来得到来查看其真实的设置路径。当然还会一些其他的调试手段,这个与gdb 的过程是一样,那如何对于gcc扩展,也就是LLVM如何来操作呢。具体的可以查看 例如
详情见 gcc manual 3.9 Options for Debugging Your Program or GCC ,基本上编译所有过程都是可以debug的。所以以后遇到问题,要能够用以前学过的那些编译理论来进行推理,并且通过这些命令来进行验证。VS的好处就是可以只编译一个文件,与配置每一个文件的编译属性,那个与makefile是一样的,make采用每个编译的都要指定编译参数,并且通过变量来进行复用。例如右键来设置命令行参数或者属性来进行调试。例如 -E -v 就可以通过 -o file 来可以查到预处理的结果,预处理结果会有注释,#include 是从哪个文件进来的。并且可以调试那些预处理命令。 今天问题的关键是没有思路,不知道遇到这个情况去利用已经有的知识去解决,单个文件的处理与大规模的处理之间的关系。 并且编译参数都是可以由环境变量来指定的,例如bash中可以用环境变量PERL来指定系统所使用的perl. 关于gcc的更多问题,还可以查看200711-GCC-Internals-1-condensed.pdf,以及manual.
找到的文件不是你想要的¶
这个就是今天link.h 的内容不对,原来apex取了ndk中的link.h了,如何解决这个问题,
- 快速搜索一下有多少个link.h,在linux 下使用find,grep,sort,diff等,而在windows下可以使用powershell,gci+select-object+out-file 等等。
- 利用gcc 的 -E -v来查看一下,它 include进来的结果到底对不对。gcc -E -v -o file 就可以查看到file中的预处理内容,预处理注释信息是用# 来说明,在第几行加载的。
- 可以根据规则,#include <>,”“,以及使用这些参数来控制优先级 Options for Directory Search 优先级,-I 要高于-isysroot, “” 会基于源文件的当前路径,而不会去找父路径。当前,-I,-isysroot.
-I -iquote -b, 查找exe 文件 -isysroot
编辑器找到文件,与gcc找到文件可能是不一样的。但通常情况是一样的。 也可以通过 #error 等指令来进行判断。 同时预处理文件格式说明参考 Preprocessor-Output.html 同时利用在语言本身中也是可以用#pragma warning/error等来进行编译的控制。 http://www.cnblogs.com/xiaoyixy/archive/2006/04/12/372770.html
例如你在期望的位置放 #error message 如果是你期望的路径就会报错。
同时这些头文件的先后顺序也会影响的编译的结果。 例如Nsight Tegra 的头文件搜索顺序

#ifdefine HFAFAF_FE
#error “something' __FILE__ __FART_NAME__
#message
#warning
#pragma
如果是链接找到不库函数,则是库的版本不兼容,如果出现mingle name不对,则是编译器的版本不一致造成的。换成统一的toolchain重新编译就可以了。
选项分类¶
| -m | Machine Dependent Options | -mfpu | |
| -M | 根据include以及宏定义自动产生 makefile的依赖规则 | 在make 中可以$CC –M 来使用 |
Code Overlays¶
If your program is too large to fit completely in your target system’s memory. we could use =overlays= to work around this problem.
- LD 讲解
- gnu-linker manual
- UNIX 目标文件初探
- ld命令初识
- ldconfig 用来管理与更新动态连接库的,更新/etc/ld.so.cache 例如 -p 就会打印系统所用到动态链接库。
- ld.bfd vs ld.gold it seems ld.gold can’t compiling the kernel.
- ld参数 now 主要解决符号解析,与segment的创建。
See also¶
#. abi application binnary interface, the object file structure and naming rule #. #. #. mouseOS 技术小站 关于汇编与机器码一个非常好的站 #. Including Frameworks #. PolyhedralInterface #. gcc 源码分析
thinking¶
profling when you want profiling with Gprof,gcov (gnu coverage of code), you need compiler with -pg, or use the ld . normally there are three version: #. release strip the debug symbol #. debug add the debug symbol #. profiling add the tracing function for gather the information
ld -o myprog /lib/gcrt0.o myprog.o utils.o -lc_p
the real system is that ctr0.o
objcopy you use it do format transform directly on .o and o.bin file. http://hi.baidu.com/weiweisuo1986/item/b8a142b8e3e46cec4fc7fd05 http://book.51cto.com/art/200806/78862.htm.
为什么避免干扰,一般把生成的/lib, /obj /build目录都分开,那么些在make or ant 是如何设定的。
代码的生成方式 --enable-static-link, --disable-shared -static 对于是生成exe,或者.so 只是编译的参数与链接的库不一样,完全可以同一套代码,生成多种格式。
debug information
-gtab produces debug info in a format that is superior to formats such as COFF.
-gdwarf-2 is also effective form for debug info.
如何查看当前编译的各种配置 gcc会有一个配置文件,spec 文件。 同时也提供了各种参数供你来查询,例如-dumpXXX,-printXXXX等。同时也-spec 来指定配置文件。 具体的语法是3.1.5.并且gcc 只是一个前端,他在后端去调用各种宏替换,以及编译器,连接器等。所有的参数都是分发都是根据配置文件来定的。如果这样的话,是不是可以利用gcc的壳来实现一些自己的东西。gcc 的强大在于,支持重多的参数多,把各个后台的参数都集中起来。 并且这个配置文件也是支持脚本的。看来脚本在计算机大老里是一个很容易的事情。自己是不是去读一下 reference1 , Howto SpecsFile 配置toolchains的过程其实就是很大一部分工作就是这个specfile的修改过程。 自己做导出4.7.2与4.7 spec 可以通过diff,同时学习下这些语法。 并且对于这种脚本语法进行一下总结。类似于gawk,他们表一般都一些全局的特珠变量,以及正则表达式的替换规则,以及巴斯特范式。 – Main.GangweiLi - 25 Apr 2013
如何解决循环依赖
Circular Dependency 可以动态替换的方式。产生了鸡与蛋的问题。对于gcc 可以使用–start-group –end-group / -( -) 这样来保证的循环。一般情况下。LD会自动判断依赖的。 gcc 库顺序问题解决方法 lib.a 静态库,*lib.o*动态库。
-W 来控制所有的告警,gcc把后端的所有输出都集中这里,这个是如何做到,并且保持这种灵活性。
– Main.GangweiLi - 25 Apr 2013
gcc 对于管道的支持
巧用:
echo -e '#define cat(c,d) c##.d \n #define mb(a,b) a##@b \n mb(cat(xiyou,wangcong),cat(gmail,com))' | gcc -E -xc - 2>/dev/null |tail -n 1
from http://wangcong.org/
– Main.GangweiLi - 25 Apr 2013
FP寄存器及frame pointer介绍 函数调用的栈的标志位,这个这个寄存器来快速得到当前那个这个函数栈长度。如果没有,就只能根据指令来了。对于backtrace时就会很麻烦。一般情况下没有了FP,很多系统不支持backtrace.为了简单。 Register Usage 这么多年的困惑终于明白了,一直想知道C语言如何来直接操作寄存器的。原来在编译的时候,可以根据ABI接口来定义寄存器的分配规则。来动态分配。为了能够尽可能接近人直接编写汇编的效率,人们对于编译原理进行深入的感觉 ,并且研究各种算法来帮助我们实现。目前最新的LLVM采用SSA的方法大大简化了跟踪方法。只要分析抽象分析归纳终究是能够找到好的方法的。正因为有编程原理,我们才可以利用向自然语言的描述与机器打交道。只要找到一种简单有效的map规律就可以简化我们操作。
Nsight Tegra has three configuration
debug -g -O0 -fno-omit-frame-pointer
profile -g -03 -fno-omit-frame-pointer
release -03 -fomit-frame-pointer
– Main.GangweiLi - 08 May 2013
如何在代码中控制优化的行为 gcc 6.30 Delcaring Attributes of Fuctions, 定义了对函数的各种属性,以及变量也有各种属性,例如volatile, register等。都是为了控制编译与优化的。告诉你这一段代码有什么特性。还让编译器来做一些特定的事情。就个与今天所听到openACC。通过指令来标记代码,来让编译器来优化与改变。例如多核,情况下来保护现有代码。例如可能把所有代码都重新再用cuda写一遍吧。例如这里有各种`实验 <http://www.cnblogs.com/respawn/archive/2012/07/09/2582078.html>`_ ,同时也想起当然那个bell lib的那个有趣破解故事。__declspec C99标准里只有extern, static等几个关键字。
– Main.GangweiLi - 09 May 2013
对于预编译 如何预防重复的加载呢,以及循环加载呢。采用宏定义,不能完全避免。因为你也不知道你的include的文件里已经include了。#if ndefine pragma once 当然另外一种预编译那就是提前编译好现成,可以只提供一个空文件名来骗过编译,只在链接的时候直接读库就行了。
编译与连接问题 include路径不是嵌套原因,原因在搜索机制,它是简单通过再组装来判断文件是否存在进行搜索的。所在编译的时候,要么指直接用绝对路径来指,要么就是先指路径名,然后再指文件名,这样让编译器的搜索机制来处理,当然这会有冲突,这个与搜索顺序有关。找不到的原因,经常的原因是路径有空格之类的问题,不管IDE 工具的什么样的继承,或者additonXXX之类,不过是都是编译的-I XXXX 中一员而己,无非是编译的顺序不同而己。在IDE中出现这个问题,很大部分原因会是编译器并没有把选项传递给编译器。 现在突然明白了所谓的IDE工具都是如何工作的了。并且有IDE工具在收集错话的过程会把详细的信息给丢了。只有最后的yes or no的信息,如何才能收集到更加信息呢。那就是直接在命令执行这个编译命令。并且还可以打开编译器的log信息。来进一步定位。
另外一方便也可能是toolchain本身的兼容性,特别是ld.更是如此, 以及如忽略那些undefined symbols.等等问题。
– Main.GangweiLi - 02 Jul 2013
如何在代码中加汇编 一个方式那就是直接ASM(),具体的语法可以看Inline CTX in CUDA.pdf 相当于一个函数调用,参数传递函数参数的传递,但是代码是直接copy到输出的。 其实原理也很简单,就是m4中的替换原则,这个就是那些直接copy输出到就行了。其实M4是原始的编程语言,可以直接实现各种转换,而scheme需要少量的delimiter同样实现这些。所谓的那些lambda理论都是可以用m4 来实现。不过现在都简化成列表了。其实更加像现在sphinx一样,加入少量的原语标记,就可以实现实时再编程。把CDF直接做出来,就像我可以简单在一个文本简单的处理一下,可以变成python的collection,dictionary或者复杂结构了,解决xml更加简单的做法,那就是直接替换成python的数据结构,直接实现嵌套进去就解决了。 例如xml->.py -> import it. this is perfect. no need other lib to do this.哈哈看来可以把文本处理再提高一个水平。后面直接scheme或者haskell来实现与解决这些。看来需要时间把rackit抓紧时时间学一下,然后研究一下王垠的那些理论了。同时也慢慢对LLVM会有更深的认识了。
GCC¶
编译过程,主要分为两大块,把C语言翻译成ASM代码,然后ASM编译成机器码。
GCC优化集中C到—>ASM这一段。
同时c++也是这一层。 而LLVM把每一层通用化,就可以层层优化。GCC在语言之前用M4 对c代码,进行一次优化定制。解决写重复代码的机制。
所以这个翻译的过程,基本都是这样的过程,这一本身的优化,以及往下一层的翻译功能。 同时还要有一个linker的机制,如何一个个的小文件单元合成一个大的小文件单元。
https://en.wikibooks.org/wiki/Category:GNU_C_Compiler_Internals
预定的宏用可以用调试,或者生成版本号。 __DATE__,__TIME__,__FILE__,__LINE__
一般情况下,C/C++编译器会内置几个宏,这些宏定义不仅可以帮助我们完成跨平台的源码编写,灵活使用也可以巧妙地帮我们输出非常有用的调试信息。
ANSI C标准中有几个标准预定义宏(也是常用的): __LINE__:在源代码中插入当前源代码行号; __FILE__:在源文件中插入当前源文件名; __DATE__:在源文件中插入当前的编译日期 __TIME__:在源文件中插入当前编译时间; __STDC__:当要求程序严格遵循ANSI C标准时该标识被赋值为1; __cplusplus:当编写C++程序时该标识符被定义。·
__cplusplus:当编写C++程序时该标识符被定义。·
![digraph GCC {
subgraph cluster_flow {
label = "flow";
rank= same;
preprocessing -> compilation -> assembly -> linking;
};
subgraph cluster_software {
rank=same;
label = software ;
sourceCode;
compilerFile [label = ".S"];
OBJFile [ label = ".o"];
exeFile;
}
preprocessing ->sourceCode [label = "gcc -E"];
compilation -> compilerFile [ label = "gcc -S"];
assembly -> OBJFile [ label = "gcc -c"];
linking -> exeFile ;
}](../_images/graphviz-b52e860394cd5ef1b3df81989abf7cb68377c8b9.png)
优化实例¶
在编译Gameworks 中Bloom时生成x86结构的代码的时候就会出现 :error:`size of array "NvCompileTimeAsert_Dummy" is negative`, 这个由于内存对齐问题产生。 不同的硬件对于对齐有不同的要求。gcc 提供了灵活控制,对于一个小结构。#pragma pack(n)来进行控制。但是对齐之后的数据的地址也是有些变化。
如果对于整体的要求,而可以 -malign-XX 来控制。但是会引起ABI的不兼合问题。see
On x86-64, ‘-malign-double’ is enabled by default. Warning: if you use the ‘-malign-double’ switch, structures containing the above types are aligned differently than the published application binary interface specifications for the 386 and are not binary compatible with structures in code compiled without that switch.
—Page 231 of gcc.pdf
- 算法本身对数据结构有对齐的要求,那么直接 -malign-XXX来进行整体控制。
no-strict-aliasing¶
http://stackoverflow.com/questions/98650/what-is-the-strict-aliasing-rule
也就是允许,同一块内存,可以用不结构体去读它,因点类似于 union的概念。而在实际的操作过程,就直接是指针操作了。 只要自己知道 其内部的layout pack了。
直接发利用instruments代码中添加trace¶
直接利用 -finstrument-fuctions 与 -finstrument-functions-exclude-file-list=file,file,.. 来实现
你要提供这样两个函数
void _cyg_profile_func_enter(void * this_fn, void *call_site);
void _cyg_profile_func_exit(void *this_fn,void *call_site);
同时可以参考 例子 https://github.com/gwli/code-samples/tree/master/posts/nvtx
或者参考另一个例子 https://mcuoneclipse.com/2015/04/04/poor-mans-trace-free-of-charge-function-entryexit-trace-with-gnu-tools/ 代码见 https://github.com/ErichStyger/mcuoneclipse/tree/master/Examples/KDS/FRDM-KL25Z/FRDM-KL25Z_FuncTrace
并在代码中添加 getpid gettid 就可以生成timeline了。
#include¶
中的文件路径名,怎么写是根据你的include path来的,与环境path 的方式是一样,直接发路径拼接起来去找的。 就可以了。有的时候 egl.h 找不到, 但是EGLegl.h 就可以找到。区别就在于 include path不一样。
-funsigned-char¶
不同的系统中 char的定义是不一样的。分为signed 或者unsigned.
-inline¶
在一些版本上格式的有一些要求,不然会报错。http://10.19.226.116:8800/trac/ticket/6132#no6
.o 与.so 的区别¶
本质的区别,.so .a 都是.o ar包,区别在于地址形式的不同。libtool工具同时解决库依赖的问题。 用libtool和生成库会自动管理依赖。 并且不同平台的库的搜索方式是细微的不同的。
asan-stack¶
address sanity analysis. 地址分析。
ipa¶
程序块间的依赖分析。
pta¶
指针分析
branch-likely¶
可以根据优先级概率来生成代码。可以参考 https://gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html
什么是ABI¶
ABI 的发展史也是程序发展史,从最初的打点卡,一步步地解决执行的效率的问题,另一个那就是复用的问题,还有编程复杂度的问题。
符号修饰标准,变量内存布局,函数调用方式等这些跟可执行代码二进制兼容性样相关的内容称为 Application Binary Interface.
ABI 发展一直就是复用性演变的结果。 只要实现一次动态,就要加一个表来实现转接跳转。
从代码要复用,就要地址无关,那就要从定向,数据也是一样的,也要实现平台无关也要重定向。所以也就有了各种各样的动态表。
一般流程, CPU取指令,如果发现取令地址为征,就要触发中断来找查了。这样的效率是要比静态的要低。
代码重定向从简单分段,到后面真正的动态。是要两张表的.
ABI的发展,也就是ELF的发展,也就是计算机发展史,同时也程序的发展史。从一开始的卡片机,那时候的单进程。并且每一次都只能从头开始。在到后来,可以多条进程串行,而不用重新来过,或者调整地址。而实现重定向功能。而实现分段功能。同时由于程序局部分性,程序的执行也不需要所有代码都在内存里,只要其前后再里边就行了。这样也就产生了页式内存了。每一次只用加载一页就行了。但是每一次加载一页就地址就又得重新调整。这也产生虚拟地址。这样每一个程序都独立占有4G的内存空间。这样也就彻底解决了多进程的问题,以及内存不够的问题。 这个过程也就是内存管理的过程。
每一个进程的地址空间是这样的分配的,内核空间占用了高位的2G左右地址,而实际上在内存的低位,这样方便的计算,最大地址-虚拟地址就是真实的物理地址。而从内核高位的向下生长的的栈了,而堆在是下面向上生长的,最低位的一些地址,两者往中间挤,程序的内存放在中间,而Data分区放在低位,而代码段data之后。
加载的时候,属性相同的段也是可以合并的,内存的分配了,是按照页分配的,如果把属性的段合并在一起就可以减少了页的碎片的浪费。并且每一个段根据属性,只读或只写,或者可读与可写。有了这样的分类,就可以对其安全保护,对于只读的代码是不有写的。这正是elf中段属性可读与可写的规定,并且代码出现段错误,也是读写不该读写的段,同时想进行线程注入,首先得那这些标志位给改掉。
而这个完了之后,我回来头看程序本身,内存本身很宝贵,要就尽可能节省内存了。就要看看程序能不能节首的一些空间。程序也最多的静态链接,变成动态链接,以及运行时加载。
静态链接是方便,但是重复太多,浪费的太多的内存,就想一些公用的库来共享使用,这样就想到动态的链接,也就是态链接器的用法,那就是加载时链接,-Share 就是要加载 进行连接。一个公用函数在每一个程序的使用的位置也不一样的。这样需要保证要有重定位的机制,来适应的不同的地址。这样就可以让这些动态库在不同的地址空间有不同地址。这个就使用 地址独立了。这也就是 -fPIC 的用途。它是如何实现的法,也没有什么好的办法,通过添加一级来进行查找,能做那就是查表了,也就是 .got 的用途。
.got 用于数据变量的重定向,而.plt用于函数调用的,好像也不完全是。 就是通过这两个表来实现的调用依赖,并且在链接的时候也是在不断更新这两个表。 https://www.technovelty.org/linux/plt-and-got-the-key-to-code-sharing-and-dynamic-libraries.html 这里采用两级表,首先,GOT里记录一个起点,例如libc.so 的起点在哪里, .plt记载了当前这个函数或者变量在偏移量,libc.so的偏移量为20地方。 所以在plt表时经看到 最后相当于拿到起点值,再加上移值量,基本上三条指令。 第一条从r12得到全局表,第二条得到起点值,第三条得到需要的值。正好pc值,这也就跳转对应的代码了。而下面这表就是当前.o文件plt. 根据这个表找到libc.so 中 raise:的位置。
pthread_create@plt:
0x40693644 add r12, pc, #0, 12
0x40693648 add r12, r12, #401408 ; 0x62000
0x4069364C ldr pc, [r12, #892]! ; 0x37c
pthread_gettid_np@plt:
0x40693650 add r12, pc, #0, 12
0x40693654 add r12, r12, #401408 ; 0x62000
0x40693658 ldr pc, [r12, #884]! ; 0x374
pthread_kill@plt:
0x4069365C add r12, pc, #0, 12
0x40693660 add r12, r12, #401408 ; 0x62000
0x40693664 ldr pc, [r12, #876]! ; 0x36c
pthread_setname_np@plt:
0x40693668 add r12, pc, #0, 12
0x4069366C add r12, r12, #401408 ; 0x62000
0x40693670 ldr pc, [r12, #868]! ; 0x364
__timer_delete@plt:
0x40693674 add r12, pc, #0, 12
0x40693678 add r12, r12, #401408 ; 0x62000
0x4069367C ldr pc, [r12, #860]! ; 0x35c
__timer_gettime@plt:
.got 主要用于模块间的符号调用,表格中放的是数据全局符号的地址,该表项是在动态库被加载后由动态加载器进行初始化,动态库内所有对数据全局符号的访问都到该表中取出相应的地址。即可做到与具体地址了,而该作为动态库的一部分,访问起来与访问模块内的数据是一样的。 所以每一个模块对外部的需求都放在got中,这样就可以实现了自包含了,你给我一个正确的地址就行了。 代码的链接过程,包括代码本身的代码的共享与数据的共享机制,并且还有还要冲突的问题。
延迟加载的实现,就用了GOT.PLT,这样只需要在第一次使用外部函数的进行解析,而需要事先解析全部的函数地址。
.rel.dyn 主要是为了全局变量,.rel.plt 主要是为函数的跳转。 http://stackoverflow.com/questions/11676472/what-is-the-difference-between-got-and-got-plt-section LD_BIND_NOW 环境变量可以控制, 在应用程序加载的时候就解析,而非等到使用时再解析。 http://refspecs.linuxfoundation.org/ELF/zSeries/lzsabi0_zSeries/x2251.html
fun@plt:
jmp * (fun@got.plt)
push index
jump _init
这样不是第一次调用,则在GOT.PLT表中存好了函数地址,就直接执行了,没有没有把 index 放在栈中,然后调用 _init来填充表项。
每一个module的 数据段都是独立的,都是通过GOT表来进行依赖的查询的。
为什么要有链接方式呢,就是为方便复用,解决地址冲突的问题的。在写代码的时候,命名冲突,这包括函数名以及变亮名,这也就有了命名空间以及demange的做法,所以在函数连接失败某些东东的时候,一个原因生成的符号不匹配。 利用 external C 来实现的。 也就是为解决符号匹配一致的问题。另外在链接还需要地址修订的问题。可以静态的时候做,也可以用动态加载的时候去做。动态的时候时候做 ELF 就会各种各样的 .rel.XXX 这样段,来指定某一段应该如何重定向。
现在对于整个编译是有了更深的认识,在预编译阶段,include 的各种源码都加载进来,所谓的那些头文件,只是为fake卡的,也就是为即使你不用编译原码本身,就可以我们的代码认为我们已经有这个函数可以用。而真正的函数地址在哪里在编译的时候并不知道在哪里。而是等到链接时候,才能知道真正的地址,所在链接之前,还是必有符号表的,这样才保证找到真正的地址。
在编译的时候,每个源文件都要所有的符号都存在,即使那是一个假符号,而在符号表里,符号会被标出来哪些是本地已经有的,哪些是需要去外面找的。在链接的时候是会把这些符号进行合并,并且也还会解决符号的冲突问题。
之所以能够重定向,为什么知道不同的文件里大家调用是同一段代码呢,那就是通过符号表。大家引用了相同的符号表就是说明调用了相同函数。如果出现同名就可能出错了,这个与你链接的时库查询顺序是相关的。
这个库的顺序就像PATH是一样的,是由 /etc/ld.conf 来指定的, 并且操作顺序一般好像是
- /usr/lib
- /lib 这个下面一般都 sbin的一些库。
- /usr/local/lib
为了减少空间,同时也为提高解决问题方便,可以符号文件也可以单纯放的,linux是放在 /usr/lib/debug下面的,并且是根据文件名或者build-id来进行识别的。
如果想要到这个过程进行控制的话有几个地方是可以控制的
- 全局性的控制, /etc/ld.conf
- 临时性的控制利用环境变量, - LD_LIBPATH_PATH - LD_PRELOAD - LD_DEBUG
- 程序链接时参数 -L -l
- 代码级的控制,那就是label了,etext,edata,eend等等。记录了其特殊的位置。
在不需要对符号级的指令调整,就可以把symbols给strip掉了,这个一般在编译时就可以做了。 在加载的时候,都不会有函数级的指令调整,一般都是module级的调整。
Symbols Table Format¶
https://sourceware.org/gdb/onlinedocs/stabs/Symbol-Table-Format.html
格式,以及 利用info symbols 来查看一下。
struct internal_nlist {
unsigned long n_strx; /* index into string table of name */
unsigned char n_type; /* type of symbol * /
unsigned char n_other; /* misc info (usually empty) * /
unsigned short n_desc; /* description field */
bfd_vma n_value; /* value of symbol * /
};
然后再看看其是如何存储的。
对于profiling的采用也很简单,只要记录当时的指令的地址,然后根据地址来计算出 在所个文件里,哪一个函数里。这样callstack就出来了。
其实所有的二制结构,要么采用表机制,要么采用TLV机制,指针采用就是TLV机制,所谓的灵活, 那就是几级表的问题,目前复杂的ABI结构,以及操作系统memory结构都是这样的。只用table或者TLV或者两者都有,并且不只一级。
每一行source code 至少对应一条指令,source line/asm code 比值是多少。其实一个逻辑块越大越容易优化。 其实就像函数式编程。
在汇编程序层来说,都是机器的执行是没有区别的。但是在操作系统层面就一样的。就会有各种各样的调用约定,如果程序执行输入 与输出顺序,那就是参数传递机制。所以参数长度的检查很重要,过长就会靠成stackoverflow的问题。
BFDAandABI¶
这里就 ELF 格式为例, 来进行来研究。
例如pentak就是利用ELF头来判断binary 的架构的,一个简单做法那就是。
internal ElfHeader GetElfHeader(string packageName, int pid)
{
string header = SubmitShellRunAsCommand(TimeoutMs, packageName, "dd bs={0} count=1 if=/proc/{1}/exe 2>/dev/null", ElfHeader.Size, pid);
Contract.Assert(header.Length == ElfHeader.Size);
return new ElfHeader(Encoding.ASCII.GetBytes(header));
}
为什么变量的长短的以及函数名的长短的问题¶
这个的长短会影响不大呢,原来ELF 所有字符串会都会放在 .string table里,所有用到自符串的地方都会从这里去头,所以函数名与变量名的长度只是影响了 .string table的大小而己。 而在需要这些名字的地方是 .string table 的索引而己。
| PE | PE structure study | |
| ELF |
ABI 指的就是`ELF,COFF,和PE COFF <http://www.cnblogs.com/yizhu2000/archive/2009/03/24/1420953.html>`_ 这些东东,可执行文件的格式。不同的操作系统是不一样的。思考一个问题,同一个CPU对应的汇编指令是一样的,并且结构也都是一样的,但是为什么ABI为什么会不一样的。原因不同的ABI是内存管理分配的方式是不一样的。并且代码组织方式也都是不一样的。 例如`C++ABI <http://mentorembedded.github.io/cxx-abi/abi.html>`_ 这里描述了各种虚表的实现方式。
一个可执行文件对于外部库是不知道的,只是生成一个占位符,然后由加载器在加载的时候,去查找其位置,并把其替换成对应的地址。
对于面向对象的编程,函数表是在运行时,还是只存在于编译阶段,应该是都有吧,要不然,RTTI如何来做的呢。
什么东东需要知道ABI,OS kernel, linker,dynamic linker, 以及GDB需要知道这些。当然正常情况下都是可以自动识别的 另外就是处理器自身的编码格式,例如ARM采用的固定长度的编码。可以采用哈夫曼编码。所以ABI应该包含两部分,一个汇编指令集本身,另外一种它本身的结构了。汇编就是是汉字一样,要组成一文章还要一些文法结构。例如诗体,散文等。 #. `对于GDB你也可以改它的 http://sourceware.org/gdb/onlinedocs/gdb/ABI.html>`_ . #. ABI Policy and Guidelines #. API 与 ABI 一个通俗点的解释。并且可以检测这种变化的。 #. 向其它应用程序地址空间注入代码 #. PE格式文件的代码注入 #. 代码注入技术 #. ptrace应用之三代码注入 也可以利用
set write on ;show write
注意的是动态库libdynlib.so在编译时指定了-fPIC选项,用来生成地址无关的程序。
也可以利用ld脚本来进行代码注入。利用gcc进行注入的方法,也当然bell lib 所采用一种方式。
*COFF file structure*
when you add -g to gcc, when compile will add .loc .Ldebug_info: in assembly code and assembly will instore these in the symbol table fnd String Table and LineNumber Table of objfile. without -g, these information will be striped, so will can’t reverse back which line to line.
Object file is almost same with .exe file. the most different is that the address and entry points.
Options for Code Generation Conventions
Most of the options are prefix with -f. for different requirement, there is need different code(this code means final code,not the immediate code). for example the share lib need position-independent code.
elf,pe these are ABI, each one has its own structure, it specify the how the program is load into the memory, and this memory allocation for the process, where put the data,where put the code. where put on the resource. each section has its own function. when and how to use it and triger these code has specification. the how is virus generate and not to infect the exe file. all is base on ABI,
Virus the probelm for virus is how to triger execute malicious code. you utilize init stage or change standard lib call, this is good method, you can wrap the standard share lib call, interrupt the call link, for example, you change printf call, you change intercept printf, after execute you code and then return nomal printf. so you need study standard libc. how many call. how the share lib call. one of method change linker and loader of the system. the other method you can exception handle to trigger your code. dwarf is this way, this paper is also put on kuaipan/debug, there is the katana you can use it to do hotfix for binary code. for example currently running process. %RED%use this to implement Dynamic linker of exe%ENDCOLOR%
Libunwind this use ABI layout to discuss manipulate the stack of programming. there is a project libunwind , and Pentak begin add this. if So, it support SetJump directly. how to control CPU flow, one is use assemble. the other is that you just add function to the target program. As long as, the input and output is legal.
LD¶
程序的链接和装入及Linux下动态链接的实现 编译的时候,只处理本地符号,本地找不到就会标识成未定义的,然后由linker去查找修改。如果linker也找不到,就会报错了。所以出错,首先要看你调用是本地的还是。。 你可以用gcc -c 只编译成obj文件。可以使用objdump查看obj文件。例如 -dx还可以看到反汇编。 你可以通过find + objdump 来进行查找各种符号与汇编的信息。虽然不要求读懂每一行,但要知道常用调用,函数的开头与结尾要能够看出来。 linker is loader’s brother, and reversely. One of problem is how to redirect the address of your program. and GDB support this feature for debugging.
要想实现指令级的复用,那就得好好研究一下loader了。
normally the lib linker order is not specially, but sometimes you need a specific order. but the linker loaded it by the order you specify it. 当然如果出现你已经加载了某一个库,但还是报找不到链接或者未定义,这个时候应该就是链接顺序的问题了。 [[http://www.cppblog.com/findingworld/archive/2008/11/09/66408.html][gcc 库顺序问题解决方法]]。 并且可以用strace来跟踪你的应用程序调用哪些API。可以轻松知道应用起动的过程都做什么。
如果修改系统库的一些函数,这个时候,不需要加载系统库,不然会冲突,这个时候,你可以用 -nostdlib 或者-nodefaultlib等来做。libgcc就是其中之一。但是大部分程序都会需要它,-llibgcc. 当然如果想hook一个API时,在linux 下很简单那直接写一个自己.so 然后再加上一个LD_PRELOAD,这样应用程序在调用应API时,就会先在`LD_PRELOAD库去找]]。 而在windows 下会有一个 [[http://easyhook.codeplex.com/][easyhook <http://rafalcieslak.wordpress.com/2013/04/02/dynamic-linker-tricks-using-ld_preload-to-cheat-inject-features-and-investigate-programs/>`_ 与MS 的detour 来实现。
应用程序在加先从应用程序的地址来判断这个地址在哪一个库里,然后再查表找到相对应的库的符号表去查询。但是如何编译ABI不一样,例如C直接调用C++函数是不行,你还是发现找不到函数定义的,原因在于C++的函数在mangle方式与C的是不一样的,并且符号表结构也可能是不一样的。这样当然也就找不到了。
在解决链接问题的时候,要注意两点,对于编译问题,VS支持从当前编译路径去查找,所以在找不到定义的时候,自己或以来用这个方法来解决,如果却实没有,那就是漏了一些源码目标或者头文件。用-I 来添加。 对于链接问题,一个是用-L 来添加搜索目录,例外要用-l 来指定库名。 而-I(include)加载头文件,-isystem加载系统头文件。 并且通过预编译指令来控制编译。例如各种宏定义。
-Wl,–as-need 这样就可以避免链接不必要的库,另外ldd -u 可以查看到哪些库链接了,但是根本用不着。 * -Wl* 可以直接把参数传给linker, -Wl,-z,no execstack 现在终于明白C语言指针可做硬件灵活性在哪里,C把格式变成编格式就是最好LLVM了,并且C语言中指针,将来就是真实内存地址。当你想crack一些系统或者硬件行为的时候,利用C语言可以达到汇编直接操作,例如函数指针,例如符号表的得到,原来系统函数的地址,然后把地址改在自己的函数,并且函数的声明要原来一样,保证调用不会出错,然后自己处理,再调用系统函数,这也是各种wrapper的写法。在perl里,只就直接使用$e这些中断函数处理通过hook__DIE__这个函数调来实现的,在语言可以trap自己的函数来对segmentfault以及abort,exit等等进行hook处理。或者直接启动调器来工作。现在明白syscall有漏洞的用法了,因为syscall是不受权限限制,可以通过内核启动自己程序。这样解决权限的问题。
这就是如何用语言得到汇编的控制水平,因为在汇编可以任意改变PC值来改变执行的流。明白了汇编到了高级语言失去了什么。失去了对硬件直接控制,同时提高通用性。例如汇编直接硬件机器的指令,以及直接操作硬件的各种信息。而高级语言则失去这种控制,但来的通用性。但在有些时候,还想直接控制如何处理呢,可以通过在C语言中直接使用汇编来处理。另一个办法那就是找到精确的对应,例如如何直接控制PC值呢。当然在嵌入式编程中C语言是可以控制寄存器的。
现在终于明白了连接的意义从前到后。
如果想在带码中控制将来代码分配与装载的位置,可以用一些特殊的label,这些label是会被 linker认识的,并且在编译的时候是会保留的。
extern etext,edata,end 这三个是程序segments.并且可以通用 man end 来查看。
float¶
至于是用softfloat,还是hardfloat,这个取决于你的系统是不是有float指令运算集,如果有就直接用hardware来就会非常的高效,如果没有 只能用software来行转,同时为通用,那是不是可以在加载连接的时候去动态的调整呢。也就是所谓的JIT编译的一部分,其实更像了NVCC那样 PTX到SASS这样的效率就会更高。会根据真实的环境进行再一次编译来提高效率。也就是在汇编级的化简了。
程序需要链接根本原因是用于带码的复用。 链接分时静态连接,动态连接。 另外还有代码链接方式与数据连接方式。
LD_PRELOAD 预先加载一些库,这样可以方便把一个help库加载到要调试的进程空间,大大加快的调试的进程。这个特别是大的库的开发的情况下会用到,apk会在某个库里会失败,但是这个库却没有相关工具去查看。这个时候利用LD_PRELOAD把其引进来,或者利用python 通过ctype把库给引进来。
ABI 是什么¶
也就是如何生汇编的, 例如函数调用参数如何传递,以及寄存器的分配原则是什么。决定了如何生成由中间语言来生成汇编代码。
例如ARM 的寄存器规则。http://lli_njupt.0fees.net/ar01s05.html , R11 是栈指针,R11为SP。
一个简单的赋值是两条ASM 例如
int i = 1;
mov r0 #1
str r0 [r11,#-8]
函数内部实现变量,就是栈上加减的。
int add(int a,int b) {
return a + b;
}
int i =0;
i = add(0,1);
mov r0 #0
mov r1 #1
bl 0x<addDress>
##add asm
push {r11} // save framepointer
add sp, sp ,#0 //save current framepointer
sub sp,sp #12, //apply memory for parameter
str r0, [r11,#-8]
str r1, [r11,#-12] //pass the para to stack
ldr r2 [r11,#-8]
ldr r3 [r11,#-12]
add r3,r2,43
mov r0,r3 // r0 as return
sub sp, r11,#0 // recover stack
pop {r11} //recover last framepoint
bx lr //go to call point lr is saved by pc+1 of caller.
函数调用约定,以及寄存器分配策略。这个是ABI要解决有事情。
所以做优化时候要看ABI,而不是瞎想。
例如http://www.x86-64.org/documentation_folder/abi-0.99.pdf 主要内容 #. Machine Interface #. Function Call Sequence #. Operating System Interface #. Process Initialization #. Coding Examples #. Object Files
- ELF Header
- Sections
- Symbol Table
- Relocation
- Program Loading and Dynamic Linking
- Libraries.
- C lib
- Unwind lib
- Execution Environment
- Conventions.
所以变量声明也是对分配寄存器有影响。
为什么可以omit-frame-pointer¶
http://m.blog.csdn.net/article/details?id=49154509,因为只要参数固定,栈的大小是固定的,在编译的时候可以直接计算出 栈的大小的,直接加减就可以搞定 你看到
subq $8 $rsp
addq $8 $rsp
就是直接计算好了,而不需要在额外 pushl,popl指令了,毕竟差异还是很大的。
参数传递¶
在寄存器少时,是通过内存的入栈来进行参数传递,而当寄存器数量多时候,直接使用寄存器来进行参数传递,一般来说x86-64是6通用寄存器。 当多于6个时,还是用入栈的传递。 所以用函数参数尽好不要超过通用寄存器的数量。
具体还得查看硬件的手册,使其达到满速运行。 http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0488d/BIICDBDF.html
ABI 四方面内容¶
- Low Level System Info AMD_64 地址指针虽然是64位,但实现上只有48位,并有三个逻辑段,text,data,stack. 内存 Page对齐为4KB-64KB之间。
- OBJfile
- 程序动态加载
- lib
VMA的分配¶
- The system reservera a configuration dependent amount of verual space.
- Small code model. 方便程序跳转,因为跳转就要为PC赋值,采用立即数当然是最快的。 但是立即数的大小有限的。只能从0-2^31-2^24-1
- Kernel code model. 2^64-2^31到2^64-2^24.
- Medium code model. data section is split two path: .ldata,.lrodata,.lbss.
- Large code model.
#. Small/medium/Large (PIC). ABI 也要定义DWARF (Debug with Arbitrary Format).中寄存器的对应关系。· PIC code,必然用到GOT表。
llvm-tblgen¶
让编译器读懂硬件框架, 只有这样才能编译生成针对这个模型最优化代码。当然你可以添加尽可能多的策略。 所有东东都建立其逻辑device,并加载真实的数据,然后用软件仿真分析优化,这样就可以把硬件本身做的简单,而不需要复杂控制逻辑。 这个是目标代码那一块专门一个表来实现。 而在llvm 中tblgen就用来干这个用的。 http://llvm.org/docs/TableGen/LangIntro.html http://llvm.org/docs/TableGen/ http://llvm.org/docs/TableGen/LangRef.html http://llvm.org/docs/TableGen/BackEnds.html
TableGen文件td¶
由record组成,definiation and class. class是如何继承的。 并且使用let可以赋值。有点像racket.
同时文件类型也支持 include的操作。
当然也支持模板操作。同时支持C++注释语言。
tblgen ARM.td -gen-registery-enums -o ARMGenRegisterNames.inc
tblgen ARM.td -gen-registery-desc -o ARMGenRegisterInfo.inc
tblgen ARM.td -gen-registery-desc-header -o ARMGenRegisterNames.h.inc
register allocation¶
而汇编语言本身就是CPU的一种抽象。对硬件抽象主要是两大块,对于寄存器的描述。 而寄存器主要继承MRegisterInfo类,同时实现 XXXX.RegisterInfo.td, XXXXRegisterInfo.h XXXRegisterInfo.cpp
并且在XXXXRegisterInfo.td 中描述出目标处理器每个寄存品质属性,以及寄存器之间的别名关系以及程序 运行时的寄存器分本方案。 主要由个类严实: Register,RegisterGroup,RegisterClass,DwarfRegNum.
然后挨个实现各个虚函数就行了。
instruction selection¶
指令的实现也是样同,主要是TargetInstrInfo.类。 XXXXInstrInfo.td, XXXXInstrInfo.h, XXXXInstrInfo.cpp,
td 中需要描述目标处理器的指令集,指令功能,指令的寻址方式。 指令操作数,指令编码,指令汇编代码的输出格式。 以及指令与LLVM 虚拟指令的匹配关系。
记录定义ops,用于标识指令的操作列表。 Predicate类用来 描述指令进行匹配选择时 的所需的特定条件。 FuncUnit类用于建立目标处理器的功能单元。 InstrStage类用于描述指令执行中某一阶段。
同时出现不匹配时,还要处理 lowering的转换。
帧栈布局描述¶
主要是继承不愉快实现TargetFrameInfo类实现。
class TargetFrameInfo {
StackDirection StackDir;
unsigned StackAlignment;
int LocalAreaOffset;
}
函数参数个数与返回值个数是受寄存器个数的限制。不够的情况下就得 用栈来做了。
栈是内存中用于局部变量存储以及子进程调用缺少足够参数寄器时传递额外参数 的连续内存区域。 APCS(ARM Process Call Standard) 规定ARM为满递减堆栈。 使用SP做为栈指针,并规定栈的对齐大小为8个字节,也就 SP mode 8 ==0
函数调用约定, #. 当前的函数FP的指向地址 #. 返回链接地址的值 #. 返回的SP、FP值 。 。。。。 相关参数寄存器值。
常的函数内外跳转指令两种,一种是bl,一种是move. 直接move pc XXXX 可以全地址空间跳转。 而bl 只前后32M地址:
bl next
.....
next
.....
move pc lr 从子程序返回。
上层语言中函数,在汇编这一层就只有label,也就是代码块的起始地址。 而这些开始地址怎么来,是由汇编给你算出来的。
最容易调用的,那就是相对位置固定的,利用偏移量来搞定,当然由于直接发计算出来一般是在本module内部。 一个文件本身很少超过32M指令的。所以直接发BL 这种来跳转。
还有一些操作系统预留的函数地址,可以直接move pc 来得到。
其余的函数都是查表的,有一个符号表,那这个符号表,来知道各个function label的值。 就是那个 /poc/kallsys 那个mapping 表。现在明白为什么符号表作用的原因,函数地址查找,就靠它了。 对于函数级别之上地址查询都是符号表,而函数内部的跳转,基本都是采用相对跳转。这样才不会出错。 节省符号表。 理论符号表都是一直存在的。函数内部label是编译器自己定义的。 http://blog.chinaunix.net/uid-16459552-id-3364761.html, 各种函数在汇编层都是代码段标号,标号就是地址。硬件中断的地址是固定的。
因为ARM中 call出栈与入栈的顺序是固定的,其实就可以根据调用约定,来修改ret,sp这些等等。
f(ant a) {
void * ap = &a;
* (ap-4) = xxxx;
}
就改掉了你想要的值.
编译设置¶
在源码树中build脚本中添加编译的选项。
中间代码的转换描述¶
主要是操作数合法化,指令匹配选择等等。并不是指令都是一一对应的。不匹配时
- 目标处理器支持最小类型比LLVM的类型要大,此时将该LLVM类型的数据提升为目标处理器类型的数据 以进行下一步工作。
- 目标处理器支持最大类型比LLVM类型要小,把LLVM类型的数据折成数个目标处理可以支持 的类型数据以进行一下步。
这些合法化主要就是通过TargetLowering来实现的。
汇编输出描述: 主要是AsmPrinter类,与AsmWriter 类。
以及JIT的支持也都在这里。
- scheduling
- code layout optimization
- assembly emission
全局描述符¶
xxxx.td ,XXXXTargetMachine.h,XXXXTargetMachine.cpp 每一个目标系统都有 xx.td 文件,生成也就是解约束方程的过程。
如果经常做profiling,就像经常看这些评测数据,查当前最新的硬件水平。
函数的优化¶
使用函数可以提高复用性,减少代码的编写,但是它增加了oerhead,再在性能要求歌严格的条件, 去掉要保证,编写代码的复用性,又要去除代码调用的overhead.
其中一个办法那就是inline. 但是inline的函数只对自己编写的代码有效。对于库代码没有作用。
一个办法,使用靓态编译,但是只把需要代码拉回来,并且没有解决合并的问题。 并且完全静态编译的话,空间浪费又比较大。一个折中方案,那就是静动混合编译。 只对需要的函数静态编译。 即使是这样,还是一些额外的工作,例如把目标函数单独一个module, 虽然对这个module进行静态编译。
有源码情况下
gcc foo.c -Wl,-Bstatic -lbar -lbaz -lqux -Wl,-Bdynamic -lcorge -o foo.exe http://stackoverflow.com/questions/2954387/can-i-mix-static-and-shared-object-libraries-when-linking
没有源码情况下,可以直接发动态链接转化静态链接 http://stackoverflow.com/questions/271089/how-to-statically-link-an-existing-linux-executable 这个也是一些虚拟函数docker的实现原理之一。例如virtual box,chroot.
当然在编译的时候每一个函数编译成一个section,然后直接把那些需要直接抽出来。这也是静态链接的原理。
但还不是那么灵活,我想在任意的边界下实现最优化。 在什么样的范围内寻找最优解。 例如. all { a(); b(); c(); } 我们在什么样水平上优化,是在all中,把a,b,c放在一起来优化。 还是在a,b,c这级来进行优化。 并且保证其对等。 函数大小基本约束了编译器的优化边界。多大的函数最合适呢,这个根据最体问题来的。主要是根据profiling的结果来的,例如一个函数cost很高,但是其内部调用很多的小函数,但是每一个小函数cost也都不是很高。 这就说明这个函数内部的overhead太高。 要把这些overhead给去掉,就在在这个大函数为边界来优化
可以代码转化到LLVM中,然后再其中添加inline然后再优化。
函数优化基础是CFG的建立,CFG的建立,就是如何产生基本块。利用拓扑学的domintor树理论,生成基本块。 在CFG中,如果A是B的dominator,则从程序入口执行到B的任意路径一定经过A。 在指令这一层,在函数这一层。
每一个块的中指令都具有相同执行次数。
而CFG的化简,在控制流图化简 在复杂度相同的情况下,CFG的规模影响算法的效果。如果一个CFG仅通过如下变换能化简为一个节点,则它是可化简的: 如果节点n有唯一的前驱,那么将其和其前驱合并为一个节点 如果节点存在到自身的边,那么将该边删除 构造SSA SSA可以由CFG构造。
而CFG是控制依赖分析的基础。 https://www.zhihu.com/question/23269416/answer/43461637
DFA¶
Data flow analysis,变量的生命周期,指的就是在多少指令空间存活,有了CFG之后,就可以以基本块为单位来测量生命长度。 然后把CFG用符号化表示,然后在符号化之上再往前走一步,就实现了机器人理解代码的水平。 而见的DFA的分析有Constant Propagation,Range propagation, Reaching Definition,这个就是大家喜闻乐见的跳转定义处。的实现方式。 https://www.zhihu.com/question/23269416/answer/43461637
KLEE¶
测试就是用一种逻辑来测试另一种逻辑。其本质那就是从两条路得到的同样的结果才能保证的结果的正确性。
符号计算可以用到测试之中,可以用形式逻辑来理解代码的逻辑,利用代码块的拓扑结构 来理解代码,来自动的生成测试代码。
symbols execution,另一方面也就是形式计算。
而KLEE就是这种逻辑,利用符号执行来建立自己逻辑模型,然后再利用数学结构来进行验证。
静态分析 < 符号执行 < 动态执行。
为代码本身建立逻辑模型,最简单的那就是模式匹配,这是大部分的静态扫描所采用模式。
动态执行,纯手工测试,覆盖率太低。虽然也有自动化,但也只是基于手工测式的,生产率不高。
想要快速的发现程序的bug,就得能够自动理解程序逻辑本身,然后建立数学模型来进行推理验证。
基本框架¶
C code ->LLVM bitcode -> klee ->stp clauses -> klee ->output. KLEE 由于使用STP对于符点数是不支持的。
KLEE 本质就是利用符号计算,来实现路径的搜索。每遇到一个分支就fork出一个状态。 这样每一个分支就独立计算下去,也就是每一个state都保存下去,放在队列里,等待轮询。而EXE采用的方式是利用fork进程来执行,每遇到分支就fork出新的进程来执行。 直接到状态结构或者timeout。
你需要指出的是迭代timeout时间,
符号包括,变量,常量,以及LLVM内部的结点。
而KLEE 采用是STP 模型。
- State scheduling, 采用的随机路径选择。 或者基于覆盖度的优化搜索。
而外部环境建模也基本上采用inject方式对API进行HOOK来实现。也对部分API进行穿透。 同时HOOK API来人为创造例如硬盘full的事件。
KLEE only checks for low-level errors and violations of user-level assets.
路径搜索就会遇到 path explosion 问题,就会有各种搜索算法。
code-coverage的计算¶
在编译的时候就要生成 -fprofile-arcs -ftest-coverage 在编译选项中。 而产生路径分析的原理,基本块的定义,如果一段程序的第一条语句被执行过一次,这段程序中每一个都要执行一次,称为基本块,一个BB中所有语句的执行次数一定是相同的。 跳转ARC就是从一个基本快跳转到另一个基本块。
在LLVM中有一个sancov的工具来计算,函数级别的,指令级别的,基本块级别的。 clang.llvm.org/docs/SanitizerCoverage.html
约束方程的解,把各种溢出的判断变为一个约束方程组的判别,然后就可以利用各种约束 solver来求解。这样就可以实时计算与符号执行同步进行,一步步进行溢出检测,相当于在instrument 这一级别的实时检测: https://www.google.com/patents/CN103399780A?cl=zh
这里关键是有一个完备的中间指令集。而LLVM以及微软的IVL等等。
状态的优化¶
- expression rewriting
- Constraint Set Simplification
#. Implied Value Concretization #.
也可以版本控制的log来指出最容易出错地方。例如文件被改动的次数。 http://google-engtools.blogspot.com/2011/12/bug-prediction-at-google.html https://github.com/igrigorik/bugspots
一个在线试验 http://klee.doc.ic.ac.uk/#
EXE: Automatically Generating Inputs of Death¶
http://web.stanford.edu/~engler/exe-ccs-06.pdf
exe 是KLEE的前身,其主要做对STP的优化。 KLEE 的核心是符号计算,来实现等介计算。变成一个约束问题。
关于符号计算分析 都在往前发展,微软在这方面做的比较靠前。 https://www.microsoft.com/en-us/research/people/leonardo/?from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fum%2Fpeople%2Fleonardo%2Ffmcad06.pdf
并且在编译soup时,会自动把klee给编译好,而不需要自己再去找依赖。
Build for Android¶
make standlone toolchain
NDK_ROOT/build/tools/make-standalone-toolchain.sh \ --platform=android-21 \ --toolchain=x86-4.9 \ --install-dir=$HOME/Toolchains/x86-21 NDK_ROOT/build/tools/make-standalone-toolchain.sh \ --platform=android-21 \ --toolchain=x86_64-4.9 \ --install-dir=$HOME/Toolchains/x86_64-21 NDK_ROOT/build/tools/make-standalone-toolchain.sh \ --platform=android-21 \ --toolchain=aarch64-linux-android-4.9 \ --install-dir=$HOME/Toolchains/aarch64-21 NDK_ROOT/build/tools/make-standalone-toolchain.sh \ --platform=android-21 \ --toolchain=arm-linux-androideabi-4.9 \ --install-dir=$HOME/Toolchains/arm-21
LLVM IR 的核心是SSA-based(Static Single Assignment) representation. 为了实现这一目的,采用加下标的树做法,第一次用 var,以后就 XX.1 XX.2来标识。需要合并的的时候,phi,或者select来进行。 当然都是简单变量能够实现这些,而对于复杂结构体,可好像也是无能为力。 Commdat 主要于指示如何链接,例如ELF,COFF文件的哪些段,如何寻找那些在本module中没有定义的symbol.
另一个好像那就是IR自身信息的完备集,这一点不是很一个编程语言能做到的很好的。
通过 llvm.o 文件结构
- type定义
- 外部链接 comdat的定义
- 常量的定义
- 函数定义
- attributes
- meta 定义
LLVM 代码单位¶
- 指令集
- 函数集
- BB 块集
最后,BB块,放在ELF的某一个section,然后,就看symbols只是只要本section找,还是整个ELF空间找,并且查找到策略。 都是comdats 来指定的。
并且 comdats 的指令在直接分析opt的时候,是报错,找不到定义的。 优化时候,也是以基本单位来进行的。 采用是match/replace的方式,相当于原址替换。
所以优化是可以叠加的,但顺序不同,可能效果会不同。 这里解决前向的声明。 用于欺骗compiler.来满足定义在前的基本要求。
Well-Formedness¶
指的就是满足SSA,就是Well-formedness.
内存操作¶
Alloca 分配栈空间, malloc用于分配堆空间。 load,store read,write fence. cast,getelementptr 用于取结构体的子元素。 http://www.lai18.com/content/7919787.html
另一个是对原子操作的支持 cmpxchg,atomicrwmv,
把一些
dbg¶
需要产生dbg的信息的地方,都直接调用 llvm.dbg.declare来实现了。具体信息都放在 !dbg data中。
typecast¶
bitcast
phi值的应用¶
主要是用来解决类如
<result> = phi <ty> [<val0,<label0],….
a = 1;
if (v <10)
a = 2;
b =a;
b = PHI(a1,a2);
使其满足SSA的约束。 有点类似于 switch case的功能。
select¶
有点array中,下标操作,例如一个下标数组,只把取下标为true时的数据。 select <10 x i1> [0,1,0,0,…] i32 1,i32 9,i3…. 这个就是选i32 9了。
位操作¶
对于小于一个字节的单位表示, i1 表示一位,也就是bool类型。 经常在br 看到它,它用来表示类型。
ICMP¶
- eq equal
- ne not equal
- ugt unsigned greater than
- uge
- ult
- ule
- sgt
- sge
- slt
- sle
attribute¶
娈量,以及函数都可以有属性,并且这些属性还可以分组。
meta¶
也有大量的定义,例如DIFile来代表文件。并且支持BasicType,也支持SubrontineType,以及DerivedType.为了节省空间,支持相互引用。
blockaddress¶
这个就有点GOT的意思了,在哪一个module的中哪一函数。用于形成GOT,PLT的表的内容。
函数调用¶
正常的函数调用,就call,异常处理就用到invoke与unwind了。 invoke指令指定在栈展的过程必须要执行的代码。 unwind指令用于抛出异常代码并执行栈的展开的操作。 http://www.lai18.com/content/7919787.html
先进编译技术研究与发展¶
程序分析技术–发现程序并行性 芯片上的指令级并行和多线程并行编译技术 共享存储多处理上,发掘循环级和任务集并行的编译技术 分布式存储并行机上,解决代码和数据的分割 通讯优化和代码生成问题 在复杂的多级存储体系结构中,为是得到高性能,局部优化和预取技术必须与并行化技术结合。
LLVM的流程¶
IR这是LLVM核心, LLVM为了保证与现有编译系统,可以采用前端工具例如C/C++/python变成IR. 然后经过llvm自己的优化。 然后还可以自己的bc 字节码,然后用bc生成汇编,然后再gcc来生成binary. 但是现在已经有CLang来解决GCC的toolchain了。 IR能够实现自包含,从指令,到函数,再到代码块。并且把整编译chain 模块化,抽象化。 并且变成类库,方便每个人可以 根据自身的需求进行定制。
opt 就是一个optimizer manager, 你可以指定哪些pass要用,并且什么时候用。同时可以做全时优化。所谓的优化就是把根据 资源的特征来进行正确的分配。但是并不是所有的资源信息都是在编译时就能知道的。有些信息是链接时才能获取的。 有些信息只有在安装时才能获取的。有些信息是根据只有在运行时,才能获取的。
LLVM怎么做到这一点呢,LLVM把自己.o格式代码写在ELF中,当程序运行时,退到LLVM代码自动进行编译优化。同时可以也可以能够把 需要用到优化器抽取到应用程序中,让应用程序自身能够不断的优化。
LLVM 能够实现自动profiling优化,进一个目标那就是代码的自动演化。自我演化的关键是我自完备。 http://www.aosabook.org/en/llvm.html 代码生成的模块做的还不是很好,还在发展。
- Frontend 语法检查
- Optimizer
- Backend - instruction selection, - register allocation - instruction scheduling. tbl的用途,就是用来生成目标代码的。
![digraph llvm {
nodesep=0.8;
node [fontname="bitStream Vera Sans",fontsize=8,shape="record"]
edge [fontsize=8,arrowhead="empty"]
rankdir=LR;
XXX_Language-> LLVM_IR->TargetLanguange;
LLVM [
label="{LLVM PASS | \
ModulePass | \
CallGraphSCCPass | \
FunctionPass | \
LoopPass | \
RegionPass | \
BasicBlockPass}"
]
}](../_images/graphviz-87e0f003b16127656d6ef4ec0ea071e2ec36412b.png)
现在对于编译的应用才有了更深的认识,主要过程输入语言变成,变成中间语言,然后进行各种优化,然后再生成目标语言。例如为自己FPGA片子生成一个可执行代码了。利用LLVM/gcc就可以直接做到。 在生成汇编指令的时候,这里有一个中间RTL(register transfer Language),通过这个可以快速为一个片子生成不同目标程序。 gcc for arm,x86等等主要就是通过改写RTL来实现。 至于Register 如何分配,可以通过解整数方程来获得。以及求解来多项式来进行化简。以及生成一个语法树来进行化简。
编译的过程也是也是资源收集与分配的过程。高级语言主要用来收集计算需求,而低层语言以及硬件能力则体现的是硬件能力。而如何两者达到最大的match,则是中间翻译与优化目标。而这个功能可以由 LLVM来提供。 而传统编译器只是起到了翻译的过程。没并且起到一个资源分配的过程。而这个过程是要靠profiling来解决的。但是这些是可以利用contract编程以及测试来得到每一个函数使用的资源数的。 例如NEON的使用,如果完成采用手工写代码的速度太慢。 而是应该像CLOOG这样,输入计算模型与计算量生成执行代码。 例如protobuf一样的工具,来来大大加速你的编程过程。
通过数据依赖的分析,以及NEON本身的计算能力,实现一个NEON的代码生成模型。
编译指令的参数修改也是资源分配的修改。
ANTR+LLVM 更好的实现,利用ANTR实现前端实现到LLVM IR然后用LLVM往后编译。 #. 编译点滴 LLVM 的关注 #. llvm 编译技术最新发展方向 #. SSA Static_single_assignment_form ,在`这里 <http://www.lingcc.com/2011/08/13/11685/#more-11685>`_ 讲解,主要是对于变量的赋值只有一个次。这个类似于GTL中做法对于文件只写一次,然后就是读的工作量。对于以后每一次读进行版本控制。对于分支定义新的变量。这样变量的值改变就有了版本控制的作用。这样就可以精确的进行数据流分析。以及各种依赖分析。并且很容易跟踪版本的改变。这样就大大简化了后面的优化算法。因为所有的东西都具有了GUID,也就是全局唯一性。很方便跟踪定位。 #. llvm大事记 通过这篇文章看到,目前llvm性能还是不很好,但是架构清晰明了。前途很好。同时也可以看看编译技术的最前沿的论文。 #. LLVM 与ANTLR 一般编译器分两部分,前端与后端,前端进行进行语法分析,建立符号表与中间代码。后端来根据这些信息进行优化,例如画出流程调用图。在写解释新的语言时一个偷懒的做法,前端把处理成已知语言的中间代码,然后利用现有的编译器进行后端的处理。例如cfront是把c++变成c的中间代码。然后利用c的后端来进行操作的。
由于我们可以将字节码附在可执行文件中,所以也就保留了高层次的信息以便后面阶段的再优化。
如何使用 clang¶
使用环境变量,CC,CXX,CFLAG,CXXFLAG。 https://stackoverflow.com/questions/7031126/switching-between-gcc-and-clang-llvm-using-cmake
LLDB¶
See also¶
Thinking¶
用图论来化简 利用图论来分析数据结构以及流程path都可以用图来化简,主要也就是最短路径,避免循环等等方法。图论是化简最有效的方法。
– Main.GangweiLi - 19 Jun 2014
LLVM 优势就在于保留了所有信息,指令像底层的汇编,但保存了上层类层信息,类层信息,采用了C的语法结构。没有面对象对象结构,这也是为什么C语言的转换效率最高的原因,可以用C本身就具有这样的性质,把语句规范一下,就可像C汇编了。然后把变量看成寄存器,就是汇编了,就像所谓的Low Level virtual Set. 而原来的汇编指令是没有类型信息的,例如逻辑与算术运算,数据的传递指令。而没有存储空间的分配指令。而LLVM提供这个malloc,alloca的功能,把堆与栈的指令。然后根据指令使用情况对各种存储空间使用情况,来分配硬件资源。当所有有指令都变成算数运算与逻辑运算,再加上跳转指令,就相当于最基本的代数运算,相当于先化简,然后再求值。 化简就是编译,而求值就是运行。不化简直接求值,那就是代数中不化简直接代数求值,是傻X的作法。如何化简呢。 现在可以方法都已经用了2002-12-LattnerMSThesis-book_fin.pdf已经介绍了。先是局部化简然后再整体化简。局部化简的过程就是每一个文件的编译,并化简,然后link的时候再进一步化简,这时候整体化简,并且在运行时,还可以实时动态化简。可以这些PM数据保存下来,做进一步优化的输入数据。因为运行时的情况是千变万化的。
让进程像一样具有一定自主性,而优化算法可以是共享。每一个应用程序规定一下自己特征,PM过滤器采集哪些系统信息与自身信息,优化算法过滤器,本程序本身采用会哪用哪些优化算法。所以当进程闲的时候把开始自己做优化。其实就有点像GC的功能。 因为LLVM代码自身会存一会的,并且LLVM的代码会三种形式,文本形式,二进制形式,以及内存形式。三者是对应。而不像一般的汇编三者独立的。LLVM的指令集是可以在LLVM虚拟机跑的。并且自动保存了大量debug信息,方便调试。
– Main.GangweiLi - 20 Jun 2014
只要自己的语言到LLVM就可以在任意的机器像本地一样的速度去跑了。
– Main.GangweiLi - 20 Jun 2014
LLVM是一个闭包空间 可以不断的化简优化。opt-3.0 来指定各种化简。U:/project/LLVM/paper/02-Compiler-LLVM.pdf 非常简明的教程,只要把opt 变成opt-3.0就一切OK了。
– Main.GangweiLi - 20 Jun 2014
寄存器的分配 对于非常短的代码,完全可以在寄存器中操作,而非是一个标准流程,只要是函数,只要声明变量,就在内存中申请一块空间,然后在ldr进来,然后计算,然后存回去,浪费不少指令。小函数的局部变量完全没有必要申请内存空间。直接在寄存器上操作就行了。
优化方向
优化原则会限制代码规则的。出现异常的时候,一般都是代码使用规则是随意的与优化规则冲突了。gcc-strict-aliasing
用gcc来进行测试¶
完全用手工的方式去测试是低效的。但是测试与开发分开的话,确实只能这样的,但是让开发自己做呢,就可以大大的利用编译器与debug来进行测试。并且来提高效率。
例如用https://xpapad.wordpress.com/2009/05/18/debugging-and-profiling-your-cc-programs-using-free-software/ -Wall,来进行所有warning进检查。 -O2 进行没有初始化变量以及数组越界的检查。
-Wshadow 来检查重名的函数的应用范围。 -pg 会生成一个 gmon.out 可以让gprof来分析的。
寄存器的分配方法¶
其实就是一个解整数方程组的过程,以及多面体的问题,可以从http://cloog.org/ 来看到。从扫描多面体生成能达到每个顶点代码。自动编写loop. 但是解决一维线性方程组的整数解。
自动添加代码¶
用 -finstruction-function with __cyg_profile_func, 同时注意 添加 __attribute__((no_instrument_function)).
https://gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html#Instrumentation-Options https://mcuoneclipse.com/2015/04/04/poor-mans-trace-free-of-charge-function-entryexit-trace-with-gnu-tools/ https://mcuoneclipse.com/2015/04/04/poor-mans-trace-free-of-charge-function-entryexit-trace-with-gnu-tools/ 这个功能在clang中同样支持http://wengsht.github.io/2014/03/16/Function+Tracer+Using+clang+++–+application+and+principle.html
对Clang中还可以这样
-ftrap-function=[name] http://clang.llvm.org/docs/UsersManual.html#controlling-code-generation http://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization
debugging Options¶
JIT¶
每一种JIT都会对应一种计算对象模型,如果你的计算模型与之相差很远,自然优化的效果也不会好。
GCC很难当做lib来复用。
当然可以直接使用gcc 的python扩展来进行测试。 直接写测试用例,来进行测试。 当然这个也需要一些线程注入的技巧
也可以用LLVM来直接发改写代码,例如生成函数用LLVMAPI, 主要就是生成一个module然后连接一些block. 并且用API生成语句。 http://releases.llvm.org/2.6/docs/tutorial/JITTutorial2.html
优化的过程¶
- Look for a pattern to be transformed.
- Verify that the transformation is safe/correct for the matched instance.
- Do the transformation, updating the code.
clang¶
支持gcc 的流程, -E,-c 等等。 同时还有 -emit-ast,-emit-llvm
clang 同gcc 一样,是一个前端,同时自己实现了一个AST把C代码生成 LLVM IR。然后再IR上进行各种优化 然后再用ABI生成对应用平台binary.或者汇编代码,然后再成binary.
同时可以可以通过命令行参数 -fxxsanitize-xx=xxxx,xxxx来控制优化。并且还有blacklist的机制。
如何做优化¶
通过gcc一样的参数控制
直接生中间过程,然后管道传输了给opt了。 lvm-as < /dev/null | opt -O3 -disable-output -debug-pass=Arguments http://stackoverflow.com/questions/15548023/clang-optimization-levels
http://clang.llvm.org/docs/UsersManual.html#profile-guided-optimization
例如手工生成callgraph¶
https://github.com/gwli/CompilingDebugingProfiling/tree/master/experiments/clang_callgraph
JIT¶
想在自己的应用程序中使用JIT也可以直接使用了LLVM来实现。 https://pauladamsmith.com/blog/2015/01/how-to-get-started-with-llvm-c-api.html
主要过程就是创建一个Module,然后添加变量函数。再创建编译环境。 Module->Function->Block->Instruction. 当然通过API是可以看到IR的所有信息的。
当然自己在实现代码的时候,可以写一个AST来生成IR,也可以直接生成IR来做算法分析。
例如python来说,从4.0之后,llvm有自己python api wraper. 或者使用llvmlite,llvmpy,但是版本依赖很严重,要严格版本对应。 http://llvmlite.pydata.org/en/latest/install/index.html https://llvmlite.readthedocs.io/en/latest/
自己手工实现pass¶
http://llvm.org/docs/WritingAnLLVMPass.html#multithreaded-llvm 具体每个数据结构,就可以看例子。 https://www.cl.cam.ac.uk/teaching/1314/L25/4LLVMIRandTransformPipeline.pdf 主要是结承各个类,然后实现相应的虚函数。
IR结构¶
http://llvm.org/docs/LangRef.html#introduction 语言设计本身要具有完备性,它会结合高级语言,汇编语言以及ABI,ELF标准来定义。
把汇编label提升到函数。
- comdat 其实就是直接操作ELF,来分配 data-section.
特别之处,那就IR还有各种attribute,parameter本身有,函数也有。 另外还有metadata,可以用来存储额外的东东。 这样方便进行一步优化。
变量¶
分为全局变量与局部变量,还有临时变量,并且采用SSA的分析变量的用途。对于全局变量用comdat方式操作ELF的data-section进行。 也就是申请资源。 而于寄存器,分配还要化简
函数¶
prefix data, 是不是可当于 function static 变量 另外那就是数据对齐填充。 prologueData,用enabling function hot-pathing and instrumentation. 这个正是自己想要功能。
PersonalityFunction,用于exception handle.
- Attribute Groups, 可以后attribute合并分组,当然是一个module范围内。
Function Attributes, 主要是 #. noinline, alwaysinline, optize,cold,”patchable-function”,readonly
Funclet Operand Bundles,相当于闭包运算了。
Data Layout, 来规定不同平台的数据定义, 相当于C语言的种 typedef short int SUINT Target Triple,描述主机信息 Pointer Aliasing Rules,指针的用法 Memory Model for Concurrent Operations
Use-list Order directives 相关指令的关系。有点NEON的味道。
如何计算两个函数的相似度,利用IR来生成符号,充分利用符号替换来解决变量名的区别。 从函数入口直接把所有变量替换成中间变量。这样只剩下形式与指令顺序的问题。 http://llvm.org/docs/MergeFunctions.html 这样找到相同函数,就像可以替换。
利用相同的思路把找到最长常匹配块,split一个大的函数成多个小的函数。然后再编译的时候再用inline,这样即解决了模块化,又解决了效率的问题。
Type System¶
IR 是类型安全的语言。 指针还是*表示, Vector <4 x i32> Vector of 4 32-bit integer values.
Array Type: 类似C语言的数组,支持embeded 结构。 Structure Type: C的结构体 Opaque Structure, 相当于 C nontion of a foward declared structure. 相当于符号推导中符号。
Constants, Complex Constants
Global Variable and Function Address.
Undef values, Poison Values, 相当于
Addresses of Basic BLocks, 相当于GOT,PLT的功能。
指针是什么,就是申请资源时的,资源的url. 用到指针,就要资源的分配。
还有一些特征编译单元指令 DICompileUNit/DIFile/DISubgrance/DIEnumerator/DILocalVariable/DILocation./DIExpression. #. DIExpression nodes 来表示 DWARF expression sequences. 基本上LLVM采用图论的方式来进行优化。这些都相当于是一个node.
invoke¶
相当于goto 对于exception处理以及状态机来使用。
各种指令 <result> = shl <ty> <op1> <op2>
LLVM 这个原语树与Theano 的图的方式应该差不多。
Super Optimizer¶
让每个应用程序自主的优化,现在已经有人开始实现,现在叫Supper Optimizer.
让进程像一样具有一定自主性,而优化算法可以是共享。每一个应用程序规定一下自己特征,PM过滤器采集哪些系统信息与自身信息,优化算法过滤器,本程序本身采用会哪用哪些优化算法。所以当进程闲的时候把开始自己做优化。其实就有点像GC的功能。 因为LLVM IR 可以存有大量的MetaData 来做这些事情。
llc¶
可以用于生成目标机器码,同时还能生成反向的cpp 代码。 http://richardustc.github.io/2013-07-07-2013-07-07-llc-cpp-backend.html llc -march=cpp test.o / llc -march=cpp test.s 相当于反向工程了。
lli¶
虚拟机,直接运行llvm bytecode
Transform¶
这些pass为什么,可能由于代码的不规范,所以需要正则化。 更加便于分析。同时做一些初级的分析。化简也是变型一种。 本质就是一种是analyze另一种那就是transform.
LLVM 当前的问题¶
- wide abstraction gap between source and LLVM IR
- IR isn’t suitable for source-level analysis
- CFG lacks fidelity
- CFG is off the hot path
- Duplicated effort in CFG and IR lowering
并且SWIFT在LLVM实现一个SIL,同时加强了IR这些功能。
当然LLVM也有自己的限制,首先语言相关的优化只能在编译前端实现,也就是生成LLVM code之前。LLVM不能直接表示语言相关的类型和特性,例如C++的类或者继承体系是用结构体模拟出来的,虚表是通过一个大的全局列表模拟的。另外需要复杂运行时系统的语言,例如Java,是否能够从LLVM中获益还是一个问题。在这篇文章中,Lattner提到,他们正在研究将Java或者CLI构建在LLVM上的可行性。 新想法的诞生从来都不是一夜之间出现的,一定是掌握了足够多的知识,在不同问题的比较和知识碰撞中获得灵感,然后像一个襁褓中的婴儿一样缓步前进的。当然现在LLVM还存在很多问题,特别是跟应用很多年的工业级的编译器在某些方面还有差距,但是差距正在逐步缩小,附一篇Open64开发人员对LLVM的看法《Open64业内外人士对LLVM和Open64的观点》。
SSA的基础¶
各种各样的编译层出不穷,例如QBE号10%代码达到LLVM70%的功能,主要是基于SSA来做的, #. SSA 形式的构造本就是复写传播(copy propagation). #. SCCP (sparse condition constant propagation), SSA 形式上最经典的数据流分析与优化分析 之一。
面向局部性和并行优化的循环分块技术¶
局部性,意味着可以利用cache,如何自控制局部分块,并且充分利用多级cache来提高效率呢。 不只是简单的减少if else以及switch代码的问题。 调用本身也有很大的overhead,所以大对于大的循环来说,循环展开来减少overhead来提得高效率。
scan-build¶
http://clang-analyzer.llvm.org/scan-build.html 静态分析工具,直接分析代码。
直接在编译命令之前加上scan-build 通过改变一些环境变量与编译的参数来实现相关的检查。
有了符号计算之后,就可以变换模式的匹配了。
寄存器的分配¶
https://www.zhihu.com/question/29355187 这里有全面的总结了。 #. Expression tree #. Local (basic block) #. Loop #. Global(routine) #. Interprocedural 也就是资源与需求的搓合机制,有点类似于股票交易是一样的。主要是变量的生命周期的计算以及使用频度的计算。
变量的生命周期而是根据指令长度来算,现在常规的算法,直接从前往向后编号。这样是不对的。而是用二叉树,多维空间的表示。 指令周期模型,用拓扑结构更有效,而不是简单线性模型。
资源是有限的,寄存器放不下的变量,就像放进内存里了。 现在常用模型有线性模型,以及图着色模型,以及矩阵填充模型。主要是循环区域寄存器分配更重要。要寄存器分配队列与spill队列。 一种基于分区域优先级的寄存器分配算法.pdf
生命密度: 生命域的溢出权值 为生命域内变量定义和使用的数量除以生命域的长度。可以反遇溢出整个生命域的代价。 分区域方法是构造一个矩阵,对于小的循环,就意味着分块。
但是各种算法最后都变成一个计算问题。而计算本身还有一个P与NP的问题。
当然可以在代码中直接指定寄存器分配 ,例如在C语言中是有register这样的变量类型的。 同时在嵌入式开发中,也经常是变量与寄存器可以直接mapping的。
并且http://compilers.cs.ucla.edu/fernando/projects/puzzles/ 模型用来解决寄存器分配问题。
线性扫描主要是变量生存周期问题。 并且指令添slot模型来改进线性扫描。 http://llvm.org/ProjectsWithLLVM/2004-Fall-CS426-LS.pdf
寄存器分配的难点在于变量的生命周期,以及分时复用的问题。 http://blog.csdn.net/wuhui_gdnt/article/details/51800101
代码生成¶
https://github.com/wuye9036/ChsLLVMDocs/blob/master/CodeGen.md,是代生生成框架简述。 函数生成过程,先生成中间,然后再生成首尾的连接工作,就像IP包的构造一样。
内存管理¶
各种内存对齐是为利用cache,高效,但是为默认的struct没有办法重排呢,主要是其解读方式决定。如果像protobuf就可以这样干。
利用拓扑分析来判别离散与连续的数据结构及操作。 也就是lists,trees, heaps,graphs,hash tables,等等的可视化来进行优化。 以及对这些结构存取进行profiling就可以得到很好内存管理模型。这样就可以编译的时候就进行优化。 例如结构体重排,Automatic Pool Allocation. 而这个的分析就是要对cast, getmemeryptr,以及alloc,free等使用pattern的分析得到的。主要是对指针的分析使用。 显示内存分配和统一内存模型。LLVM提供特定类型的内存分配,可以使用malloc指令在堆上分配一个或多个同一类型的内存对象,free指令用来释放malloc分配的内存(和C语言中的内存分配类似)。另外提供了alloca指令用于在栈上分配内存对象(通常指局部变量,只是显示表示而已),用alloca来表示局部变量在栈帧上的分配,当然通过alloca分配的变量在函数结尾会自动释放的。
其实这样做是有好处,统一内存模型,所有能够取地址的对象(也就是左值)都必须显示分配。这就解释了为什么局部变量也要使用alloca来显示分配。没有隐式地手段来获取内存地址,这就简化了关于内存的分析。 用拓扑结构来分析具有天然的结构,例如点就是节点,线就是link,拓扑结构就代表了存储结构。 LLVM也可以将局部结构体对象或者列表映射到寄存器上,用于构造LLVM IR所要求的SSA形式。这一块我感觉应该是比较难的一块,编译器对structure或者说是memory layout的优化都是很难的一块
-targetdata,globalsmodref,Exhaustive-Alias-Analysis-Precission-Evaluator, memory-dependency analysis.
Structure peeling,structure splitting and field recorder. struct-array copy/inlining instance interleaving Array remapping https://gcc.gnu.org/wiki/cauldron2015?action=AttachFile&do=view&target=Olga%20Golovanevsky_%20Memory%20Layout%20Optimizations%20of%20Structures%20and%20Objects.pdf
LLVM的好处有自己独立的类型系统,通过对cast,getElementPtr就可以来分析内存的结构与利用率了。LLVM 包含基本的数据类型(void,bool.signed/unsigned,doboule,floating,int),并且长度从8bit到64bit,同时还有四种复杂的类型,pointer,array,structures,functions. 而c++的继承可以用结构体的嵌套来实现。
结构体重排¶
padding,alignment,point compression. 可以节省空间,提高cache的利用率。一个大的结构体按照使用频率,切成小结构体,并且放在cache里。
https://docs.google.com/viewer?url=http://users.ece.cmu.edu/~schen1/cs745/paper_pres.ppt
change data structure. structure splitting field reordering
而这些都是可以拓扑学来分析。 符号化之后,就像成点,关系就是线,面就是集合与组。 点线面关系也就构成拓扑学。
另外也可以用元编程来实现结构体的重排,我们在写struct的时候,并没有在意其内存结构了,只是注意其逻辑结构了。 只要在增加一层,再增加一层重排,这样就可以保证正确的结构了,而非一个随意的结构。相当于我们只是描述数据结构的需求。 而销定实现。
利用图论方法来对链表进行分析,然后用内存池的方式来进行优化,一般对于链表结构都是手工方式进行内存池的方式优化。 根据指针的类型与数据结构本身的关系来建立拓扑图。http://research.microsoft.com/en-us/um/people/trishulc/msp2002/mcd_msp02/adve_newpaper.pdf 并且根据每一段数据使用频率以及cache的cost建立相应的内存池以及结构体的重排。
基于当前的水平,DSA与automatic Pooling是技术发展的方向。http://llvm.org/pubs/2005-05-04-LattnerPHDThesis.pdf 函数摘要信息 procedure summary ==============================
好的摘要信息,可以直接使用摘要进行过程间分析,相当于增量编译了。
指令的优化¶
例如用一个复杂指令来代替长序列的指令。 窥孔 就是相邻两条开始,不断的加大窗口,但是首先还先找到原来指令集的等价关系。
如果硬件支持指令集并行,例如程序与数据空间是分开就可以充分软件流水线来实现ILP(instruction level Paralleism).
指令的分配与寄存器的分配是交叉的。
采用人工智能的方式来进行编译。
统计编译,首先要知道哪些指令要多少次,然后根据指令时间长短不一样,来解决采用哪一种方式,并且像GPU这样的对于寄存器的读写是有要求的,写完之后24周期之后才能读,这样的话,就要改变指令了。例如在这读写之间可以执行其他的命令。 所以在实现一个函数或者说明的时候,要指令说明这个函数的使用模式,例如函数是多次使用,还是一次使用,多次使用,其实也算是算法的性能维度分析。这个就是保证优化的模型。 基于theano的生成方法来来试验一下。 当对于同一个算法有多种实现的时候,就可以这么干了。 例如排序,对于你的调用就是排序,至是如何排交给算法工程师去解决了。然后直接优化在代码里。 其实就像cuda里的kernel,launch一样。函数里直接加上性能参数。 直接拿python来的sort来做一个实验。 或者theano来做。 这个与现在OPENACC有什么本质区别呢,是不是OPENACC之类正在做的事情。
Kepler 简化指令信赖关系就是靠编译器来做的,只要你事先要告诉编译器指令信赖关系,就可以用分析优化,例如读写指令是有latency的,例如 c=a+b;e=d+e; h=i+j;与c=a+b;h=i+j;e=d+e;效率是一样吗,一个关键因素那就是寄存器的latency了。有如果比较大,后者效率会比较高,利用了latency,但是可读性差。
其中一个重要问题,那就是如何隐藏latency的问题。
strict alias-rule¶
http://stackoverflow.com/questions/98650/what-is-the-strict-aliasing-rule, 就是不请允许用两种不同类型指针指到同一块地址上。这样会引起分析失效。
CFG优化¶
用图论. 如果A只有一个子,那就应该合并。从而减少调用overhead也就是直接inline.
加上context,这样就有利于编译的优化,如何定义context,以及自动识别这些呢。 是不是可以神经网络呢,提高 pattern的识别率呢,神经网络拓扑结构与CFG对比使用。 生志CFG并且合并且 dominator,同时根据回路算法复杂度分析。
同时根据CFG生成一个最小的程序切片来复现问题,其实就像KLEE中根据依赖生成路径。 根据关注点的不同,实现一个最小的可执行代码切片。一般在控制流图上根据数据依赖及控制依赖关系,采用不动点迭代求解
化简CFG就是要删除那些无效的符号,CFG有两种形式CNF,GNF,关键是产生式的形式的区别。 http://grid.cs.gsu.edu/~cscskp/Automata/cfl/node5.html 删除 Unit 产生式,以及空产生式。 http://www.tutorialspoint.com/automata_theory/cfg_simplification.htm
Clang 对于OMP 的支持还不是很好,https://stackoverflow.com/questions/33400462/omp-h-file-not-found-when-compiling-using-clang
How to Trace¶
- 生成callgraph,
#. 在各个边界点进行check,在不同的level api检查,并且在函数级别的,我们可以随时用各种 probe来实现,trace,而对于原码级,小于函数级别,就要用NVTX,或者log的功能实现。 其实把trace放在log中实现也是一种方式。 当然在函数级别的或者llvm IR级别,也是通过hook来实现一些东东的。
什么优算是最好的¶
在于信息的缺失与不确定性。 信息的缺失: 进行向下翻译以及transform的时候,会存在信息的流失,有的时候这个流失是我们需要的,有的却不是我们所期望的。 如果没有信息的缺失,有固定的方法来进行优化,那么让代码来做,比用手工做会更有效率。 同时在进行各种变形编译的时候,也产生信息的流失。哪些信息是下一层优化所需要的,哪些是多余的, 优化的要根据上下文来调整优化的顺序来保证 必要信息没有流失。 例如在汇编这一层,是没有内存分配这一书的,汇编指令是只有load,store读写操作,至于内存如何分配是由操作系统来决定的。
不确性: 有些信息本身不确定的,例如机器的配置信息,是在你写代码的时候,是未知的。为了保证正确性,我们采用的囚徒困境,采用了最基保守 的方法,自然就不可能最大化利用机器的资源。
所谓优化: 就是资源的优先级分配,就像下棋,什么时候,分给谁,多少的什么样的资源。 一方面弄明白算法的资源需求,另一个机器的资源配置。 然后实现二者的最佳匹配。
找到需求与限制的平衡点。 问题的编译技术是基于固定模式来的,也就是说按照语义编译的,还是字面的编译的。 #. 到底是资源不够,还是因为没有调度好。 #. 慢,是因为指令太多,还是因为因为在被block,这个就要API真实的执行时间,以及物理硬件的线速了之间的差异在哪里。 所以标准那就是要有每一个APICALL的执行时间上,最终都体现在时间上。那么标准时间如何而来。或者从大到小排序,然后直接以最小为基准。
在之前我们很能知道其极限在哪里。现在很容易了。
硬件极限是可以通过手册来得到。 代码的本身的极限我们可以用LLVM来的优化来达到。然后再生成目标的代码时候来实现二者平衡。
如果分析计算量的大小,就得建立数学模型,不然没有办法量化。原理的推导直接符号。但是计算量的分析来是数学公式来量化的。 另一种方法直接查看这种评测数据,得到业界的最新水平,一般纯代码的优化能够提高20%到10倍左右的提高。 超过了10倍的提高外在表现中就会有显著的变化。
优化的阶段¶
编译时优化,链接时优化,装载时优化,运行时优化,以及闲时优化
从算法最基本的入手¶
变量的分配就是意味内存的分配,如何使用cache与register. 一个最经典用法那就是SSA分析。
control flow analysis,data flow analysis,partial evaluation,static single assignment,global value numbering,liveness analysis. victorlization. 而这些的设计都要体现在LLVM 的IR中。
代码的实现就是一种资源的分配以及排兵部阵下棋一样,如何使用CPU等最基本的加减乘除等实现复杂的运算。加减乘除+与或非,以及基本指令。一套指令集就是一个完备集。
Control flow¶
CFG 的优化,主要是基于图论与拓扑,找到环路与边界。来进一步优化。 如何找到重复等价块,来实现函数,同时对于只有调用一次的函数。以及多次的代码是不是要把变成inline, 减少overhead. 以及由人写一个初始代码,然后算法进化最优代码结构,例如到底有多少需要重构的,模块化的。 然后再动优化,或者代码中加入一些宏指令,就像OPENACC那样来控制编译。
控制流图,每BB块,对应的原码块,可以看到依赖关系。并且有前向与后向的关系。 http://www.valleytalk.org/wp-content/uploads/2011/10/%E6%8E%A7%E5%88%B6%E6%B5%81%E5%88%86%E6%9E%90.pdf
循环¶
现在已经有一种数学模型,那就是多面体。可以采用数学的方式来进行优化。现有库有gcc用CLOOG。而LLVM,polly.来实现。 Polly可以用于各个阶段。 http://polly.llvm.org/docs/Architecture.html 在前端的话,优化后更接近原始代码,更容易理解,在后端可以充分利用其他优化的pass,但是没有可读性就比较差。
InstCombine¶
现在采用SMT理论来进行化简寻找等介合并来实现。现在最新的superoptimizer就是在这一块。
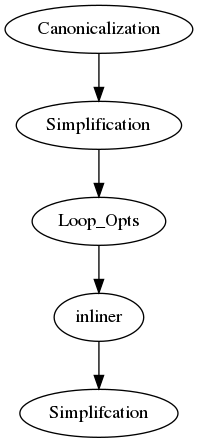
- Canonicalization
- Mem2Reg
- InstCombine
- CFGSimplify
- Scalar Simplifcation - InstCombine - CFGSimplify
- Simple Loop Opts - Loop Rotate - Loop Unswitch - Loop Delete - Loop Unroll
- Target Specialization - Loop Vectorization - Loop Distribution - SLP Vectorization
同时再加上不断的Inliner.
优化本身的问题¶
出错了,到底是 优化器错了,还是我的代码错了。 who knows. 把优化过程可视化来帮助人们来快速的troubleshot. 所以才有种troubleshot工具,
- bugpoint,快速的二分法信息收集与repro工具。
- llvm-diff 来对比, llvm structual diff, 主要是函数定义的不同。
- llvm-mc llvm machine code playground, 相当于各种平台的分析器。
- llvm-stress 可以filter,各种function的IR code.
- obj2yaml/yaml2obj 相当于机器码的直接修改了,再不用各种麻烦的解析工作了。
- llvm-symbolizer convert address into source code location
- FileCheck 一个类似于awk/sed,检查所有check pattern都满足。
如何利用profiling data来优化编译¶
代码指令的读取也是pipline也有cache,跳转会破坏预读取的数据。现在我们可以根据profiling的结果来进行编译。
如何在代码中利用profiling的数据里,这个数据接口是__builtin_expect来读取。
if (__builtin_expect (x,0))
foo ();
// -fprofile-arcs
原理 -fprofile-generate生成收集指令,并且生成*.gcda文件。 重新编译的时候 -fprofile-use 就会读取这些文件来生成条件语句。 -fprofile-arcs, -fprofile-values. -fbranch-probabilities,-fvpt,-funroll-loops, -fpeel-loops, -ftracer. http://stackoverflow.com/questions/13881292/gcc-profile-guided-optimization-pgoo 利用运行时信息来进行优化。如果这些信息存储在meta data中,这样LLVM中就可以实现自包含的优化,也就实现了自我的演化功能。
Link time optimization (LTO)¶
链接后,就可以看到程序的全貌了,这个时候是做全局分析最佳时机之一,例如函数间的调用。以及全局变量的分析。在clang -flto or -O4 就会起动LTO。
LLVM在链接时所做的最激进的优化莫过于DSA和APA。在DSA分析中,借助于LLVM比较充足的type information,在指针分析的基础上,可以构造出整个内存对象的连接关系图。然后对这个图进行分析,得到内存对象的连接模式,将连接比较紧密的结构对象,例如树、链表等结构体分配在自定义的一个连续分配的内存池中。这样可以少维护很多内存块,并且大大提高空间locality,相应的提高cache命中率。APA(Automatic Pool Allocation)能够将堆上分配的链接形式的结构体,分配在连续的内存池中,这种做法是通过将内存分配函数替换为自定义池分配函数实现的,示意图如下所示: 同时这个时候也可以内存引用计数有了一个大概的估计。 来优化结构体。
最常见的干法那就是只链接那用到代码与数据,如何到这一点,编译的时候加-ffunction-sections与-fdata-sections这样生一个函数与数据都会单独成section 然后链接的时候 ld –gc-sections就会把多余的section给删除了。
c++的template与重载都是链接时实现的,有两种方式,一种是利用虚表来查询,或者采用原来直接用同一个函数地址,只过前面添加一些offset量,然后用根据参数类型与变量与进行进一步的跳转。 每一个函数都有只有唯一个的地址,这一点是不变的。 template则需要编译的时候同时生成多个版本的函数,例如类型的变化。 但在表面多个函数实现是同一个函数,这个叫做IFC,Identical-instruction-comdat-folding. ld.gold –icf=safe就是干这个事情。 http://stackoverflow.com/questions/15168924/gcc-clang-merging-functions-with-identical-instructions-comdat-folding
unloop¶
并不是所有循环展开是有效的,例如下面这种展开就是无效的,并且逻辑也可能是错误的因为两者并非是等价的。 这也是优化难的原因,因为transfor有可能并非完全等价的,优化的另一个步骤就是验证结果的有效性。
for(i=0;i<10;++i){
if(something==3){
do_something;
}
else{
do_something_else;
}
unswitched loop(according to what I've been able to gather from the clang documentation(gcc's crap).
if(something=3){
for(i=0;i<10;++i){
do_something;
}
else{
for(i=0;i<10;++i){
do_something_else
}
}
如何用LLVM从编译分析重构代码¶
ClangTool 的使用教程。 https://kevinaboos.wordpress.com/2013/07/23/clang-tutorial-part-ii-libtooling-example/
Superoptimizer¶
如何用SMT的理论,在一个更大的范围内找到一个等价的更小的表达式。 目前采用的布尔可满足理论来做这个事情。 计算量的多少,在数学上不同方法,计算量是不一样的。如何找到等价表达式。数学上的化简。 从CPU的计算来看,那就是一大堆加减乘除再加逻辑运算。 如何从这堆的计算序列中进行化简,来简化计算量。 同时是不是可以利用群,环,域的知识进行简化计算。 LLVM让优化又回到了数学
函数参要¶
输入输出类型,以及需要时间与空间复杂度公式就够了。 在编译时会汇总每个函数摘要信息(procedure summary),附在LLVM IR中,在链接时就无需重新从源码中获取信息,直接使用函数摘要进行过程间分析即可。这种技术大大缩短了增量编译的时间。函数摘要一直是过程间分析的重点,因为这种技术在不过分影响精确性的前提下,大大提高静态分析的效率。我的本科毕设就是关于改写Clang以支持简单的基于函数摘要的静态分析,研究生毕设题目《基于函数摘要的过程间静态分析技术》。 http://scc.qibebt.cas.cn/docs/optimization/VTune(TM)%20User’s%20Guide/mergedProjects/analyzer_ec/CG_HH/About_Function_Summary.htm
IPO/CMO¶
过程间分析,分析跨module函数调用,然后根据hotpath的程度,来考虑是不是需要inline,inline就消除了函数边界。同时又添加了 上下文,同时就又可以指针引用的分析了。 而在传统的情况下,这些分析是需要LTO来做的。但是通过FDO(Feedback Directed Optimizations).从profiling data中收集数据直接来做IPO,这样可以避免compiling time增加的问题。 https://gcc.gnu.org/wiki/LightweightIpo#LIPO_-_Profile_Feedback_Based_Lightweight_IPO
Target code optimization¶
每一代的CPU都会一些新的特性,如何充分利用这些特性,就要有相应的编译器的支持,由于编译器与CPU的发布并不是同步的。 所以要想充分利用这些特性,还得现有的编译器做一些修改,有些只是一个编译选项的修改,有些需要从源代码处直接修改。
例如pld指令在ARM中的应用: http://stackoverflow.com/questions/16032202/how-to-use-pld-instruction-in-arm
重构¶
重构是基于代码的分析,同时对算法需求本身理解,还有实现的理解。 而二者搓合匹配就是重构的过程。 如何编译器能够读懂算法。 并且支持基本设计模式,而这些都在C#语言中实现了很多,LINQ的实现,就属于这种。编译器往下代码的优化,往上走那就是重构。 例如微软的 roslyn-ctp
依赖的分析¶
对于简单标量分析,都已经有很成熟的理论与方法,而复杂一些数组与结构体的依赖关系,就主要是下标分析,对于多维的结构下标分析就成了确定一个线性方程在满足一组线性不等式约束下是否有整数解。 线性方程的变量是循环索引变量,不等式约束由循环界产生。 对于一维数组只有一个方程须要测试。 当测试多维数组时,如果一个下标的循环索引不出现在其他的下标中我们称为这个下标的状态是可分的。
数据依赖问题是整数线性规则问题,因为它不可能一般的有效的解决方案。 例如GCD测试。
指针指向分析¶
指针指向分析是静态分析工作的一个重要课题。 也是各项优化技术和程序分析工作的基础。关键是精确度与性能的关系。 关争是也是建立有向图,进行还路检测。主要是分析各种赋值操作。 http://www.jos.org.cn/ch/reader/create_pdf.aspx?file_no=4025
对于指针分析,然后建立自动建立pooling 来提高局部性。
Point Aalias Rule¶
就是不同名字,但指的是同一块内存。这两个名字互称为alias. 并且对一段内存的使用频率如何统计出来,根据这个频率来进行内存结构的重新规划,从而最大化的利用寄存器与cache. 对于数组类型的分析主要是整数方程解来解决。而对于指针类型,比较随意,分析难度比较大。 目前大部分主要是采用基于类型分析,后台自己hook内存读写分配指令,自己来做进一步分析,最简单的那基于指令扫描,这样不管 控制流,例如循环与分析的情况。复杂就要考虑这些。 这个难点就在于算法复杂度很大,并且只有大的程序才需要这些优化。 找到一个算法复杂度很度,计算与精度是一对矛盾。
同时根据内存的使用情况,来设计一个好的垃圾回收机制,目前编译器对这一块还是比较弱的,LLVM已经开始在这一方面改进了。 http://llvm.org/docs/GarbageCollection.html#gcroot, 例如常规引用计数等等方式都已经实现只需要实现gc strategy.
对于这一块的研究,微软很多好的论文。 Points-to Analysis in Almost Linear Time
多级的cache的分析¶
每一级的cache的cost都是不一样的,如何根据cache的cost来自动进行内容的重排,要建立这样一个模型。例如circular queue,FIFO等等队列都是一种调度算法,效率如何是需要算法与物理模型之间的匹配,例如circule queue cache特别适合,多步之间临时数据的共享。
A Hybrid Circular Queue Method for Iterative Stencil Computations on GPUs¶
提出基于share memory与寄存器 circular queue,也就是异构的queue. 异构的queue不是简单的内容异构,还指实现介质异构。对于一维数组,主要是下标即指针分析。 而对于标量来说,那就是引用计算的分析。 而这些采用的是把数组分析转化为标量分析,从而设计出混合系统。 http://jcst.ict.ac.cn:8080/jcst/CN/10.1007/s11390-012-1206-3
Peephole的优化¶
如何去除没有必要的代码,来减少代码的长度,这就是peephole. 分析基础就是basic block. 什么是 basicBlock,也就是程序的片断只有一个入口与一个出口。 一般是程序的入口,跳转指令后的地址,call指令的地址。 结束的标志:程序的结束 ,call指令, JMP跳转指令。http://blog.csdn.net/zwh37333/article/details/2498195
那就是不断的用长指令来代替的指令,这也就是所谓的超级优化,这个问题应该说用图论更加容易来解决.并且在代码选择阶段更具也可以用。 并且采用了离线存储的方式来进行。
如何使用Polly在clang/opt中¶
http://polly.llvm.org/docs/UsingPollyWithClang.html 在 clang 中只在O3中支持。
并且直接在make 的CFLAGS中添加这些参数就可以了。
clang -O3 -mllvm -polly file.c
把编译的过程,可以通过 -mllvm把参数传递给 llvm.
clang 不需要invoke opt, clang与opt采用相同的LLVM infrastructure, opt只是优化器的wrapper. LLVM设计本身就是模块化的,opt只是一个exe的wrapper.
在loop中利用循环变量的单调性,直接利用相等代替<. 同时调整loop中scalar变量,尽可能减少其循环次数。 http://llvm.org/devmtg/2009-10/ScalarEvolutionAndLoopOptimization.pdf
归纳变量(Induction Variable,IV) 是指循环中每次增加或者减少固定数值或者与循环次数呈一定数学解析关系的变量。 分析这些可以形成CUDA的内核函数。 循环相当于差分方程。而如何找到一个通项公式, 而利用符号计算,并且加上符号计算工具包,并且加有向图结构的分析,就可以分析通项公式。 这样我可以循环计算变成了常量计算。
polly框架结构 http://polly.llvm.org/docs/Architecture.html#polly-in-the-llvm-pass-pipeline, 可以用在opt的各个阶段,在不同的阶段,效果各有不同。靠近前端,可读性好一些,放在后端优化的效果会更好,但是可读生差。
这里包括几个4方面: #. 数据依赖的分析 #. Dead code Elimination #. Scheduling #. Tiling Vectorization
把每一层的循环当做一个轴,三层的循环就是一个立方体,再多循环就是多面体。 通过循环的操作,来找到多面体中各个顶点之间关系。如果确实有局部性,与可分性。就可以并行处理。
是不是可以图像虑波问题,都可以polly来分进行分析优化。
对于特定的问题,可以模板化生成并行化代码,例如LoopGen可以生成C#循环代码: https://www.nuget.org/packages/LoopGen/
对于C优化的,直接读进C的循环,然后编译优化的算法。这种通过JIT编译+python是不是可以实现代码的自我演化。 http://web.cs.ucla.edu/~pouchet/software/pocc/
或者CLOOG用模板文件来生成循环代码。同时可以它生成解决一维线性方程整数解代码。并且可以作为整数约数解solver.
LLVM本身也有 Vectorization 的功能,一个是优化LOOP,另一个SLP把简单变量合并成array操作,特别是矩阵计算时 会特别有用,可充分利用cache的功能。 http://llvm.org/docs/Vectorizers.html
对于并行化的分析是难点,如果只是手工的并行化分析,效率太低,需要自动化的并行分析。 难点是依赖的分析,对于指针依赖分析其实也就是对链表的并行化分析,另外对数组的并行分析,其实就是分析坐标的依赖关系, 例如看是不是有有整数解依赖,以及单调性的判断也就是所谓的range test的方式。 并行调度的分析,例如CUDA的并行调度,就是利用thread来弥补数据存取的latency.
对于并行化的另一个难点,那就是自动优化数据结构,从而实现数据结构的重排,利用cache从而提高读写效率。 但是数据结构的重排可能会影响 代码的正确性。http://www.jos.org.cn/1000-9825/11/1268.pdf 这个难点如何充分利用多级的cache,主要是数据依赖的分析,以及变换,例如互换,偏斜,幺模变换来消除依赖。并且问题的规模以及循环苦址的轻微变化将导至预测cache性能差异极大。
对于并行化,一个重要应用,那就是对大量现有的legancy代码来进行并行化,虽然硬件已经有很好的模型,但是软件还没有很好的开发模型。 并且能够自适应各个层面的不同颗粒度的并行化。 所以出现一种算法描述语言,然后再算法描述语言来分析计算需求,最后再产生执行代码。 DiscoPoP: A Profiling Tool to Identify Parallelization Opportunities
https://software.intel.com/zh-cn/videos/episode-56-strip-mining-for-vectorization 这是一种直接把循环映射到指令集的并行,直接在代码层 利用硬件特性。但是这样的代码的局限性很大,只适用于特定的硬件。所以也要实现编程语言的层次化,实现一种通用的算法描述语言。 其本质就在于需要分配多少数据在cache里。这里是利用标量变量的方法来实现的。在写代码的时候,复用同一个变量,相当于复用计存器了。 所以在指令缩减的时候,可以a=b+c d =a+2,其实直接使用a=b+c+2,而减少一个d变量
在实现并行的时候,就是需要找到并行部分,这样就需要分块,就像SVM一样,分快可能是园型,多边型,而不是简单的矩形。区别就在于循环的那个变量 是如何增长的,只是简单的线性的,那就是矩阵,换一种增长方式就是另一种分块方法。The Promises of Hybrid Hexagonal/Classical Tiling for GPU 就采用六边型的分类方法,其实是ogl中,strip就是为了采用各种存取方法来加快。
对于现有代码加速,就是读取源码分析出并行依赖,然后直接转换成并行代码。
对于 stencil compute 有大量 stencil compiler 可以用。
对于分块,有切割分片,重叠分片,金字塔分片。在分片的时候,IO/Compute 比会影响分片的策略。 另一个方法,实现DSL语言生成并行代码,一般用函数式语言等高阶语言来描述算法,然后再生成并行代码。 例如http://compilers.cs.uni-saarland.de/papers/ppl14_web.pdf 在Rust里实现了一个Impala来这样的事情。所以这个事情,部分求值就非常重要了。
分块技术¶
固定分块技术¶
是需要通过重新编译来来改分块的大小。
多面体扫描技术,也就是说每一层的循环都是一个面,循环体代表了各种约束。
多面体的扫描做法,其实就是化简的过程,你可以给出一种表达式,然后利用化简出更加简单的表达。
其实也就是打到这些点,相当于重新路由这些点。找到最佳路径。由于路组的下标一般是整数,一般也就是基于整数的多面体抽取。
isl :An Integer Set Library for the Polyhedral Model
例如一个if 就代表不等式的约束。
每一个迭代点就是一个顶点,至于那些顶点如何连接的,边就由循环体的计算来决定了,那些逻辑运算与算术运算那就是边的线性质。
最简单的那线性了。每一种运算就代连接方式,现在算法模型的不同在于对不同的运算的支持。现在对于各种运算符并不是完全支持。
并且由于各种运算有access relation,以及数据依赖。
例如对于这种复杂的 A[i+1+in2[i]] 可能是太复杂了,就无法分析。三大分析
#. access relations,iteration domains, schedules.
http://www.grosser.es/publications/grosser-2012–Polyhedral-Extraction-Tool–IMPACT.pdf
WRaP-IT是把一个基于Open64 loop表示方式转换 多面体模型。 http://xueshu.baidu.com/s?wd=paperuri:(b9d56c50f7ec1e591af804388d0543a4)&filter=sc_long_sign&sc_ks_para=q%3DSemi-Automatic+Composition+of+Loop+Transformations+for+Deep+Parallelism+and+Memory+Hierarchies&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=17522034925718936250
难点在于如何分块的问题,边界框,相当于平行四边形,但是可能会有冗余的。 如何得到合适的分块方法。同时还要确定的每一层循环的计算要求。
也就是一个线性分间的分块与遍历方法,多级分块,对应着多级循环。 结合新存储架构和应用数据规模特点,全面精准地描述多核共享cache架构上数据访存行为,提供更加有效,简洁,紧溱的线线性空间多面体变换理论模型,在时空维度采用更灵活的混合分块策略,利用粗细粒度结合高并行度开发硬件资源高效的计算能力,针对优秀的代码生成器在代码质量,分块开销,可扩展性等方面进行相应的优化提升,同时构建分块代码性能的评估模型
Parameterized tiled loops for free 参数化的分块,其实就是ogl的shader如何写的问题,uniform的参数就是相当于并行化分块时的常量,但是在运行时每一次都是要变化的。 在ogl的buffer的结构分配,就是一个调整tiled的过程。inset,outset两种,相当于参数化列表,例如小波变换,2x2大小,计算体,128x128大小计算,根据需要选择最近那一种分配方式,还有一种完全参数方式,由于分块增加循环的overhead,这样通过区分full tiled,partial tile,来进行在full tile 中减少不必要checker从而减小overhead.
FME 分块算法是指数级运算量,效率太低。
重用距离¶
程序是否具有较好的局部特征体现在数据重用时是否命中cache或寄存器。 重用距离(resue distance) 用于描述这一重要特征。 重用距离越短,cache 中相关数据重用的机会就大。
采用FPGA直接实现神经网络是最高效与直观的方式,因为直接构造计算。但是对FPGA容量要求也不会太低吧。如何创建低计算量的算法。
但是成本也不是很低,例如http://cadlab.cs.ucla.edu/~cong/slides/HALO15_keynote.pdf用到VC709开发版就5000$,这种高速版。 120M的内存。90W的功率,
https://www.ll.mit.edu/HPEC/agendas/proc07/Day2/12_Dillon_Poster.pdf 可以直接用python来实现从算法到HDL生成。 MyHDL 用python来写HDL.
http://www.dilloneng.com/ 最好用FFT IP Core. 现在基本可以用各种语言写HDL,例如BSV用haskwell来写,JHDL用java来写,CHISEL用Scalar来写。Matlab的simulink 也是可以的。 同时用C/C++来转换成VHDL,github上都有现成的项目例如https://github.com/udif/ctoverilog 并且ALTERA 已经通过LLVM把opencl转换成FPGA代码了。http://llvm.org/devmtg/2014-10/Slides/Baker-CustomHardwareStateMachines.pdf
现在对于HLS,也有LLVM的支持了。http://llvm.org/devmtg/2010-11/Rotem-CToVerilog.pdf 把LLVM IR当做算法最终描述语言。例如 http://portablecl.org/ CPC 开发一种 Portable Computing Language.
另外还有一个基于LLVM c2hdl的开源编译器`Trident Compiler <https://sourceforge.net/projects/trident/>`_ 但是已经有3年没有人更新了。
如果还做独立的SOC,还得做一些简单kernel来做一些管理,当然这个可以用NiosII软核来实现。
In a CPU, the program is mapped to a fixed architecture In an FPGA, there is NO fixed architecture The program defines the architecture Instead of the architecture constraining the program, the program is constrained by the available resources
TCE¶
对于TCE的安装,使用的LLVM是需要打补丁的,通过安装的LLVM是不能的。 可以通过 #. tools/scripts/try-install-llvm <llvm_install_dir> #. ./configure –with-llvm=<llvm_install_dir> //not use system llvm
http://tce.cs.tut.fi/tutorial_files/tce_tutorials.tar.gz
默认它会把安装在 /usr/local/lib但是直接用可能找不到库。
工作流程:http://tce.cs.tut.fi/user_manual/TCE/node7.html. #. 先纯软件的实现。 #. 相当于porting 到一个TTA的processor上。 #. 然后就是优化了。
C->bitcode->TTA processor code->优化,生成代码适配。并生成对应image文件。
性能优化最终极的目标那就是能耗比。而只有这样才能实现从上到下全局优化。 而之前的是扩张占用资源。