厚积薄发¶
算法基础¶
算法分析¶
算法缺失一个公共的表达方法,很难有一个通用衡量,但是LLVM IR却可以补充这个空白。 可以充分利用 LLVM 的分析功能来实现算法的精确分析。 由于IR是通用的,并且IR指令对应到机器执行时间也都是固这的。 所以完全可以拿到这样一样计算模型啊。 差不多精确的知道其需要执行多少时间。 并且用一个树形依赖来计算出来。 所以生一个函数复杂度是能够精确的计算的。 这样解决了采样的精度不足的问题,指令值收集速度,需要的资源太多,太慢的问题。 算法的时间复杂度和空间复杂度-总结
算法的维度计算¶
时间复杂度并不是表示一个程序解决问题需要花多少时间,而是当问题规模扩大后,程序需要的时间长度增长得有多快。 http://www.matrix67.com/blog/archives/105
the design of a program is rooted in the layout of its data. The data structures don’t define every detail. but they do shape the overall solution.
http://blog.csdn.net/zolalad/article/details/11848739, 常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!) NP问题,就是基于复杂的度来说的。
O(1)表示基本语言的执行次数是一个常数,一般来说,只要算法中不存在循环语句,其时间复杂度就是O(1). 其中 O(log2^n) O(n),O(nlog2n),O(n2)O(n3)称为多项式时间。
而O(2^n)与0(n!)称为指数时间,计算机科学家普遍认为多项式时间复杂度的算法是有效算法,称为P(Polynomial)类问题,而后指数时间复杂的算法称为NP(Non-Deterministic Polynomial 非确定多项式) 问题。
一般来说多项式级的复杂度是可以接受的,很多问题都有多项式级的解——也就是说,这样的问题,对于一个规模是n的输入,在n^k的时间内得到结果,称为P问题。有些问题要复杂些,没有多项式时间的解,但是可以在多项式时间里验证某个猜测是不是正确。比如问4294967297是不是质数?如果要直接入手的话,那么要把小于4294967297的平方根的所有素数都拿出来,看看能不能整除。还好欧拉告诉我们,这个数等于641和6700417的乘积,不是素数,很好验证的,顺便麻烦转告费马他的猜想不成立。大数分解、Hamilton回路之类的问题,都是可以多项式时间内验证一个“解”是否正确,这类问题叫做NP问题
树¶
二叉树, 红叉树
树形结构深度不平衡,导致搜索的效率不稳定,所以为提高效率人们开始研究平衡二叉树,而红黑树就是平衡树的一种。使搜索的效率趋于稳定。
变量->数组->链表->树->图->拓扑
树形结构是嵌套结构的一种,嵌套结构其实就是像分形无穷,其实数据结构来说,链表就是表示各种各样的嵌套结构。对应的语言模式那就是递归。
递归函数可以全局变量来记录深度,可以用函数内部的static变量来记录,或也就是所谓的静态变量。 总之这一段空间,就看你怎么样用与规划分配了。
树型结构是最常见的数据结构,例如文档目录,各种协义,以及html,xml等等都是树型结构。遍历方法分为深度优先,还是广度优先。 所以在扁历生成一个列表的序列会大有不同。同时对于各种文档的解析来实现。 也都是从上到下,从前往后。采用的递归式解析。 一般用状态机+ vistor 模式来进行解析。
class Node:
def __init__(self):
self.parent
self.children = []
def tranverse(self):
for child,in self.children:
tranverse(child)
def parse(self):
Root = Node(none)
for line in readline():
state = state(line)
newRoot = New Node
NewRoot.parent = Root
Root.children.append(NewBoot)
硬件到逻辑变量的对应¶
这个是基础,基本的硬件单位有bit,byte,WORD,DWORD。 逻辑单位有各种int, short int,long int, 各种float,32bit float以及64bit 的float. 以及char,string 等等。
然后是各种复杂逻辑结构的表示。
array,vector,list,matrix,tuple,map/dict等等。
再往后复杂的tree,图,class之间是可以建立的关系的。
结构化对比的实现¶
最简单一种遍历,从一个之中,从查找另一个。 效率是n*n.
再好的一点,如果有序的话,就可以不回头。也就是最常匹配算法。就像现在diff算法一样。
但是如果再有一些结构的话,可以把key值或者路径还是最常匹配来得。具体到每一个最具体的项的再用简单的方法。 关键是key map成list是不是有重复的,顺序无关的。这些会影响算法如何实现。
如何进行tree-based structured diff.
例如 http://diffxml.sourceforge.net/
另外一种做法,那是把结构化的变成 linebased. 这就需要先把结构flat化。 例如https://en.wikipedia.org/wiki/Canonical_XML。就是这样的一种。也可以叫做正交化。 现在已经有做的成熟的商业化工具diffDog. http://www.altova.com/diffdog/xml-diff.html
http://archiv.infsec.ethz.ch/education/projects/archive/XMLDiffSlides.pdf.
结构化的对比,难点是检测移动。
另外一种那就是tree2tree的对比算法. https://www.ietf.org/rfc/rfc2803.txt DomHash的算法。
编辑距离的计算,可以采用路径+ node本身hash等等。需要两个信息。 一个是自身的信息。另外一个那就是它的位置移动。 编辑距离同时还可以看到一个人在一个系统中移动轨迹。
X-Diff: An Effective Change Detection Algorithm for XML Documents. http://www.inf.unibz.it/~nutt/Teaching/XMLDM1112/XMLDM1112Coursework/WangEtAl-ICDE2003.pdf node signature + hash的做法。 A Semantical Change Detection Algorithm for XML http://www.inf.ufpr.br/carmem/pub/seke07.pdf,这个方法比较接近自己的算法。
基于xml的一种混合结构化数据对比方法。
看来我的这个东东也是可以发表的。
可以采用样式表的方法,决定对比方法。 看一下html中样式表是如何添加的。就可以实现了。或者采用xpath的方式。
KFIFO¶
linux kernel是一个大宝藏,如果想找各种实现,去kernel的source tree 里找一找吧。 例如ring buffer一个实现。ring buffer 实现的原点,如何实现下标的循环,但是由于自计算机整数的溢出来实现,再加取模计算,再把大小变成2的n次幂, 这样取模就又变成了取与计算。 http://www.cnblogs.com/Anker/p/3481373.html
quicksort¶
这个是其实分段排序方法,与二分法是对应的。如果上千万排序怎么的办。 直接发分段,然后再逐段的拼接呢。 中间再字符串搜索功能。
Practice.of.Programming at Page 46.
基本结构对比¶
初级结构¶
int, float, string,enum
中级结构¶
array,list,hash,tree
#.array, 固定,但是存储效率高,采用动态的数据,可能会引起大量的数据搬运,所以初始空间的设置,以及增长方式是要考虑的重点。 #. list 最灵活,但是只能顺序用link来存取,所有二分法,排序算法等等基本上没有什么效果,因为其只能知道与其相关的信息。
对其profiling就要操作的效率。例如每一个查询,修改花了多久。 例如在STL的时候,例如把deque, 换成list的效率的明显变化。
- hash 把结合array,list的优点,也是优化空间最大的地方,就像一个矩形,面积恒定。但是如何分配长宽才能达到高效。而决定长宽分配是与存储对象本身的特性以及hash函数 共同决定的。使其存储上更像array. 所以对其性能分析,就要查看其结构利用率。
- tree 结合list,array,使其更像list,但是操作效率尽可能像array. 因为在树的排序,就可以用二叉树,平衡树,来加速寻找的过程。 用于分树的key,相当于array中index.
高级结构¶
- struct, 可以根据需求来定制,但是结构固定,也是为什么python的对象中固定元数据部分要struct表示。而动态部分用class来表示。
- 同时也可以把相应的操作函数相联起来,这个是比中级结构更强一些点,
- class, 添加了数据本身的存取进行权限定义,另外通过继承可以添加,重写原来的struct.
而所有的这些变化点都是根据需要来的。
当把你的问题搞清楚了,采取的数据结构也搞清楚了。这个时候采用什么样语言与库就一目了然了。
队列¶
Queue, 先入先出的队列, LioQueue,PriorityQueue,Qeueue,deque,heapq. 以及 namedtuple, Counter,OrderedDict,defaultDict.
粒子群算法¶
都是GA的一种,它简化一些,去掉了交叉与变异。 模拟鸟群找食的过程。它根据自己当前最优值与群体中最优值来进行更新。
蚁群算法¶
蚁群算法,还是根据蚁群,每一个蚂蚁也向外传播信息。每一个蚂蚁根据自身的精况来决定是否接受全局的信息。 通过触角,其实就是人类交流中的局部信息,完成一个任务 传递是相互遇见的频率,这个是代表什么? 不同的激活个数,导致大脑的差异,这里就是提取信息的不同 在环境密集情况下,如果探测到危险就停止。 http://open.163.com/movie/2015/1/6/H/MAFCPCJCV_MAFDA5K6H.html 计算概率密度,通过局部的计算。我想这可能是新的算法
计算模型¶
- reduce 模式
- scan 模式
- map 模式
- count_if 模式
- match_if 模式
- filter
- group
- 约束求解,z3等等,并且在excel中也带有大量的solver,其实不需要从零开始写。
执行的模型¶
在需要并行执行的操作提供了,进程,线程,协程的基本模型。
当然在使用协程是最近才提供出来,可以在编程语言内部支持,相对于线程来不需要那些各种数据的锁机制。
同时实现异步的操作,现在async,await,yield,yield from的等等的支持,在实现各种复杂的建模的时候就会特别方便。
例如javascript系统event的机制实现了多进程打进了自己的语言机制.
而python 现在也支持async,await,yield等支持并行。
这样对于这个系统比较完备了。
进程通信¶
从课本上讲的 socket,信号量机制。 到后面JSON,以及 protobuf , apache thrift socket 由简单的 点对点到 n:n 的 zeromq , 这个由我想起了expect 实现的n:n 的通信。
quick start 给了一非常好玩的入门。
经过几分钟试用。Racket 集成了传统语言与符号语言的优势。 符号语言的特点那就是非常的简练。把替换用到极致有M4那种功效,但时具有传统语言作用范围的概念,弥补了m4这个不足。 继承了 lisp 与scheme 简单,直接用函数语言的() 来搞定一切。 以及看函数式编程比较别扭,现在是越看越顺了。 并且用起来也非常的简练。
并且还有对象,列表,map等等。
Racket 可以用直接处理图,并且有人拿来画图与做动画。
用racket 当做脚本使用 http://docs.racket-lang.org/guide/intro.html#%28tech._repl%29 。
当做系统脚本就得像bash那样的的清爽。同时具有python的强大。现在看来racket还是不错的。 这里有全面的 racket-lang reference
代码最简单的方式那就是像bash一样,然后可以对输入与输出进行控制,并用管道,并且语法也要简单。这个正是函数式编程要达到目的。
(cmd para) 不正是bash的语法格式吗,并且直接用()执行一次替换,bash也正是这么来的。
并且直接直接系统命令,并且接近bash一样的简练。 http://rosettacode.org/wiki/Execute_a_System_Command#Racket
#lang racket
(system "ls")
;; capture output
(string-split (with-output-to-string (λ() (system "ls"))) "\n")
计算机程序的构造和解释¶
通过这本书真正明白计算的构造过程,并且只要支持局部或者全局的静态变量,就可以实现各种复杂的计算。
可以用let 实现不断的替换,从而实现电路的模拟。函数具有内部的状态,可以实现各种复杂的模拟,这个内部状态可以用python yield来实现。
parallel-execute过程。直接实现函数体的并行执行。
关键的就是这种符号替换执行。这个是难点是如何实现的。代码执行像数学公式一样。
对于现实仿真的问题,那就是如实现tick函数,同时也要保持依赖的问题。 后台调用的是 phyx car 来模拟的, 采用最简单的迭代做法,每一个基本过程,然后不断迭代的过程。 就是每一个tick函数如何写的问题。 可以用recket 把迭代与传递链结合起来。
这也就是微分与与数值计算的模型。
racket的发展史。 https://www.zhihu.com/question/22785256
列表的模式匹配¶
原来没有明白,scheme中,cd,cdr用途,也就是头:余下的。 就是各种模式匹配的基本模式啊。
curry 理论¶
传统函数理论,就是参数的处理,但是如何curry的处理,函数输入可以是无限的。就像一个递归一样。 这样就把函数输入处理统一化了。其背后那就是个lambda理论。
程序的三大基础¶
以及其特珠性,
变量,这里的变量就是符号,各种符号定义。 只是基本原语不一样。
所以这个语言基础,那就是lambda calculus,就是不断的替换,直到原语为止。 数据结构也就是符号 以及符号的集合,也就是列表两种。
其语法解释就像shell一样,shell 以行为单位,然后以空格作为分隔符。并且第一个符号为命令。 其余的为参数。关键是什么时候发生替换。
在racket 中用单引号表示符号,不对其替换,只有let 中才对符号进行替换。
在clips中符号定义很宽泛,用任意可以打算ASCII码, 作为符号,而非打印字符找了几个当做定界符。 同时拿;来当comments,
符号语言与一般语言的区别,那就在于多一种符号的定义。 而在Clips中可以用?,$?开头当做变量。
并且也匹配的原语,匹配单个符号,多个符号。不同语言里不是不同的。 在 clips中,?是单个符号,而在$?是多个符号。
ruler,有自己的属性,以及前置条件,以及推导条件。 然后根据前置条件来决定下一步是谁。 不确的因素就是下一个要问的问题。
函数度编程特点¶
- 所有的过程都是函数,并且严格地区输入与输出。
- 没有变量或赋值 ,变量被参数替代
- 没有循环(递归代替)
- 函数的值只取于它的参数的值与求得参数值先后或者调用函数的路径我关。
- 函数是一类值
introduction¶
debug and profiling¶
ghci 是可以直接以 :break line 类似于vim的命令直接在解释器下断点。 并且是集成一起的。 ghci-debugger . profiling 见此 haskell profiling .
同时还得安装 apt-get install ghc-dynamic ghc-prof
库的管理¶
cabal 类似于 perl 的cpan,以及python的pip.
映射与函数的表示¶
haskell是与数学最接近的编程语言,haskell可以求解哪些隐式函数。它应该是用笛卡尔基再加过虑来实现的。 并且是从数理的脚度来进编程的。
Monad是从另一个角度来分函数进行区分,那就是有限响应与无限响应滤波器,那就是有没有全局变量在函数内部,所谓纯虚函数,就是我们平时编程中最常见的函数,输出只与输入有关。没有记忆状态。而haskell把这个出来进行深入区分,就提出Monad的机制 http://zhuoqiang.me/what-is-monad.html。
如何快速读haskell 代码¶
See also¶
- realwordHaskell 很精典的书
- Here are a few Sudoku solvers coded up in Haskell.
- JSON解释器的实现
- 漫谈Haskell 之零 一入哈门深似海从此节操是路人
- 对 haskell 与 monad 的理解
- Introduction to IO(介绍Haskell的IO)
- Monad 最简介绍
- Haskell/理解monads
- 准全息系统论与智能计算机
- 潜科学网站
- ` 勾股定理; 毕达哥拉斯定理; 毕氏定理 <http://bookjovi.iteye.com/blog/1457434>`_ 如何求勾股数
- haskell 对于矩阵的运算 haskell 强项是公式表达
- Haskell与Python中的一些概念,若有所悟
- 在python 中调用haskell.
- Languages best suited for scientific computing?
- Haskell与范畴论
- Theorem provers 公式验证库
- HLearn: A Machine Learning Library for Haskell 研究一下这个
- AI haskell wiki
- scala-vs-haskell-vs-python
- Haskell for AI?
- -project-euler-c-vs-python-vs-erlang-vs-haskell
Thinking¶
Higher Order Functions 这个其实不是什么新东西,在perl里都有例如sort 排序,你可以使用各种方法传递给它。这个要用函数指针,并且能够动态生成代码最好。但是在这里支持会更好。在这里要习惯,函数内部调用函数。 函数可以相互组合。
更加接近数学定义。用Haskell摆弄函数确实就像用Perl摆弄字符串那么简单。特别适合公式的推导。
– Main.GangweiLi - 19 Sep 2013
偏函数 可以预置一些参数的参数。
– Main.GangweiLi - 19 Sep 2013
lazy evaluate 这样能够把多层的循环压在一层去实现。并且采用了值不变的方式。
– Main.GangweiLi - 20 Sep 2013
前缀,中缀,后缀 表达式 以前没有注意它,在hackell中,这几种是可以转换的,一般函数调用采用是前缀表达,操作符采用的中缀表达,那后缀在什么时候用呢
– Main.GangweiLi - 20 Sep 2013
表表操作 haskell的list类似于tcl中列表,可以嵌套,但是操作符不一样。
– Main.GangweiLi - 20 Sep 2013
产生列表 是不是可以集合,例如数列产生会很方便,但是它的列表可是无限长的,这更加适合公式的证明了。你可以用cycle,repeat等等来得到。
– Main.GangweiLi - 20 Sep 2013
函数式编程的一般思路 先取一个初始的集合并将其变形,执行过滤条件,最终取得正确的结果
– Main.GangweiLi - 20 Sep 2013
利用模式匹配来取代switch。
– Main.GangweiLi - 20 Sep 2013
特殊变量_类似于perl 的$_.
– Main.GangweiLi - 20 Sep 2013
*函数*本质就是种映射,这个ghci中最能体现,你可以指定其定义域与值域,以及这个这个映谢,函数的原型就这个。
– Main.GangweiLi - 21 Sep 2013
同时也需要注意算法定义的动词为”是”什么而非”做”这个,”做”那个,再”做”那个…这便是函数式编程之美!
– Main.GangweiLi - 21 Sep 2013
二分法更加普适化的做法就是快速排序法,不断求不动点。
– Main.GangweiLi - 21 Sep 2013
使用递归来解决问题时应当先考虑递归会在什么样的条件下不可用, 然后再找出它的边界条件和单位元, 考虑参数应该在何时切开(如对List使用模式匹配), 以及在何处执行递归.
– Main.GangweiLi - 21 Sep 2013
%RED%高阶函数部分求值,还是没有讲明白,是不是类似于求偏导时,把别的值当做常量%ENDCOLOR%
– Main.GangweiLi - 21 Sep 2013
map,filter 与perl中map,grep是一样的,这样的东西对于集合运算不是非常的方便,另如图形的形态学操作,是不是可以利用map与filter来操作。
– Main.GangweiLi - 21 Sep 2013
以前我们函数调用,是从内到外,而haskell是从外到内的。 例如求找出所有小于10000的奇数的平方和。sum (takeWhile (<10000) (filter odd (map (^2) [1..]))) 这个是利用惰性求值的特性。来实现的。
– Main.GangweiLi - 21 Sep 2013
fold 的功能就是map与reduce中reduce的功能。不过它分从左还是从右。不过其更方便的是它还有scan这个功能更加方面。做无限长滤波器一样。特别是我们想知道fold的过程的时候,就可以用scan.
循环看做是linear Recurrences,看成数列的计算。不同的你要是数据求和,还是数据相加不变形。 从数列的角度来看循环就变容易很多。
利用C++的模板,很容易数学试的计算,而解决纠结于实现细节。 – Main.GangweiLi - 21 Sep 2013
*$ 函数调用符*它产生的效果是右结合,而一般的函数调用左结合。右结合有什么好处呢,那是在复用函数就会很方便。同时也可以产生python中那种不断调用的 “.”组合了。
– Main.GangweiLi - 21 Sep 2013
模块 更多的类似于perl的语法,并且类与结构体的定义。但是就是没有OO了。另外还有C中typedef的功能。
– Main.GangweiLi - 21 Sep 2013
程序验证与证明,haskell还可以做这个事情。看来把原来的东东都关联起来了。
– Main.GangweiLi - 21 Sep 2013
范畴论,type theory是什么。 domain theory.
Element of programming¶
程序的设计就是一种迭代过程,研究有用的问题,发现处理它们的高效的算法,精炼出算法背后的概念,再讲这些概念和算法组织为完满协调的数学理论
这本书里讲差不多就是C++的haskwell的实现,从数学理论角度来理计算语言。
value就是内存中一段01序列,而object只决定了如何解决这种序列,每一个变量类型与数据结构都是对这一段01序列的解读。 并且完备性,看来只有bool类型是完备的。其他只是数学表达子集,例如整型等等。
对于函数过程可以分为四类
- 只是简单输入与输出的关系。输出只与输入相关。
- Local state, 局部的临时变量。
Associativity 操作,min,max,conjunction,disjuntion,set,union,set intersection. #. Global state,用到的一些全局变量 #. own state 只有函数过程自己用到变量,例如函数中static变量。
另外把函数输入当做定义域,而把输出当做值域。 通过这些东东研究,可以函数过程本身做些验证。可以离散数据表达式来表达函数。这样就可以程序验证的方式 来方便验证了。例如任一,存在等等条件。
函数的化简,就变成寻找最短路径的问题。从定义域到值域的一种最简单路径。
递归¶
递归的overhead太高,我把他变成尾递归,这样变成A^n=A*A^(n-1)的问题。这样可以变成循环的问题。 递归本质是之间通过函数输入输出,动态的传递参数。
优化计算¶
在本质是数学的表达式的切换,恒等变型就变成方程的推导,变的适合硬件发展。所以在做算法优化的时候,一种就是恒等变型。 例如转化二进制操作。例如移位。 先从数学上解释。然后再到硬件实现。
对于近似计算,不是随便的把9或7变成8完了。而是极数或者变换域的方式在减少计算量在保证误差的情况下。 来减少计算量,例如时域与频域的变换等。
把计算模型->数学模型->计算模型
例如用卷积来进行子串搜索。
iterator¶
就是把各种遍历非装到一个接口下。只需要根据iterator这个接口来操作,而不用担心下层的实现。这种是基于一维地址的,多维的方法那就是坐标了。
例如对于树的两种遍历,基于只有next的函数的区别了。或者successor(i)的区别。
这种遍历是哪一种呢: #. readable range #. increasing range #. Forward range #. indexed Iterator #. Bidrectional iterator #. Random-Access Iterator
Copying¶
解决是信息传递的问题。
rearrrange¶
重排的,或者过虑的机制。以及变形的操作。
Composite objects¶
组合问题,有静态与动态之分。
同时解决动态序列的分配方式,以及内存的分配方式。 而不结构类型,就像一个窗口来改变查看内存的方式。以及用castXXX等等来切换这个窗口。
序的概念¶
通过在集合的序的重要性。https://en.wikipedia.org/wiki/Total_order
模式匹配¶
一个列表的模式匹配,来自然的实现语法分析。另一个那就是多态。来实现运行的状态转移,也就解了goto的用途。
介绍¶
Qt 最主要那就是跨平台。其扩平台性主要是由于自身休息的实现都是元编程与c++自身的语法实现的。
Qt 在windows一下基于WindowsAPI,只是对WindowsAPI进行一层封装。因为windows下GUI编程都是如此。 所以都绕不过去WinProc的,其实有桌面控制都是一个矩形加点图片,然后一个消息的处理。QT也不例外。 也是对其一层封装。
从本质是QT的GUI与message处理是分开的。
GUI -> Widows GUI -> Window message -> QT message process.
跨平台¶
对于 .so的调用,无非是加载库,得到函数地址,然后预声明一个函数,然后释放库。
对于Windows:
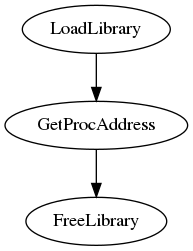
对于linux:
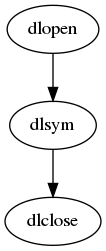
另外一个问题,那就是调用约定的问题。 qtlibrary_XX.cpp 正是通过添加一层,来调用不同平台的 .so 函数。例如三套相同接口,以三个文件命名。 然后通过宝预编译来加载不同的文件从而保证调用的一致性。
并不是各个平台库都是OOP或者怎么样的,只是人类的OOP处理一下,按照OOP的方式来处理了。 再加上程序的透明性,就更加隐藏这一问题。
slot¶
一般现在GUI都会用到多线程,不然就有可能每一步非常的慢。一般都是采用并行的操作方法。
所谓的slot,signal,就是宏定义相当于元编程实现了消息队列,再应用程序Winpro得到系统的消息处理之后。 然后我们内部这个消息队列。 并且通过队列实现了跨线程的调用。 利用宏来实现不同于OOP对象树形结构元编程 在各个个大平台上都可以看到。 从表面上看就像callback一样,只不过,需要元编程,自己建立一个mapping的链表。 http://blog.csdn.net/m6830098/article/details/13058459, 而所有 signal, slot都是被处理掉了。
同时通过元编程实现背后的一套逻辑。
但是避免了MFC那种采用宏定义的方式。当然背后也是这些东东了。 这个有点类似于unreal中实现的机制了。connect,disconnect,来维护这个链表。
开发流程¶
- 最简单的GUI,还是可以延用标准c的开发,加入头文件,链接库,编译链接就行了。
- 如果对QT类进行扩展,在标准c的编译之前,还需要利用Moc对源代码进行扫描一遍生成QObject等等一堆东东生成代码。
- 对于QTDesigner 生成变量,则还需要用uic 为 xml.ui 生成对应的头文件。
- QML的开发,如果没有扩展,再标准的c编译之前,还需要额外链接一个带有QObject的Javascript的引擎。
- mobile 的开发,把main变成.so 并把所需要 QT .so都放在本地,其实这种干法也就是回到了现在Windows下软件开发的模式。
hellworld¶
#incude <QtCore>
int main( void) {
QApplication a(args,argv);
QLabel label = new label();
label.text = "helloWorld";
label.show();
a.exec();
}
Compile Sample¶
install QTCreator, install Android Plugin
Chose platform, and slect Plannet Example
configure projects.
which toolchain, and and api.
Projects>ManageKits>Add
- Device type
- Compiler
- Debugger
- gdb server
- QT version
build steps¶
shadow build¶
就是同一份源码编译到不同平台。
新建一个目录,然后用configure.exe -xplatform 指定平台来进行编译。 http://doc.qt.io/qt-5/shadow.html
No shadow: F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsplanets shadow: F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsbuild-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug
- qmake qmake.exe F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsplanetsplanets.pro -r -spec android-g++ "CONFIG+=debug" "CONFIG+=declarative_debug" "CONFIG+=qml_debug"
- make mingw32-make.exe in F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsbuild-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug
- package Android build sdk: android-23. QtDevelopment: Bundle Qt library in APK use androiddeployqt.exe generate a package.
Qmake tutorial 是支持VS project,就像 gnu autoconf,以及CMAKE的功能一样。
通过compile log可以快速得到编译脚本。
F:\Qt5\5.5\android_armv7\bin\qmake.exe" F:\Qt5\Examples\Qt-5.5\canvas3d\canvas3d\threejs\planets\planets.pro -r -spec android-g++ "CONFIG+=debug" "CONFIG+=declarative_debug" "CONFIG+=qml_debug"
"F:\Qt5\Tools\mingw492_32\bin\mingw32-make.exe" -C F:\Qt5\Examples\Qt-5.5\canvas3d\canvas3d\threejs\build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug`
"F:\Qt5\5.5\android_armv7\bin\androiddeployqt.exe" --input F:/Qt5/Examples/Qt-5.5/canvas3d/canvas3d/threejs/build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug/android-libplanets.so-deployment-settings.json --output F:/Qt5/Examples/Qt-5.5/canvas3d/canvas3d/threejs/build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug/android-build --deployment bundled --android-platform android-23 --jdk C:/NVPACK/jdk1.7.0_71 --verbose --ant C:/NVPACK/apache-ant-1.8.2/bin/ant.bat
How to setup Nsight Tegra with Qt¶
Download QtCreator from http://www.qt.io/download/
Intall it to <your QT path>. for example
F:\Qt5Install android plugin
- Open Maintain tool by startMenu>Qt>Qt MaintennanceTool
- Select Add or remove
- Select Qt component you want. for example( Qt>Qt 5.4>Android armv7).
- Click next until finish.
Get an android samples
- Open Qt Creator
- Click examples
- select right platform and the sample name
- we use (Qt 5.5.1 for android armv7, sample name: planet)
- double click open the sample
get build cmd from the project configuration.
qmake
qmake.exe F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsplanetsplanets.pro -r -spec android-g++ "CONFIG+=debug" "CONFIG+=declarative_debug" "CONFIG+=qml_debug"
make
mingw32-make.exe -C F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsbuild-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug
package
- Android build sdk: android-23.
- QtDevelopment: Bundle Qt library in APK
- Use androiddeployqt.exe generate a package.
"F:Qt55.5android_armv7binandroiddeployqt.exe" --input F:/Qt5/Examples/Qt-5.5/canvas3d/canvas3d/threejs/build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug/android-libplanets.so-deployment-settings.json --output F:/Qt5/Examples/Qt-5.5/canvas3d/canvas3d/threejs/build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug/android-build --deployment bundled --android-platform android-23 --jdk C:/NVPACK/jdk1.7.0_71 --verbose --ant C:/NVPACK/apache-ant-1.8.2/bin/ant.bat
put these build cmd into windows .bat. for example compile.bat
..code-block:: python
“F:Qt55.5android_armv7binqmake.exe” F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsplanetsplanets.pro -r -spec android-g++ “CONFIG+=debug” “CONFIG+=declarative_debug” “CONFIG+=qml_debug” “F:Qt5Toolsmingw492_32binmingw32-make.exe” -C F:Qt5ExamplesQt-5.5canvas3dcanvas3dthreejsbuild-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug` “F:Qt55.5android_armv7binandroiddeployqt.exe” –input F:/Qt5/Examples/Qt-5.5/canvas3d/canvas3d/threejs/build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug/android-libplanets.so-deployment-settings.json –output F:/Qt5/Examples/Qt-5.5/canvas3d/canvas3d/threejs/build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug/android-build –deployment bundled –android-platform android-23 –jdk C:/NVPACK/jdk1.7.0_71 –verbose –ant C:/NVPACK/apache-ant-1.8.2/bin/ant.bat
Open VS and Create external build system for the project.
- Additional C/C++ source Directories:
F:\Qt5\Examples\Qt-5.5\canvas3d\canvas3d\threejs\planets - Additional Library Symbols Directories:
F:\Qt5\Examples\Qt-5.5\canvas3d\canvas3d\threejs\build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug\android-build\libs\armeabi-v7a - GDB Working:
F:\Qt5\Examples\Qt-5.5\canvas3d\canvas3d\threejs\build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug\android-build\ - Java Source Directories:
F:\Qt5\Examples\Qt-5.5\canvas3d\canvas3d\threejs\build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug\android-build\src - Java Classes Directories:
F:\Qt5\Examples\Qt-5.5\canvas3d\canvas3d\threejs\build-planets-Android_for_armeabi_GCC_4_9_Qt_5_4_2_0c4ce3-Debug\android-build\libs
- Additional C/C++ source Directories:
QML¶
QT meta language, 就像tk一样,内嵌javascripts的解析器,界面就像HTML一样,不过不是标记语言。采用描述语言。 需要扩展都通过QtDeclarative来注册实现。有点像androidSDK使用XML来写界面。 http://www.digia.com/Global/Images/Qt/Files/Qt_Developer_Day_China_2013_Presentations/Qt%20Quick%20and%20Qt%20Quick%20Controls%20intro.-%E5%A4%8F%E6%98%A5%E8%90%8C%204-5%20PM%20-%20Qt%20Dev%20Day%20China%202013.pdf
现在的一种resource 编译方式,直接生成数组,就像自己平时构造python数组是一样的。QT的resource把资源直接编译成字节数组了。
原来方式是一个个control来放,现在直接
viewer.engine(().addImport()
viewer.setSource(QUrl(grc:/planets.qml"))
采用类似于Unreal的组件开发,由c++实现组件,而Javascript再上层做界面的操作。交互是Javascript有QT的对象接口可以直接访问。就像Squish中, 可以使用各种脚本来进行操作组件。 http://brionas.github.io/2014/08/15/How-to-integrate-qml-with-C++/ 深入解析QML引擎, 第1部分:QML文件加载
窗体的创建¶
http://blog.csdn.net/tingsking18/article/details/5528666
用调试断点,就可以直接查看其效果,其本质还是对Windows class 的封装,实现了一套自己的窗口管理体系。 而这个窗口体系维护了一个数据结构,button本身不具有什么深浅关系的。
对于问题的调查,
QDateTime¶
会用到系统 Locale设置,不匹配时就会出现。
moc(Meta-Object Compiler)¶
就是元编程中,先把meta-object 生成目标源码,这种做法与Unreal的 UBT是一样的。 例如在代码中有
Q_OBJECT
就会生成代码,这样是一种变相解决编译语言非动态特性,并且把语言进行了二次调度。编程语言本身的灵活性。
元语言则提供了语言本身的编程。 所以元语言编程,特别是任何对现有语言进行二次开发,为其添加特定的数据结构,例如MFC,QT等的消息循环,以及内存管理机制。但是又不减少语言本身的灵活性,只是为其添加了额外的功能。
UIC(User Interface Compiler)¶
类似于Moc,就是读取QT Designer 生成*.ui, 然后生成对应的C++头文件。
http://doc.qt.io/qt-4.8/uic.html。
自从Android之后,直接用XML来生成变面的方式,很流行。用XML来生成页面是从html学来的, 再往前走一步那不是QML这种方式,只是XML这种可读性更好了,把定界符给改了。 再加一个brower的引擎。
Python 编程¶
Introduction¶
Until now, the python is very concise language. It have all the metrics of previous language. You can the shadow of every language in it. it use the space indent for delimiter. it adapt the function programming technique. it use the file name as module.
It has the OOP and basic procedure language. the data structure : list, array, dict(hash table). the data has constant meta-list just the C/C++. it use =global= instrument is just like the tcl’s “global”. there is import is mix namespace import and export and source. the class just like the java, the first parameter of method is self point. there is also exec,eval assert raiseError just like tcl. and lambda in Scheme.
os and sys 对于系统的操作¶
可以考虑用python脚本来代替shell脚本。并且要考虑并行的问题。
#. can-i-use-python-as-a-bash-replacement 这个讨论已经写的很详细了。 there is two core module: sys and os. just like info in tcl. sys is most about python interpreter. for example, the sys.path is object search path for lib and module. here
并且以后要把print都要换成`logging <http://victorlin.me/posts/2012/08/26/good-logging-practice-in-python>`_来全用。 用python popen处理一些系统的命令它会返回一个对象,
logging¶
import os
print os.popen('ping g.cn')
#!/usr/bin/env python
import sys
import os
topdir = os.path.dirname(os.path.abspath(__file__))
if sys.platform == 'cygwin':
topdir = os.popen('cygpath -a -m %s' % (topdir), 'r').read().strip()
sys.path.append(topdir+"/lib")
from nose import main
if __name__ == '__main__':
main()
它返回一个文件对象,你可以对这个文件对象进行相关的操作。
但是如果你想能够直接看到运行结果的话,那就要用到python os.system,用了以后,立竿见影! 还是上面的问题:
import os
print os.system('ping g.cn')
输出的结果是:
64 bytes from 203.208.37.99: icmp_seq=0 ttl=245 time=36.798 ms
64 bytes from 203.208.37.99: icmp_seq=1 ttl=245 time=37.161 ms
直接使用VS2015 PSVT的功能,可以条件断点等等功能,非常的的方便。
Profiling¶
python -m cProfiler XX.py
epydoc¶
生成callgraph
Python 内在函数¶
| dir() | __name__ | __file__ | |
| built-in command | http://docs.python.org/2/library/functions.html | ||
| Tuple 介绍 | 不可变的list | ||
| SymbolPy | 符号计算 | ||
| MatPlotlib | 画图 | ||
| NumPy | 矩阵与线性代数 |
Python 包管理与开发环境¶
Python的包管理就像perl 的CPAN一样。 easy_install 与pip 新替 就是python 的CPAN。http://jiayanjujyj.iteye.com/blog/1409819 egg文件就是python的打包文件。 可以用setup.py 打包,同时也可以pbr 生成setup.cfg的配置文件。这个在包本身比较复杂的情况下会非常有用,就像gnu libtool一样。
- 打包机制 .egg文件
- perlbrew python virtual environment and multi-version perl的虚拟环境。ruby也有。
- pythonbrew online document
- VirtualEnv 和Pip 构建Python的虚拟工作环境 这个写的不错,virtualEnv 解决的就是不同库依赖之间的问题。并且有实例。而pythonbrew主要解决了不同引擎之间切换。同是兼容了,virtualenv这样的样的环境。这样就可以在版本与库之间进行选择了。就像pyrobot一样,就可以选择环境,选择brain.
- 用pythonbrew指是采用哪一个python, 而virtualEnv 指的在哪一个环境下使用python. 其本质是与linux的chroot是一样的道理。
- python configparser.py 以后配制文件,可以使用它,而不用自己在写分析了,有了一个标准的分析库。它采用的是windows INI 文件格式。
- 用 twine 可以把自己包提交到PyPI上。
包的开发与目录结构 import 可以是整个包也可以只是变量,函数。但是python把命名空间与import并且source的功能混在一起了。看起来有一些不舒服。 for install and manipulate the package of python, just like pkgIndex in tcl. there is distutils.core. which manage the preprocess, compiler,linker, verification, install.here has some useful command:
| setup | ||||||||||
| distutils.ccompiler | set_libraries | add_library_dir | add_runtime_library_dir | define_macro | dir_utils | file_utils (mkdir | rm | copy_tree) | ` distutils-simple-example <http://docs.python.org/2/distutils/introduction.html#distutils-simple-example>`_ | this is helpful when you are writing more code. |
| when you install some extention module written from C/C++. you and build environment. you can gcc or MSBUILD. setup.py compiler options manual | ||||||||||
| 如果要`打包成可执行文件 原理 <http://wiki.woodpecker.org.cn/moin/LeoJay/PyPackage>`_, | ||||||||||
| pyInstaller | http://www.pyinstaller.org/ticket/512 opencv 好像还没有支持 | |||||||||
| cx-freeze | ||||||||||
| py2app | mac 平台 |
还有setup的编译环境,其实就是一个makefile,就是类似于ndk的东东,只是写了一个类与配制文件,把这些手工的步骤给封装了起来,对于C/C++编译就是那几步了,同时会把编译,链接的库的路径等等都会设置好,系统默认值一些值都会自动搜索系统目录,例如对于VC就会使用注册表信息去找这些。而对于linux gcc,windows cygwin,mingw等等都是这样的。 对于python 自己distutil 包setup 相当于python的grudle一样,在里面把所的配置信息写好,扩展的化就类似distutil.compiler类来做了。 并且theano也是采用这样的方式来封装nvcc的。
以及各种开发模式,插件式与模块化的区别与连系是什么。 例如python ETS插件式开发,http://code.enthought.com/projects/ .
包管理的难点,在一个单一环境是容易的,难点各种包管理模式之间的冲突,但是apt-get 与pip 如何兼容的,包管理本身也需要一定的信息结构。例如依赖关系,linux讲究的相互共享,这就造成了,系统升级之后,就莫名其妙的不能用了,而windows采用的是自包含,所以现在windows会变非常大。包管理的特点 依赖关系,方便的查询操作,以及编译环境的准备。这个有perl,python,以及gentoo的包管理,都非常熟悉。
pip 现在支持一次安装列表 pip -r requirements.txt 同时还支持zip,以及从git,或者svn直接安装。 而不需要每次手工来一条条来做了。
namespace¶
- python学习笔记——模块和命名空间 在python中是一切对象,这个与lisp一切结数据的模式是很像的,现在还不知道hackshell的编程模型是什么。python的几种命名空间,对于简单函数调用,python可以像传统的面过过程一样,直接调用其函数,也可以采用面向对象方式。python面向对象机制是不是有一点像perl,但是它的面过过程的调用是通过静态函数来变通的。还是本来两种方式都是可以的。
- build-in name space
- global name space
- local name space
关系的表达就是最直接的方式之一,那就是指针,类中各种关系其实都类,都是一种指针 在数据库那就可以叫做外键。
对于静态变量可以当做是空间变量的一种吧。其本质还是变量的作用域不同。现在其提供了多种粒度的变量 全局变量,例如环境变量,以及python自己的全局变量。可以供包之间共享信息与通信的。 包变量,用于包内子包或者类之间的通信。 类静态变量用于,所以所有实例之间需要通信的变量。 类变量,同一个实例各个成员函数之间的通信变量。 函数静态变量,这个在C中有,用于多次调用这个函数之间的通信。 特别是在神经网络进行优画的时候这个用的最多。当然也可以把这些拿到其他的方式来实现。
string,list,dict/hash and tuple¶
String is Object itself, so when you manipulate string. you do it like this “XXXX”.append(“XXX”); one of important is regular expression. for python you use `re <http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html>`_
+=============+====================================================================================+ | u’a string’ | prefix u stand for unicode character | +=============+====================================================================================+ | r’a string’ | prefix r stand for original string means regular expression is object too. | +=============+====================================================================================+
pattern = re.compile(r'hello')
match = pattern.match('hello world!')
match.group()
match 必须是从头开始匹配,search是不必的。
dictionary{}必须是key-value对,核心是哈希,内容可以使任何元素,可是实现删除,del and d.clear()。里面的key是虚幻的。
list中是有顺序的,因此可以insert, append, extend. list中就是数组操作,比如插入,remove,她的所有操作都是基于index的。里面的index是顺序排列的,比如123.。 应该讲的有条理些,如果我现在不做,就找不到工作。
tuple ()就是不可以改变的。
为了能够确定对象的属性,python使用一些系统参数比如 str, callable, dir:
str 主要是字符串操作,可以帮我找到 modulate的位置,其他的有么用不太清楚。
callable 主要从对象中找出函数。
dir列出所有的方法的列表。
getattr()得到对象的属性。
doc string 可以打印方法函数的document。
Python vs.C/ Matlab
其智能化主要体现在 “+”可以同时实现 字符串连接和算术运算。
多变量赋值,简化操作,就像perl一样。
逻辑运算:and,or 相比更加容易理解。
很多格式都是规范的,比如 indent,list.
Python 中 的class¶
什么是类,我想就是分情况,然后需要的初始化__init_,一个class定义一种__init__就是初始化函数,里面的self就是参数赋值,然后就是def各种方法,利用参数值。
另外python中class 中各种特殊的属性,可以class具有各种功能,例如__call__这样就可以把class变成了函数,并且可以有各种状态。另外还有各种操作符。
python 本身没有抽象类的概念,实现这些约束:如果子类不实现父类的_getBaiduHeaders方法,则抛出TypeError: Can’t instantiate abstract class BaiduHeaders with abstract methods 异常 则需要from abc import ABCMeta, abstractmethod 来添加这些依赖。 主要是实现 抽象方法与抽象属性这两个关键字。
各种字符串之间的转换(dictionary->str,list->str)¶
string ->list split,splitlines list ->string, join list -> dict, dict((key,value)….) or dict(key=value,,,,,)
list->str 可以通过”“.join(li)实现, 但是不要通过str(),这种属于硬转换(只是在外面加了一个“”).
str-》list, bd.split(“,”)好像不行,因为split适用于把有一定界限的str分离。
dict-》str, str(dict) 我觉得不太行,还是硬转换。??
str->dict, eval(str)很多网站说这个是字符串转换,但是我觉得并不能成为字符串转换吧。原意是evaluate。
rspr,这个用来反回对象的文本显示。
python comments¶
comments is important part of an programming language. most of the document is generated from the comments in code. One orient, is putting document into code, which can be easier to maintain and update. so structure and format is important for an programming language. take compare several language.
+========+=================================================================+=================================================+ | perl | has pod document system, and << STRING, and format report | pod2tex,pod2man,pod2pdf | +========+=================================================================+=================================================+ | java | javadoc | | +========+=================================================================+=================================================+ | c /C++ | if you adopt the C/C++ syntax, you can use doxygen to generate | | +========+=================================================================+=================================================+ | python | __doc__ ,__docformat__,reStructuredText | python has puts comments as variable of python | +========+=================================================================+=================================================+
you can access the comments from in the code of __doc__. one usage for this is just like CAS testcase steps:
def tounicode(s):
"""Converts a string to a unicode string. Accepts two types or arguments. An UTF-8 encoded
byte string or a unicode string (in the latter case, no conversion is performed).
:Parameters:
s : str or unicode
String to convert to unicode.
:return: A unicode string being the result of the conversion.
:rtype: unicode
"""
if isinstance(s, unicode):
return s
return str(s).decode('utf-8')
http://docutils.sourceforge.net/docs/peps/pep-0257.html 也就是基本的原则,语法还可以用markdown以及sphinx,只是函数模块类等的一第一段注释会被处理成文档。并且支持中文用u”“”就可以了,以及r”“” 256,224,216,这几篇都看一下。
command line¶
for python, you can process comand line options in three way:
- sys.argv
- getOption
- plac module Parsing the Command Line the Easy Way
- argparse this one looks good for me, it just like getOption, but stronger than her.
- Command module
mutli-thread of python¶
多线程与进程一样,可以动态的加载与实现,而不必须是静态。并且可以是瞬间的,还是是长时间的。之前的理解是片面的,这个受以前学习的影响,一个线程或者线程就像一个函数根据其功能的来,不是说是线程就要有线程同步。可以是简单的做一件事就完的。例如实现异步回调呢,就可以是这样的,把回调函数放在另一个线程里。用完释放掉就行了。C#线程篇==-Windows调度线程准则(3) 如何让自己的程序更快的跑完,其中在不同提高算法性能的情况下,那就是占一些CPU的时间片,优先级调高一些,就像我们现在做事一样,总是先做重要的事情。然后按照轻重缓级来做。就像找人给干活的时候,你总经常会说把我的事情优无级高一些。先把我的事情做完。 这个应该可以用转中断来实现。 Lib/threading.py
*Python threads synchronization: Locks, RLocks, Semaphores, Conditions, Events and Queues <http://docs.python.org/2/library/threading.html>`_
例如以前的,我都是利用傻等的方式,还有时间片或者用sleep,其实异度等待的机制可以用`线程事件来高效实现 <http://blog.csdn.net/made_in_chn/article/details/5471524>`_
协程的实现原理¶
协程本质相当于软中断,能够在函数中暂停,并且还能返回继续执行, C语言的函数内部的static变量的模型, 语言的调用模型ABI模型直接采用了原始的CPU的内存模型,C语言就是这个么干的,但是python就却是自己直接用在堆上实现的。 相当于hack了一把function frame 并且没有只是原来first in,last out原型而在原来的stack 模型上又加上了一个引用计数的模型。 http://aosabook.org/en/500L/a-web-crawler-with-asyncio-coroutines.html 有详细讲解了其模型。
把这些东西优化到编程语言这一层那就是协程了,python 中 yield就是这样的功能。通过协程就可以原来循环顺序执行的事情,变成并行了,并且协程的过程隐藏了数据的依赖关系。 对于编程语言中循环就是意味着顺序执行。如何提高效率,实别的计算中数据依赖问题,把不相关的代码提升起来用并行,采用协程就是这样的原理。 这也就是什么时候采用协同。什么时候采用协程了。这个优化是基于实现的优化是基于你的资源多少来的。所以在python对于循环进行了优化。所以写循环的时候就不要再以前的方式了,采用计算器了,要用使用yield的功能。来进行简化。coroutine, 线程就是它什么时候执行,什么开始都是由内核说了算的。你就控制不了。coroutine就是提供了在应用程序层来实现直接的资源调度,如果更直接控制调度,另一个就是采用CUDA这样更加直接去操作硬件资源。 yield 可以相当于 C语言中函数内static, 但是 yield有点类于return 但是yield 之后的代码也可以继续执行。 相当于 last PC pointer https://hackernoon.com/the-magic-behind-python-generator-functions-bc8eeea54220
并且yield 实现一个 callback. 也是非常方便的。这个实现反包。被调用函数反包调用。 就是一个中断的机制,并且方便实现一个二分,或者多分。并且每一次yield都可以有返回值。 例如 teardown 与setup 写在一个函数里。 yield相当于中断的简单化,例如用switch + yield就可以不同的信号量,就像 raise一样。
def test_tearupdown():
make tempdir
yield tempdir
clean tempdir
def test_boday( temp_dir):
print("in test")
print("aa,bb")
def exec1_test(test_func,tearupdownfun):
fun_fear = tearupdownfun
test_boday(fun_fear.next())
fun_fear.next()
@exec1_test(tearupdown)
def test_boday2(tempdir):
print("test body3")
对于状态进度的更新有了一个更好的方法,注册一个时间片的中断函数,每一次当一个时间片用完之后,就来打印一个进度信息就不行了。这样就可以实时的知道进度了。 Linux环境进程间通信 目前看来需要在进度的SWap时来做的,需要内核调度函数提供这样一个接口。那就是在线程切换的时候,可以运行自定义的函数。其实这个就是profiling的过程。在编译的时候,在每一个函数调有的前后都会加上一段hook函数。我们需要做的事情,把切换的过程也要给hook一下。这个就需要系统的支持了。coroutine的实现 linux下可以有libstack库来支持,当然 了可以直接在C语言中嵌入汇编来实现。用汇编代码来切换寄存器来实现。
现在对于C语言可以直接操作硬件,这种说法的错误。同为一种语言凭什么说C可以操作硬件。原因在于好多的硬件直接C语言的编译器而己尽可能复用以前的劳动成果而己。只要你能把perl,python,各种shell变成汇编都能直接操作硬件的。
现代语法¶
List comprehensions 也开始发展perl的各种符号功能
Ilterators generators
a = [expression for i in xxx if condition] //list comprehensions
a = (expression for i in xxx if condition) //list generator
a = [(x,y) for x in a for y in b] 这个不同于双层循环
a = [expression for x in a for y in b ]这个相当于双层循环
再加上 http://stackoverflow.com/questions/14029245/python-putting-an-if-elif-else-statement-on-one-line 对了可以使用lamba来实现
Python yield 使用浅析 原理也简单,既然可以lamba 可以部分求值。yield的机制也就是执行变成半执行。参加的功能那就是计录了前当前的状态。当下一次调用时候,就可以直接恢复当前环境。执行下一步了。yield的功能其实就是中断恢复与保存机制。每一次遇到就这样保存退出。并且也保证了兼容性。下面的例子也就说明了问题。其实就是集合的表达方式问题。我们采用列举式还是公式表达式。 数据的表达方式就是集合表现方式。研究明白了集合也就把如何存储数据研究明白了。列表相当于我们数据采用列举式,而生成式我们采用是公式表示。
部分求值,现在发现在其实也很简单,函数就是一个替换的过程,部分求值,什么时候替换的过程。难点在于传统的函数值是要释放的,而部分求值,反回来另一个函数,并且这部分求值当做参数传出来。这样实现部分求值。另一个那就是变量在函数中不同作用域,不能随着函数的消失而消失。直接引用全局变量或者static变量都可以达到这个目换。并且本身支持函数对象化。更容易做到了。
range(6) [1,2,3,4,5,6]
xrange(6) 相当于定义了类,最大值是6,最小值是0,步长为1,当前值为0.每调用一次,更新一下当前。当然利用这个是不是可以产生更多数更加复杂表达方式。同时也解决了以前在CAS的那sendMutliCmd中循环,无法记录自身当前值问题,必须使用global去使上一层变量的方法,现在通过这个yield方法就会非常方便。这个其实编程语言中闭包问题,就是在子函数中调用复函数中局部变量,在tcl中可以使用upvar来实现。使用动态代码实现一个子函数来进行调用。而在python这里可以直接yield来产生。同样也可以自己实现。
class repeater {
init;
step;
current:
next: 调用一次method
reset:
set:
method{ output=current+step;current=output}
}
这样就用计算代替了存储。并且解决吃内存的问题。
而对于tcl 中的foreach的功能可以利用zip + for 来实现
for x,y,z in zip(x_list,y_list,z_list):
`65285-looping-through-multiple-lists <http://code.activestate.com/recipes/65285-looping-through-multiple-lists/>`_ 可以使用map,zip以及list来实现。
`yield与labmda实现流式计算 <http://www.cnblogs.com/skabyy/p/3451780.html>`_
itertools 更多的迭代器可以采用这些,这些采纳了haskell中一些语法。
Descriptors properites
Decorators¶
- Python装饰器与面向切面编程 %IF{” ‘这个其实是perl那些符号进化版本’ = ‘’ ” then=”” else=”- “}%这个其实是perl那些符号进化版本
其实本质采用语法糖方式 ,其实宏处理另一种方式。在C语言采用宏,而现代语言把这一功能都溶合在语言本身里了。decorator直接采用嵌套函数定义来实现的。最背后是用lamba来实现 的。 其本质就是宏函数的一种实现,并且把函数调用给融合进来了。本质还是 函数管道的实现。 本质就是闭包计算,这个语法糖就是多级闭包的实现。 https://foofish.net/python-decorator.html 而多参数的语法糖,是靠两级闭包来实现的。
@wraper
def fn():
do something
a().b().c()
a() | b() |c()
$a bc $ a bcd $c (in haskwell)
它的执行顺序是从里到外,最先调用最里层的装饰器,最后调用最外层的装饰器,它等效于
使用 decorator 的好处,实现函数的原名替换,同样的函数名却添加了实现。有类似于Nsight 中 LD_PRELOAD 中那API函数一样的做法。 任于参数如何传递就是简单函数传递。
至于变长修饰变长函数 也是同样的道理。 http://blog.csdn.net/meichuntao/article/details/35780557 其实就是直接全用args就行了,就传了进去了,只是一个参数传递的过程,这个pentak中automation到处在用了。 把要wrapper的参数传递进行去。 http://blog.csdn.net/songrongu111/article/details/4409022 其本质还是闭包运算一种实现,基本原理还是利用函数对象以及各自的命名空间来实现。 而不用知道函数要有固定的参数,修饰变长函数。这个直接看源码的函数调用那一张,采用的命名空间嵌套的用法,原则最里优先。
functools 提供了对于原有函数进行封装改变的方便方式。也就是各种样的设计模式加到语言本身中。
python对于循环进行了优化。所以写循环的时候就不要再以前的方式了,采用计算器了,要用使用yield的功能。来进行简化。 yield就相当于部分的C函数中static变量的功能。并且 比他还强的功能。另外也可以global的机制来实现。 map,reduce机制,例如NP就经常有这样的操作,例如
reduce,map与函数只是构造计算中的apply函数一种。 例如自己实现那个累乘也是一样的。
reduce,只一次只取列表两个值,而map每一次只能取一个值。对于取多值的,可以用ireduce,imap
def reduce(function,iterable,initialzer=None):
it = iter(iterable)
if initialzer is None:
try :
initialzer = next(it)
except:
for x in it:
accum_value = function(accum_value,x)
其实这样的函数就相于一个神经元。 python iteral_tool 就相于一个个神经元。
x,y,z=np.random.random((3,10) 每一个一行。
并行处理¶
以后要把for循环升级到map,reduce这个水平,两个概念是把循环分成有记忆与无记忆,map就是无记忆,reduce是有记忆。 Python函数式编程——map()、reduce() 就是为了并行计算,但是内置的这两个函数并不是并行的, 可以使用 multiprocessing 来进行。
python中动态代码的实现¶
一种实现方式,自己手工做一个函数表 hash dict,key就是对应的字符串,其实完全没有这个必要,动态创建本来就是为减少维护与编码,这样写我一直用if,else 有什么区别呢。
可以利用sys.modules[‘__main__’] 再加getattr来实现。同时也可以用locals,globals等等hashtable直接可以用。而不必自己手工再做一套。
cmd = "update_{}".format(product_list[productIndex])
cmd = getattr(sys.modules['__main__'],cmd)
cmd()
C extending Python¶
对象机制的基石——PyObject PyObject 本质就是结构体指针加一个引用计数。
shutil¶
学见的文件操作,copy,move都在这里有,另外打包函数也是有, make_archive,基于 zipfile,tarfile来实现的。而这些后台都是调用zlib,或者bz2.
简单的创建目录,os.makedirs 都有。删除文件都有。对于目录操作。shutils. 但是对 shuttil.copytree一个问题那就dst 目录必须存在,用distutils.dirutil.copy_tree就可个问题。
如何想更灵活,就只能用os.walk自己写一个。一般都是判断一个目录与文件,另外那就是符号链接了。
读写二进制文件可以用,struct,以及unpack,pack函数。
difflib¶
python 有现成的diff库可以用,所以也可以在ipython 调用 difflib来当做命令来用。
python的标准库比较全面,有点类似于libc,网络,tty,以及系统管理等等相应的库。 http://python.usyiyi.cn/python_278/library/index.html
test framework of python¶
- `使用再简短手册 <https://nose.readthedocs.org/en/latest/][nose]] NOSE 底层驱动unittest 来进行的。[[http://wenku.baidu.com/view/422b7585b9d528ea81c77967.html>`_最快的方法那就直接问Ryan.
- pexpect 我们的GDBtest 是采用pexpect来进行gdb交互的。 今天出现工作不稳定的问题,是因为python版本不高造成,直接在cygwin中升级一下python就行了。
Data structure¶
embeded dict. what-is-the-best-way-to-implement-nested-dictionaries-in-python 其中一个方法hook __getItem__ 来实现,但是有一个效率问题,其实那种树型结构最适合用mongodb来实现了。并且搜索的时候可以直接使用MapReduce来直接加快计算。
High-performance container datatypes 同时还支持 ordered Dictionary 同时支持对基本数据结构进行扩展,利用继承 。
如果让dict 像一个类样http://goodcode.io/articles/python-dict-object/, 一种是采用self.__dict__ 来实现,另外一种采用__setattr__,__getattr__,__delattr__的方法来实现。
要想高效的利用内存分配还得是C/C++这样,自己进行内存的管理。管理原理无非是链表与数组。并由其排列组合出多结构。
embeded system¶
python data analysis¶
python主要用于大数据分析的比较多,大的数据分析主要包括三个方面: 数据本身的存储,分析,批量处理,以及可视化的问题
数据存储,关键是效率
- csv 最简单直接,并且方便扩展
- xml 机器交互性强,但是不算太方便
- npz 最简单直接
- python 本身的串行化,效率不高。
- pyData/pyTable 对大数据的存储
- h5py 这个压缩存储
best way to preserve numpy arrays on disk
分析计算 #.numpy,pandas,`blaze 下一代的numpy,总结pyData,pyTable,pandas <http://blaze.pydata.org/docs/latest/overview.html>`_ 例如优化算法,以及优化求解等,同样可以pyomo等之类的库来实现。
可视化: pylab,VTX以及直接利用opengl来计进行。 以及reportLib 对于pdf的直接读写。以及使用pyplot来进行二维以及三维的画图。pandas plotting .
正是由于python的一切对象机制,使其把投象与具体结合起来,可以很方便应用到各个学科与领域,其实这个本身就是一个知识库。现在需要一个快速推理管理工具。
专业领域的应用¶
例如对编程本身的支持,
但是python本身也自身的缺点,一个方面那就是GIL,并且他的效率是依赖C或者其他。不过python的一切皆对象方式不是错。可以把python当做一个描述语言。 具体让编译器来做翻译。 一个软件好用不好用的关键,是不是大量相关的库,在科学计算领域python是无能比了。自己尽可能用高阶函数来表达核心的东东,而不必纠结实现细节,其实道理都是一样的。 对于python的扩展这里提到cffi来扩展。以及bitey. 以及用distutils功能完全可以用来实现gradle所具有一切功能。 例如强大的 c++ boost库,同样也有python的接口 见 http://www.boost.org/doc/libs/1_55_0/libs/python/doc/。
下一代了 pypy .
ipython notebook¶
其实就相是CDF的一种形式,可计算文档的结构。特别适合写paper来用。并且也实现了文学编程的模式。
并且可以直接保存在github上然后直接用http://nbviewer.ipython.org/ 直接在线的显示,是非常的方便,自己只需要用就行了。然后干自己的主业就行了。并且其支持与sphinx的之间格式的转化。
但是与CDF还有一定的区别,reader本身也要执行计算功能。
https://github.com/csurfer/pyheatmagic 可以用pyheat来进行优化。这样可以用热力图来显示代码的执行频度。
python as shell¶
http://pyist.diandian.com/?tag=ipython 现在看来,自己想要常用功能都有,只要把find,与grep简单的整一下,再结合%sx,与%sc,就无敌了,并且也不需要每一次都写到文件里,可以放在python 的变量里,因为python的变量要bash的变量功能要强大的多。 支持用iptyhon,尽可能,只要离开就要提出一个bug.这样就可以大大的提速了。直接继承一个magic class就可以简单,然后直接loadext就可以了,实现起来简单。自己也慢慢往里边添加自己的东东。可以参考在python里直接执行c的插件。看来这个扩展还是很容易的,把知识代码化,而不再只是文本描述。
并且ipython提供了类似于tcl中多解释器的方式,来实现多进程与kernel的并行,可以让并行计算随手可得,并且解决了GIL的问题,并且能够与MPI直接集成。%px 这个插件,看来是要升级自己的shell从bash到ipython了。
`if expand("%") == r"|browse confirm w|else|confirm w|endif"`
在ipython 中使用vim mode其实也很简单,直接配置readline这个库就行,正是因为linux的这种共享性,只要改了readline的配置文件,那么所有用到它的地方都会改变,一般情况下,默认的文件放在/usr/lib里或者/etc/下面。这里是全局的。 http://stackoverflow.com/questions/10394302/how-do-i-use-vi-keys-in-ipython-under-nix http://www.linuxfromscratch.org/lfs/view/6.2/chapter07/inputrc.html
减少与() 的使用就是 可以用 %autocall 来控制这个命令的解析的方式,或者直接 / 开头就可以了,在这一点上, haskell 吸收了这个每一点。把函数调用与 管道 统一了起来。在用python中是用点当管道使用了,bash 中通用的结构是 file而在 baskell中通用的是 list,其实就是矩阵相乘,只要首尾可以互认就可以了。
在haskell 中我们采用 $ 来指定这些事情。
配色同样也是支持的可以查看 %color_info 以及 %colors.
同时为了把python变成shell, 还有一个专门的库,plumbum 来做了这件事。 https://plumbum.readthedocs.io/en/latest/,但是还没有shell本身简练。
See also
- flask %IF{” ‘Flask is a microframework for Python based on Werkzeug,Jinja 2 and good intentions.’ = ‘’ ” then=”” else=”- “}%Flask is a microframework for Python based on Werkzeug,Jinja 2 and good intentions.
- A Byte of Python %IF{” ‘an introduction tutorial’ = ‘’ ” then=”” else=”- “}%an introduction tutorial
- data structure list, metalist, dict,class,module
- python PEP %IF{” ‘what is PEP’ = ‘’ ” then=”” else=”- “}%what is PEP
- 在应用中嵌入Python %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- Python on java %IF{” ‘’ = ‘’ ” then=”” else=”- “}%*Commute between Python and java* JythonUtils.java there use hash table to mapping the basic data element between java and python.
- org.python.core %IF{” ‘the online manual’ = ‘’ ” then=”” else=”- “}%the online manual
- jython offical web %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- install sciPy on linux %IF{” ‘科学计算’ = ‘’ ” then=”” else=”- “}%科学计算
- python and openCV %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- ipython %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- python for .net CLR Just like Java for JPython, anything in .net you can use via clr.
- Python之函数的嵌套 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- 简明 Python 教程 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- Python 中的元类编程,这才是python 所特有的东西。 元类是什么,就是生成类的类。
- 五分钟理解元类 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- Python 描述符简介 %IF{” ‘还是不太懂’ = ‘’ ” then=”” else=”- “}%还是不太懂
- Python 自省指南 如何监视您的 Python 对象 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- 可爱的 Python: Decorator 简化元编程 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- Python的可变长参数 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- cuda support python %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- cuda python %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- 欢迎使用“编程之道”主文档! %IF{” ‘基于python更接近于自然语言’ = ‘’ ” then=”” else=”- “}%基于python更接近于自然语言
- how-to-install-pil-on-64-bit-ubuntu-1204 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- marshal 对象的序列化 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- python PIL %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- sorted %IF{” ‘key 与cmp到底有什么区别’ = ‘’ ” then=”” else=”- “}%key 与cmp到底有什么区别
- python-convert-list-to-tuple %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- pygame %IF{” ‘在研究游戏的时候来看一下’ = ‘’ ” then=”” else=”- “}%在研究游戏的时候来看一下
- python 图像应用实例 %IF{” ‘里面有很多代码,有空的时候要看一下’ = ‘’ ” then=”” else=”- “}%里面有很多代码,有空的时候要看一下
- python 多继承 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- ` windows7下使用py2exe把python打包程序为exe文件 <http://blog.csdn.net/xtx1990/article/details/7185289>`_ %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- ` 函数迭代工具 <http://www.cnblogs.com/huxi/archive/2011/07/01/2095931.html>`_ %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- python 字节码文件(.pyc)的作用与生成 %IF{” ‘python 可以把pyc 当做二进制发布,当然可以也可以自己加密使用’ = ‘’ ” then=”” else=”- “}%python 可以把pyc 当做二进制发布,当然可以也可以自己加密使用
- python-with-statement %IF{” ‘这个要求你的类,自己有enter,exit函数,with 会自动调用这些。’ = ‘’ ” then=”” else=”- “}%这个要求你的类,自己有enter,exit函数,with 会自动调用这些。
thinking¶
Jython embedded and extension with java just like right diagram, you there are three way call the jython, there an other way is extend the jython with the java. there are some interface to follow. and there is mapping between your jython data type and java data type. they provided some converting function. java can use the jython installed on the PC. androidRobot reference the example monkeyrunner.JythonUtils.java robot run on its base.
@MonkeyRunnerExported is used to generate _doc_ for python method, _doc_ is built-in string for documentation. JLineConsole(); Just support single line command? PythonInterpreter source code
at ScriptRunner.java, via run. bind the robot->RobotDevice.
public static int run(String executablePath, String scriptfilename, Collection<String> args, Map<String, Predicate<PythonInterpreter>> plugins,Object object)
/* */ {
/* 79 */ File f = new File(scriptfilename);
/* */
/* 82 */ Collection classpath = Lists.newArrayList(new String[] { f.getParent() });
/* 83 */ classpath.addAll(plugins.keySet());
/* */
/* 85 */ String[] argv = new String[args.size() + 1];
/* 86 */ argv[0] = f.getAbsolutePath();
/* 87 */ int x = 1;
/* 88 */ for (String arg : args) {
/* 89 */ argv[(x++)] = arg;
/* */ }
/* */
/* 92 */ initPython(executablePath, classpath, argv);
/* */
/* 94 */ PythonInterpreter python = new PythonInterpreter();
/* */
/* 97 */ for (Map.Entry entry : plugins.entrySet()) {
/* */ boolean success;
/* */ try {
success = ((Predicate)entry.getValue()).apply(python);
/* */ } catch (Exception e) {
/* 102 */ LOG.log(Level.SEVERE, "Plugin Main through an exception.", e);
/* 103 */ }
continue;
/*if (!success) {
LOG.severe("Plugin Main returned error for: " + (String)entry.getKey());
}*/
/* */ }
/* */
/* 111 */ python.set("__name__", "__main__");
/* */
/* 113 */ python.set("__file__", scriptfilename);
python.set("robot", object);
/* */ try
/* */ {
/* 116 */ python.execfile(scriptfilename);
/* */ } catch (PyException e) {
=Extendting= see 9.4 P223. Jython for Java Programmers.
== Main.GangweiLi - 29 Oct 2012
pprint pretty print is better than print has more control and smart
== Main.GangweiLi - 02 Jul 2013
怎样在python 中添加路径?
== Main.GegeZhang - 19 Jul 2013
python 中怎样实现程序复用,我想很多文件人家都已经写好了,??
== Main.GegeZhang - 16 Aug 2013
安装python子包
目录 到某个目录下: 首先是 D: 然后是 cd /d D:Program Files (x86)imageAirport
然后是 python setup.py install
== Main.GegeZhang - 11 Jan 2014
python 逐层构成: list->array->matrix
== Main.GegeZhang - 14 Jan 2014
对于集合运算支持 python 有一个专门的 set 与frozenset类型来进行集合运算,本质是通过哈希作为基础来实现的。例如交并补差还对称差集等等,都是可以计算的。既然有了这样的数据结构来支持这样的运算,对于blender,以及GIMP中图形的交并补差也就容易了很多了。首先是顶点交并补差,然后是线最后是面。
多进程与管道¶
现在于进程有了更深入的认识,虽然在c#自己也已经这么用了,但是python还是没有认真的用明白,原来subprocess就是 process, Popen接口给出详细的定义,并且在windows下的实现就是调用了createProcess这个api,并且shell后台就是调用cmd.exe来实现的。
其输入参数,一个就是 其参数,其buffersize指的就in,out,err的缓冲区的大小,是不是通过shell来调用,以及相关environment,以及前导与后导hook,以及working path等等都是可以指定的,并且其输入与输出都是可以指定的。默认是没有。并且是可以通过communciate一次性的得到,输入与输出的。 当然复杂的就可以用pexpect来做,管理就直接使用管做来操作了, 如果用python来写后台程序 可以参考 ndk-gdb.py 中的background Running. 其实写起来很容易,就是in,out,err的重定向问题。可以线程Thread或者subprocess.communicate等待退出并读取输出。
而线程的实现就不需要些东东。 并且知道了如何使用 subprocess 来实现管道,或者直接使用 pipes 来实现。更加的方便。
并且python也封装了spawn 这个API,其本质就是execv,execvpl,等等API的实现。 并且还可以调用os.write,os.read,os.pipes来直接实现。对于os.read. os.exec 可以直接执行任何程序,以及对于 os.fdopen,以及os.dup2这些算是有更深的认识。文件描述符用途就是通过中间机制,来对行硬盘文件的一种map机制。 并且os.path.split 实现了一种head,tailer的机制。
- 对了head,tailer这样的机制,也可list 的slice机制来实现。
- head,tailer = list[0],list[1:]
- 相当于这还有更的实现方法
- i = iter(l), first=next(i),rest=list(i) 以后会有 first *rest = list
看来python 会支持一些更现代的语法。
这样的写法有没有更简单的写法呢。
在bash里开一个进程很简单, 直接spawn,或者fork,或者 (),就可直接启一个新的进程了,同时bash 来说直接把一段代码 {} 然后重定向就相当于重启了进程。 现在把线程与进程搞明白了。 就可以灵活的应用了。 http://ubuntuforums.org/showthread.php?t=943664 https://jeremykao.wordpress.com/2014/09/29/use-sudo-with-python-shell-scripts/
http://ubuntuforums.org/showthread.php?t=1893870 python communitcate应该是工用的,因为gdb也用的这个 同样的sudo 也是可以这样的。 这样的方法才是最通用与简单的,并且就是直接利用进程本身的概念。看来自己还需要把这个要信给补一下了。
- os android my be use this module. and subprocess which just like system call of Perl or expect? which one?
GIL 这里有两篇文章写的不错, http://fosschef.com/2011/02/python-3-2-and-a-better-gil/ http://zhuoqiang.me/python-thread-gil-and-ctypes.html
欲练神功,挥刀自宫, 就算自宫,也未必成功, 不用自宫,也一样能成功!
这三句用到这里简值太精典了,由于GIL限制多线程,要解决这个问题就必须自宫了,但是20多年的发展有太多的库依赖此,也就是就算自宫,也未必成功,但不是没有办法了,直接利用c扩展来做,也直接解决了这个问题,把多线程的东东都放在C语言里,并用ctype来引用就行了。也就是解决问题的思路了。
python的缺点,那就是对多线程以及效率本身不高,但是结构清晰简单。Go语言天生对并行应该支持的非常好。但是一些新的编程范式支持还不错,并且是除了perl之外库非常的语言了。
python 与 asm <http://wdicc.com/asm-and-python/> 非常生动解读了,各个层级的执行效果,为了通用性,人们写出各种各样的执行框架,其实所谓的ABI就是汇编二进制指令之间的复用机制。所谓的dll,以及elf,各个段的机制,其实与代码层面的机制是一样的。并且在elf为了尽可能节省空间,把程序所有重复的字符串symbol都直接全用符号表来压缩,当然如果小于指令地址长度的符号就没有意思了,一个 地址要32位是4字节,64就是8字节来表示的。所以就看你理解的深入程度,深入才能浅出。
pygments 支持各个应用平台,wiki,web,html以及latex,console等等。这样非常方便配色,尤其是代码与log的分析的时候就非常的方便了。为了各种利用生成语法文件是非常的方便。
与自己写一个语法文件一样,其实也是一个词法与语法分析,然后给出配色,并且我们还可以利用语法树直接做一些别的操作,因为它已经支持大部分的语言了。可以省去自己很大一部分时间。可以只加入一个hook就可以了。
python 非常适合做一个interface语言,在于它的简单与精练。然后是各种场景的应用,现在感觉python是可以与perl有一拼了。各种各样库非常全。以后的编程可能都会多层编程同时存在的问题。用来解决灵活性与效率的问题。
http://www.cnblogs.com/cython/articles/2169009.html http://blog.csdn.net/largetalk/article/details/6905378 http://blog.csdn.net/largetalk/article/details/6905378 http://wklken.me/posts/2013/08/20/python-extra-itertools.html http://stackoverflow.com/questions/5695208/group-list-by-values 并且数学上排列组合都实现了。 原来都是为实现http://blog.jobbole.com/66097/ 无穷序列,随机过程,递归关系,组合结构。 都是源于yield. http://radimrehurek.com/2014/03/data-streaming-in-python-generators-iterators-iterables/
这种懒惰性求值,都是利用不yield这种方式产生,并且具有不回退性,那就不能求长度等操作了。每两次的调用不是同一个值了。 这个直接利用语言的高阶特性会非常的简单,例如列表推导,以及filter,map,reduce再加上lambda 的使用,以及sorted 再加上itetools中groupby,
另一大块那就是vector化的索引计算。其实就相当于数据组的sql语言了。
文件操作¶
文件是可以直接当做列表操作。
fd = open("xxx.txt")
for line in fd:
print fd:
subprocess.check_output(["ifconfig"," |grep ip|sort"],shell=True)
with¶
是不是就相当于 racket 中let 的功能。
lazy evluation¶
gen = (x/2 for x in range(200))
这是相当于yield,了,有点相当于管道了。
列式推导 直接加map,filter 会更有效.http://www.ibm.com/developerworks/cn/linux/sdk/python/charm-17/index.html 这样会更有效
currying, Partial Argument, 可以用lambda 来实现,或者使用 from functools import partial;add_five=partial(add_numbers,5)
其本质就是又封装了一层函数。也就是alias 的一种实现而己。在函数调用之前添加了一次的简单替换,或者再一次wrap函数就行了。 什么时候用呢,修改与扩展原来的库函数的特别方便。 另外在参数固定的情况下,这可以用偏函数来减少参数的传递。 高阶函数,利用基本函数形成复杂的功能。http://blog.windrunner.info/python/functools.html。 因为在python里的一切皆为对象,而在C语言里,函数就是一个函数指针,只要把指针地址改了就行了,在python里,只要直接复值 就行了,a.fooc = new_fooc 就搞定了,只要在其后面加载module都会使用new_fooc
参数的传递¶
可以是固定的,位置的,也可以是字典式的,还可以是列表,并且是不定长的,*list,**kwd, 这种做法可以到处用。
例如
self.env.set_warfunc(lambda * args:warnings.append(args))
__getattr__ 用法¶
这个特别适合用于封装一些现有API使其具有 python的形式,一个简单做法,就像GTL用template生成一堆的IDL接口函数文件。 另一个办法那就是利用 python 的这些内建接口,来实现简单高效。 例子可以参考 fogbugz.py的用法。 核心是那参数为什么可以那样定义。
StringIO 的实现原理¶
直接使用一个buffer列表来实现,所谓的buffer最简单的理解那就是一个连续数组空间,并且每一次有一个大小等信息的记录。 然后每一次进行查询也就行了。实现一下那些接口,read,write,tell,seek等等。
string format¶
https://docs.python.org/2/library/string.html,支持对齐与任意字符的填充。这个可以在vim 里用嘛。
getpass¶
可以用于密码的login处理等等。
shlex¶
如果想实现一个简单的语法分析,用shlex就足够了。
读取大文件的某几行¶
seek到位,然后反向搜索。 换行符来实现。 http://chenqx.github.io/2014/10/29/Python-fastest-way-to-read-a-large-file/
单行命令¶
python 的module有两种模式,一种是当做module来调用,另一种是当做脚本来使用。 这个主要是通过
if __name__ == "__main__":
#do someting
由于python有众多的库,可以直接搭建各种server. 例如: HTTP python -m SimpleHTTPServer python -m SimpleXMLRPCServer
from simpleXMLRPCServerr import SimpleXMLRPCServerr
s = SimpleXMLRPCServer(("",4242))
def twice(x):
return x*x
s.register_function(twice) #向服务器添加功能
s.serve_forever() #启动服务器
然后在启动一个命令行,进入pyhon。 输入:
from xmlrpclib import ServerProxy s = ServerProxy('http://localhost:4242') s.twice(2) #通过ServerProxy调用远程的方法,
同时python支持从标准输入直接读入代码: 例如
echo "print 'helloworld'" |python -
这样就可以动态的生成各种代码组合来执行了。
最具C的格式,scheme一切皆对象的形式。再加异步编程的模型,可以随意的用event来进行function call. 每一个函数的执行都可以callback. 应该是每一个对象都有一个callback. 并且还有prototype机制,暂且当做反射来用吧。
- 最好用的IDE online/offfline
- framework
快速入门:https://www.nodebeginner.org/index-zh-cn.html,https://github.com/mbeaudru/modern-js-cheatsheet
由于nodejs 本身采用异步并行机制,里面就会出大量的event以及相关的trigger 可以用hack. 进行定制化。并且nodejs是应用框架与语言相互融合。 https://github.com/muicss/sentineljs 利用 @keyframes的动态rule来检测DOM中新加的结点。
关键是要理解浏览器的render机制。现在的机制你只管取数据,然后扔给浏览器的engine来进行rendering.
如何hacking这个rendering过程呢。
数组¶
https://github.com/waterlink/Challenge-Build-Your-Own-Array-In-Js,一个JS Array的测试集。
当前最流行的前沿技术,都有哪些各有什么特点¶
- single page application
Java script buffer,stream的概念不错,特别接近真实的数据结构。
http://v3.bootcss.com/ 用来生成UI的布局。 facebook 前端UI开发框架:React Angular.js 介绍及实践教程 主要GUI的控件与数据的绑定。
HTML5 下一代的HTML的规范,会有不少新特性。
如果对性能有更高的要求的可以用 https://infernojs.org/benchmarks
用nodejs来开发,就充分利用了html的灵活性来设计界面,同时nodejs又可以像传统编程来实现逻辑部分。
来实现各种 html的template 并且就像类一样,简版的react: https://github.com/mikeal/rza
PWA(Progressive Web Apps)¶
用来解决适配不同的终端以及不同网速的设计结构。 把原生应用与网络融合起来,即有原生应用的快速与灵活,又有联网的好处,就像各种新闻客户端一样。 并且已经有一些好用的框架。 例如 preactjs.com 在DOM封装了一层,同时体积非常小与快速。 https://preactjs.com/ 3kb atlternative to React.
快速原型建模打桩¶
API Mocker 接口管理系统 https://github.com/DXY-F2E/api-mocker, Graphql 接口管理采用基于字典对象的型式,可以方便的进行扩展与演化。 http://graphql.cn/ https://github.com/atulmy/fullstack-graphql
module 开发结构¶
清理临时文件的工具: https://github.com/tj/node-prune
Vue.js¶
浏览器的工作原理 对比原来的dom,找到最小编辑距离,然后修改,并进行重绘。 #. cdn url
v-bind:PROPERTY -> :Property v-on:Click -> @EVENT
v-if v-for
<script src="https://unpkg.com/vue"<script>
<div id="app">
{{ name }}
</div>
New Vue ({
el: "#app",
data: {
name : "max"
}
})
Vue.Component
- npm install -g vue-cli
webpack 相当于打包编译工具。 并且可优化代码。
React¶
利用用类对来对应网页,并且函数就是render()函数。利用面向对象的方式来构造网页。
npm -g create-react-app
react 的常用的一些设计模式 https://github.com/kentcdodds/advanced-react-patterns https://github.com/Heydon/inclusive-design-checklist
MEAN stack¶
Mongo,Express,Augular, Nodejs.
ReactX rxjs 异步处理库,类似于ajax.
storybook 不错 UI galaxy demo. https://storybook.js.org/examples/ https://github.com/storybooks/storybook 开源好用图标库 https://feathericons.com/
快速fix 避免半夜加班改,还是失败 所以deploy的代码最好也要用版本控制,关键是数据也可以回退:https://github.com/maxchehab/quickfix
Angular 2¶
npm install -g @angular/cli
ng new <new project>
- Single Page
- Update DOM
- Handles Routing(of visual Parts)
- Very reactive user experiences
ng-app,ng-xxx to binding things. .. image:: /content/Stage_1/JavascriptAndNodeJS.Angular2_cs.png
Javascript 的promise机制¶
生成二次回调机制,只有上一个调用成功,然后利用生成调用代码,然后再传给回调。 主要也就是MessageQeqeue再加上一个执行代码。特别适合建立异步的模拟机。是不是也特别适合区块链的 合约系统的开发。
对于半静态的event call,promise是一个不错的机制。
同时比回调函数更进了一步。就像有点像gl之类的操作。
var promise = getAsyncPromise("fileA.txt");
promise.then(function(result){}).catch(function(error){});
这些并不是执行顺序,这一点与一般的编程语言不同的点,代码的输写顺序 与执行顺序是不一致的。
css¶
随着HTML的发展,css也从原来静态的模式匹配,发展到变量等动态有sass,再到支持对象模板的less等。 同时网页动画,从最简单的css动画,到gl动画。有各种各样的库http://www.css88.com/archives/7389 轻量的渐变库,https://github.com/LiikeJS/Liike
直接利用scss来生成各种效果图,例如各种有机的效果图。https://github.com/picturepan2/devices.css
一种自定义的动态转场动化,可以基于地图位置的转场: https://github.com/codrops/AnimatedFrameSlideshow
https://github.com/Flaque/merchant.js 可以做无聊动画的框架类似于doodle.
正是由于 nodejs这种异步的机制,只要给出一个总量,以后异步计算增量就可以真实反映进步了。 https://github.com/sindresorhus/p-progress
如何快速描述一个掌握的技能,准备一个面试宝典,过一遍,就能完全理解。 例如 https://github.com/Pau1fitz/react-interview React 就是在DOM上面又封装了一层,VirtualDOM,并且这个DOM,对象化的,并且其rendering过程都是显式可控的。
node debug¶
直接采用的remote debug模式,node + chrome:inspect的模式。
在线调试器有 jsfiddle,codePen,以及各种动画的galxy等等可以用,https://www.zhihu.com/question/31731104
https://github.com/fhinkel/type-profile, 充分利用V8的特性,这样可以有效的提高troubleshoot的效率。
快速原型的方法¶
https://github.com/renatorib/react-powerplug ,采用Render Props的设计模式。
DashBoard¶
各种中DashBoard的框架。 https://jslancerteam.github.io/crystal-dashboard/#/ https://github.com/akveo/nebular
类型检查¶
https://github.com/sindresorhus/is, 可以进行类型检查,基于类型检测好处,就是量纲法可以有效的减少错误。 benchmark =========
对于各种framework,到底采用哪一个,最实用的标准之一,那就是性能对比。 https://github.com/krausest/js-framework-benchmark,performance的对比。
显示系统¶
PPT 可以采用 nodeppt来做, https://github.com/DracoBlue/markdown-papers
写出可以nodejs + asciidoc 可以参考 https://github.com/liubin/promises-book/
Test¶
javascript的自动化测试框架: https://github.com/jest-community/jest-runner-eslint
同时还有商业化的控件库http://www.grapecity.com.cn/developer/wijmojs#price
浏览器引擎¶

webkit

Mozilla 的 Gecko 呈现引擎主流程
渲染引擎会遍历渲染树,由用户界面后端层将每个节点绘制出来
按照合理的顺序合并图层然后显示到屏幕上。
浏览器刷新的频率大概是60次/秒, 也就是说刷新一次大概时间为16ms
如果浏览器对每一帧的渲染工作超过了这个时间, 页面的渲染就会出现卡顿的现象。
以上过程是渐进的,并不一定严格按照顺序执行的,为了更快将内容呈现在不屏幕中, 不会等到HTML全部解析完成之后才开始构建渲染树和layout,它会在不断接收和处理其他网络资源的同时,就开始部分内容的解析和渲染
渲染完成之后会触发 ready事件
什么情况下会引起 reflow repaint 当render tree (元素尺寸) 发生变化时则会重新layout 则会因此reflow.
浏览器首先下载html、css、js。 接着解析生成dom tree、rule tree和rendering tree。 再通过layout后渲染页面.
浏览器的内核是多线程的,它们在内核控制下相互配合以保持同步,一个浏览器至少实现三个常驻线程:JavaScript引擎线程,GUI渲染线程,浏览器事件触发线程

webkit
如何动画¶
动画的性能优化 https://www.w3cplus.com/animation/animation-performance.html
<div style="width:75%">
<canvas id="canvas"></canvas>
</div>
<script>
var color = Chart.helpers.color;
var scatterChartData = {
datasets: [{
label: 'My First dataset',
xAxisID: 'x-axis-1',
yAxisID: 'y-axis-1',
borderColor: window.chartColors.red,
backgroundColor: color(window.chartColors.red).alpha(0.2).rgbString(),
data: [{
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}]
}, {
label: 'My Second dataset',
xAxisID: 'x-axis-1',
yAxisID: 'y-axis-2',
borderColor: window.chartColors.blue,
backgroundColor: color(window.chartColors.blue).alpha(0.2).rgbString(),
data: [{
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}, {
x: randomScalingFactor(),
y: randomScalingFactor(),
}]
}]
};
window.onload = function() {
var ctx = document.getElementById('canvas').getContext('2d');
window.myScatter = Chart.Scatter(ctx, {
data: scatterChartData,
options: {
responsive: true,
hoverMode: 'nearest',
intersect: true,
title: {
display: true,
text: 'Chart.js Scatter Chart - Multi Axis'
},
scales: {
xAxes: [{
position: 'bottom',
gridLines: {
zeroLineColor: 'rgba(0,0,0,1)'
}
}],
yAxes: [{
type: 'linear',
// only linear but allow scale type registration. This allows extensions to exist solely for log scale for instance
display: true,
position: 'left',
id: 'y-axis-1',
}, {
type: 'linear',
// only linear but allow scale type registration. This allows extensions to exist solely for log scale for instance
display: true,
position: 'right',
reverse: true,
id: 'y-axis-2',
// grid line settings
gridLines: {
drawOnChartArea: false,
// only want the grid lines for one axis to show up
},
}],
}
}
});
}
;
document.getElementById('randomizeData').addEventListener('click', function() {
scatterChartData.datasets.forEach(function(dataset) {
dataset.data = dataset.data.map(function() {
return {
x: randomScalingFactor(),
y: randomScalingFactor()
};
});
});
window.myScatter.update();
});
</script>
每一个语言都是不断的向前发展的,C++ 已经有了11,14,17等版本。 慢慢就会把那些需要库的一些东东都吸收进来。 有点类假于C#的模式,会把设计模式的东东也都给融合进语言中来。 并且各个编译器的支持,可以参考 http://en.cppreference.com/w/cpp/compiler_support
语言娈量与指针以及各种作用域的定义,都是对内存管理的定义。而内存管理基本上上都是对引用技术的管理模式。 各种管理模型都是引用计数对种模型的适配。 看来计数是管理的一个开始。
类型转换¶
这个是各个语言,最灵活也是最难的部分。从最简单的说起。
- 长短整型转换。
- 整型与浮点型的转换。
- 字符串与数字之间转换
- 指针类型的转换。
- 类的的类型转换
最后两者也是最复杂的。也是各种反射机制的基础。 http://www.cnblogs.com/chio/archive/2007/07/18/822389.html
类的转换并且还有一定的规则。可以用强制转换,来实现一些hook的功能,例如hook某一个类的调用。这可以这么用。 动态链接库,就有了中间的搜索查找的过程,就有了Injector的空间。
C++ 现在支持一定的类型推导了,decltype 来得到目标的类型。
前置定义用途¶
与header的用途是一样的,都是为了编译器在编译的时候可以不用搜索全局,就知道所需要函数的原型是什么。头文件只是为欺骗编译器局部并行编译的方法。编译是可以并行,而目前链接可能是不行的。
一方面是用强耦合问题。 主要是用来解决编译的问题,由于走到当前,要求所有接口信息都要已知。但是现在需要东东,现在现在还没有编译怎么办。 这个怎么办呢,提前放一个stub。 这样就骗过编译。 但是骗不过linker. 因为linker是全局搜索的。如果连linker都骗过去,也就得再准备一分空函数库了。 然后在实际的运行的时候,再加上真实的库。 交叉编译就可以。 头文件就是这样一个作用。
从programming element来看的类,copy就是信息的传递修改的问题。
对于于不需要改变的变量,只需要传递引用就行了。没有必要生成一片内存,再copy就一样。 其实与文件的copy是一样的。 对于复杂的变量例如struct,以及class,这种大家伙来说,采用一刀切的方式显然效率不同。变样把结构分为变化问题,不变部分。 或者增量变量的部分。 面像对象的继承机制,可以看做这样的一种体现。例如基类基本上都是不变的部分。或者接口纯虚函数 无非函数指针。对于新增部分采用继承的方式。当然没有问题,对于override的也没有问题,有重载就行了。
而难点在于同一状态变量,要同时保存几个版本。例如Unreal中,Thread/Render中对象是共用的,但是为了加速,采用的异步机制。 至少double object的机制。计算当前的版本snapshoot一下,留给render,自己继续前进。 对于复杂结构更是如此。如何解决object的copy问题是个难点,如何又省内存,又高效呢。当然再简单的方法全部copy,也就是所谓的浅copy与深 copy的区别。
所以变量结构设计的时候,变量是可读,可写,以及读写方式与范围建模好好定义。这样方便后面的内存的管理,以及实现copy的问题,例如static相当于只读, 而moveable,相当于是可写。
对于一个简单的变量是没有这样大的区别的。像Unreal中这些object不一样的。后面那些pipline的优化也主要是基于static,moveable的能够区分开来为基础的。
对于 STL中实现的,写时copy也是基于这样认识。其实也很判断。凡是从内存读到寄存品上时,不需要变化,而要把内容写回内存的时候,就要换一个地址来写了。 这于部分的优化,那如何move,load指令的操作优化。可以统计move,load指令的做统计分析。move到内存寄存器的多的,说明只读的多,反过来,那就是只写的多。
同样是一段01序列,经过那么多层的传递,真的就需要那么多重复操作吗。
面象对象¶
- friend class
- 是为方便松耦合,方便合作类之间的相调用。例如正常情况下,comp 函数是不能访问私有变量的,但是frind之内就可能了。也解决全局函数与类之间的调用。
Class Test{
private:
int id;
string name;
public:
void print(){
cout << id << ":" << name << endl;
}
friend bool comp(const Test &a,const Test &b);
}
bool comp(const Test &a,const Test &b){
return a.name < b.name;
}
int main() {
vector<Test> tests;
sort(Tests.begin(),tests.begin()+2,comp);
}
C++ 11 新特性¶
typeid()
支持了lambda 表达式
类型推导关键字 auto,decltype
模板的大量改进 - 模板别名 - 外部模板实例
nullptr 解决原来C++中NULL的二义性。
序列for 循环,有点类似于foreach.
for(auto number: numbers){ cout << number << endl; }
变长参数的模板,tuple.
可以用{}来进行各种各样的初始化
default/delete 函数声明。https://www.ibm.com/developerworks/cn/aix/library/1212_lufang_c11new/index.html
lambda
auto pFunc=[]()->double {}; [](){}(); //call the lam int main() { int one =1; int two =2; int three =3; [one,two](){cout <<one<<","<<two<<endl;}{}; [=](){cout <<one<<","<<two<<endl;}{}; [=,&three](){cout <<one<<","<<two<<endl;}{}; [&](){cout <<one<<","<<two<<endl;}{}; [&,one](){cout <<one<<","<<two<<endl;}{}; }
functional class
class Check { public: bool operation()(string &test){ } } check1;
lambda mutable
Elision -fcopy-elision http://en.cppreference.com/w/cpp/language/copy_elision
构造函数可以相互调用。
rvalue and Rvalue &&Lvalaue
C++14 特性¶
- constexpr 表达式,可以把计算提前在编译阶段。
- 但是这样就会加长编译的时间
- 越来越有分段计算的能力, 计算现在能算的,不能算的放在以后算。
profiling¶
- 最简单的高精度计时
#include <chrono>
chrono::steady_clock::time_point t1= chrono::steady_clock::now();
// do something
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<dobule> time_used = chrono::duration_cast<chrono::duration<double>>(t2 -t1);
cout << "used:" << time_used.count() << "sec" << endl;
new/delete 与malloc/free¶
new /delete 在后台也是调用的malloc,free,但是多一些封装与检查。 https://github.com/lattera/glibc/blob/a2f34833b1042d5d8eeb263b4cf4caaea138c4ad/malloc/malloc.c glibc的实现。 主要是内存管理方式的不同。 http://blog.csdn.net/hzhzh007/article/details/6424638 #. 分配的速度。 #. 回收的速度。 #. 有线程的环境的行为。 #. 内存将要被用光时的行为。 #. 局部缓存。 #. 簿记(Bookkeeping)内存开销。 #. 虚拟内存环境中的行为。 #. 小的或者大的对象。 #. 实时保证。
著名的内存管理方式¶
Doug Lea Malloc:Doug Lea Malloc 实际上是完整的一组分配程序,其中包括 Doug Lea 的原始分配程序,GNU libc 分配程序和 ptmalloc。 Doug Lea 的分配程序有着与我们的版本非常类似的基本结构,但是它加入了索引,这使得搜索速度更快,并且可以将多个没有被使用的块组合为一个大的块。它还支持缓存, 以便更快地再次使用最近释放的内存。 ptmalloc 是 Doug Lea Malloc 的一个扩展版本,支持多线程。在本文后面的 参考资料 部分中,有一篇描述 Doug Lea 的 Malloc 实现的文章。 BSD Malloc:BSD Malloc 是随 4.2 BSD 发行的实现,包含在 FreeBSD 之中,这个分配程序可以从预先确实大小的对象构成的池中分配对象。它有一些用于对象大小的 size 类,这些对象的大小为 2 的若干次幂减去某一常数。所以,如果您请求给定大小的一个对象,它就简单地分配一个与之匹配的 size 类。这样就提供了一个快速的实现,但是可能会浪费内存。在 参考资料部分中,有一篇描述该实现的文章。 Hoard:编写 Hoard 的目标是使内存分配在多线程环境中进行得非常快。因此,它的构造以锁的使用为中心,从而使所有进程不必等待分配内存。它可以显著地加快那些进行很多分配和回收的多线程进程的速度。在 参考资料部分中,有一篇描述该实现的文章。
函数调用实现¶
对于结构化的传统语言,背后的堆栈的建立,参数排列,返回地址,堆栈消除等机制。
base class subobject 在derived class的原样性。也就是保证其内存结构一致性。包括填充位也要保留。
http://glgjing.github.io/blog/2015/01/03/c-plus-plus-xu-han-shu-qian-xi/ 当子类继承父类的虚函数时,子类会有自己的vtbl,如果子类只覆盖父类的一两个虚函数接口,子类vtbl的其余部分内容会与父类重复。这在如果存在大量的子类继承,且重写父类的虚函数接口只占总数的一小部分的情况下,会造成大量地址空间浪费。在一些GUI库上这种大量子类继承自同一父类且只覆盖其中一两个虚函数的情况是经常有的,这样就导致UI库的占用内存明显变大。 由于虚函数指针vptr的存在,虚函数也会增加该类的每个对象的体积。在单继承或没有继承的情况下,类的每个对象会多一个vptr指针的体积,也就是4个字节;在多继承的情况下,类的每个对象会多N个(N=包含虚函数的父类个数)vptr的体积,也就是4N个字节。当一个类的对象体积较大时,这个代价不是很明显,但当一个类的对象很轻量的时候,如成员变量只有4个字节,那么再加上4(或4N)个字节的vptr,对象的体积相当于翻了1(或N)倍,这个代价是非常大的。
对于不同抽象程度,存取的效率也是有区别,其实也还是用多少条指令。 额外的间接性会降低”把所有的处理都移到缓存器中执行”的优化能力。
inline in inline有可能失败。
C语言经典在于传统硬件模型与逻辑模型的分界线上。包括LLVM都是拿C语言的形式做为标准语言。
而C++实现把数据与操作bind在一起的功能,但是底层还是与C一样,用同样的ABI。但是通过编译器实现实现一些相当于元语言的操作,再加上编译器内部的结构。同时自动类的内存结构,来方便继承与修改。 而在C里,所有结构都要自己手工基于硬件模型来构造。 而c++则是基于逻辑模型来构造,然后由编译器当你构造出对应内存struct来,再加一些额外的overhead.c++自动给利用链表给添加不少东东。而在 C中这些都是自己明确实现的。
另外c++的成员函数指针,都是基于对象的偏移量,所以指针要加上类的类型。
C++的原理自己想实现的DSL的原理是一样,只是更加复杂了。高级语言要解决的问题,即要能保持高级语言的灵活与逻辑概念。同时又不产生的垃圾overhead代码到下一层的语义中。并且尽可能智能的化简。 或者可视化的理解让人们半手工来进行优化。C++是目前之这方面最好的。一个重要原因,就是基于C演化过来的。而C语言是对硬件抽象的最好,并且也是优化的效率最高的语言。 然而但C语言的这一点,慢慢就可以被LLVM来取代,所以目标,把DSL语言翻译成LLVM原语,然后再LLVM来进行优化,以及进行到硬件级别的优化。
明白每级语言向下翻译的基本原理,利用编译器+半手工调优,来实现性能与灵活性平衡。
不能在元函数中使用变量,编译期显然只可能接受静态定义的常量。
内存结构¶
http://www.cnblogs.com/kekec/archive/2013/01/27/2822872.html, c++的结构主要也是通过链表来实现。 并且也是多级,如果你只是用到一个类的很少一部分功能,但是还是要继承这个类,这样是很浪费内存空间的。 类型的改变只是改变了如果读那一段内存结构。
c++的内存结构解析类似于TCP/IP协议包的解析结构,都是采用头尾添加方式,root class就相当于最上长层协议包。 继承就是不断添加包头与包尾的方式。
泛型编程¶
http://blog.csdn.net/lightlater/article/details/5796719
泛化编程,相当于在编译当做运行了,只过其输出是代码,还需要进一步编译。 其实简单就像现在自己经常写的log,格式规整一点,直接就是另一种语言。 相当于让编译器帮你写代码的过程。 也就是进一步的符号编程。 变量/对象 -> 类/类型-> 符号
其实是大数据分析时,采用泛化编程就可以实现自我演化的图灵机了。通过聚类得到一些属性,然后自动组成生成代码,进一步的执行。这样不断的演化就可以了。
泛化编程是虽然图灵完备的。 但是由于当初发明模板时根本没想过基于它来编程。在实践中,泛型编程一般用于库级别的开发, 框架级的应用比较我少,应用级尽量少用。这样可以软件的管理复杂度。
泛化编程不单是可以只类型,可以任意你要替换的对象。
主要用来实现代码的排列组合。
模板本身,具有自变量的推导,但是不同类型参数的返回值是无法推导的。只能明确的给出。 同时支持模板多态的。但是这些选择都是编译的时候完成的,另一个模板的嵌套,等等。 以及模板的偏化。 同时支持 Typname具有subtpye.
模板核心就是特化匹配,并且就像M4一样,不断迭代替换,直到停机为止。 特别像haskell的模式匹配。
STL 还只是小儿科,而BOOST则是高级篇。
最灵活的模板那就是class的继承功能,只需要改动你需要改动的。
最低层的编码,就是编码,例如那些状态位,每一个位是都是有意义的。
模板的编译¶
也是类似于C的宏吗,还是编译自身的支持。 #. 包含模板编译模式。(这个是主流)。 #. 分离模板编译模式。
flow¶
- C++ source code
- Template Compiler
- c++ Compiler
- MachineCode
模板元编程¶
另一个那就是模板元编程,特别是模板的递归,它利用模板特化的能力。可以参考haskell的模式匹配,利用多态加模式匹配写状态机,不要太爽,用模式匹配解决了goto的问题,并且更加灵活,同时又解决避免了函数调用,有去有回的问题。 http://blog.csdn.net/mfcing/article/details/8819856,其实TypeList 也是一种模板元编程。 当然编译的是会限制递归的深度的,通用-ftemplate-depth来控制。
元编程模型也采用的函数式编程范式。 这里有框图http://www.cnblogs.com/liangliangh/p/4219879.html
- metainfo
- Member Traits
- Traits templates
- Traits Classes
- Lists and Trees as nested templates
- Metafunction
- Computing Numbers
- Computing Types IF<>,SWITCH<>,WHILE<>,DO<>,FOR<>.
- Computing Code EWHILE<>,EDO<>,EFOR<>
- Expression Template
多态的重载¶
多态调用的过程就是一个模式匹配的过程。 函数指针也就是指定了匹配模式。
非类型模板参数¶
所谓的模板也就是变量替换,不过在这个替换的条件,做出了更加细分的规则。 可以简单理解为一个全局常量的角色,只不过是在编译时计算出来的。经过这几天搜索,又一步一步的走到代码的演化。
TypeList¶
采用的函数式的定义,具有添加听说生成一个类型列表计算。 可以添加与替换其默认值。 并且在编译期间提供了一般list的绝大部分基本功能。 可以结合元编程理解这些东东。
如果你真的想不到typelist的用途,那是因为确实没有用到的需求,你知道有这个东西的存在就好了。有一天你碰到某个问题抓耳挠腮的时候,忽然想到typelist,马上就会用到火星的生产力耶。
http://blog.csdn.net/win2ks/article/details/6737587
对于模板参数也像位置参数一样,具有自变量推导(argument deducation)机制。
type_traits¶
http://blog.csdn.net/hpghy123456/article/details/7370522, 用了管理模板参数,往往参数之间会相一定的依赖有关系。可以相互的推导依赖,而根据这些信息可以生成更高效,更有针对性的代码。
如何添加汇编代码¶
如何手工写一个汇编函数, 只需要写个函数直接调用gcc来生成片断,直接直接插入就行。 其实也不需要只要掌握转换规则,直接利用LLVM 来进行代码分析。来优化生成汇编。
Functors¶
struct MatchTest{
bool operator()(string &text) {
return == "lion";
}
}
int main() {
MatchTet Pred;
string value = "lion";
cout << pred(value) << endl; // output 1
}
模板实例化¶
隐式实例化时,成员只有被引用到才进行实例化。
template argument deduction/substition failed¶
test@devtools-vm:/opt/libcvd$ make
g++ -O3 -I. -I. -INONE/include -g -Wall -Wextra -pipe -std=c++14 -ggdb -fPIC -mmmx -msse -msse -msse2 -msse3 -c cvd_src/convolution.cc -o cvd_src/convolution.o
cvd_src/convolution.cc: In function ‘void CVD::compute_van_vliet_scaled_d(double, double*)’:
cvd_src/convolution.cc:155:22: error: no matching function for call to ‘abs(double&)’
if (abs<double>(step) < 1e-6)
^
In file included from /usr/include/c++/5/random:38:0,
from /usr/include/c++/5/bits/stl_algo.h:66,
from /usr/include/c++/5/algorithm:62,
from ./cvd/convolution.h:8,
from cvd_src/convolution.cc:1:
/usr/include/c++/5/cmath:99:5: note: candidate: template<class _Tp> constexpr typename __gnu_cxx::__enable_if<std::__is_integer<_Tp>::__value, double>::__type std::abs(_Tp)
abs(_Tp __x)
^
/usr/include/c++/5/cmath:99:5: note: template argument deduction/substitution failed:
/usr/include/c++/5/cmath: In substitution of ‘template<class _Tp> constexpr typename __gnu_cxx::__enable_if<std::__is_integer<_Tp>::__value, double>::__type std::abs(_Tp) [with _Tp = double]’:
cvd_src/convolution.cc:155:22: required from here
/usr/include/c++/5/cmath:99:5: error: no type named ‘__type’ in ‘struct __gnu_cxx::__enable_if<false, double>’
Makefile:329: recipe for target 'cvd_src/convolution.o' failed
make: *** [cvd_src/convolution.o] Error 1
test@devtools-vm:/opt/libcvd$
解决办法,直接去cppreference.com中查找对应的库函数,并且找到example. 并且快速形成一个切面,进行troubleshoot. http://en.cppreference.com/w/cpp/language/template_argument_deduction
C/C++ 互调的方法¶
http://www.jianshu.com/p/8d3eb96e142a,主要是c++的函数名的特殊格式,利用extern C以及 #ifdef __cplusplus 来搞定。
IO模型¶

多线程¶
pthread_create 创建线程
pthread_setname_np 指定线程的名字
pthread_join 用来等待另一个另一个线程结束。 join相当于加入排队中。一个线程可以等多个。
pthread_create(tid1...) pthread_create(tid2...) pthread_create(tid3...) pthread_join(tid1) pthread_join(tid2) pthread_join(tid3)
pthread_detach
多线程的模型,主要与进程的状态相关

同步有机制有
互锁机制,主要用于共享内存的应用, 最经典例子就是火车的上洗手间。 http://pages.mtu.edu/~shene/NSF-3/e-Book/MUTEX/locks.html 其核心是使用计数与线程状态的操作。 主要是线程队列的policy规则,队列与进程之间最好的讲解那就是排队论。 但互斥锁应当仅由持有该锁的线程来解除锁定
- pthread_mute_lock
- pthread_mute_unlock
- pthread_mute_destroy
条件变量,更多用于流水线,stream上的应用更多的像通知。相当于银行VIP的排号。 VIP接待室时锁相当于mute_lock. 而条件变量就相当于那个排号。
- pthread_cond_t
- pthread_cond_wait 解销互斥量并停止线程。
- pthread_cond_signal, 如果一个线程对另一个条件变量调用pthread_cond_signals,
- pthread_cond_broadcast, 所有在排队的号信号都会被唤醒。
信号量,可以IPC也可以ITC。 只用计数来实现上数两个功能。铁路的道口。 https://docs.oracle.com/cd/E19253-01/819-7051/sync-95982/index.html 二进制信号量相当于mute_lock.
信号量是一个非负整数计数。信号量通常用来协调对资源的访问,其中信号计数会初始化为可用资源的数目。然后,线程在资源增加时会增加计数,在删除资源时会减小计数,这些操作都以原子方式执行。 如果信号计数变为零,则表明已无可用资源。计数为零时,尝试减小信号的线程会被阻塞,直到计数大于零为止. 线程池实现利用这个就会比较方便。同时可用于异步事件通知。
- sem_init(sem_t * _sem,int _pthsared,unsigned int _value))
- sem_post V增加引加引用计数
- sem_wait P操给信号量S的值减1,若结果不为负则P(S),否则等待。 执行V操作V(S)时,S的值加1,若结果不大于0则释放一个因执行P(S)而等待的线程。
- sem_destroy
void producer(buffer * b ,char item){ sem_wait(&b->empty); sem_wait(&b->pmut); b->buf[b->nextin]=item; b->nextin++; b->nextin %=BSIZE; sem_post(&b->pmut); sem_post(&b->occupied); } void consumer(buffer_t * b){ char item; sem_wait(&b->occupied); sem_wait(&b->cmut); item = b->buf[b->nextout]; b->nextout++; b->nextout %= BSIZE; sem_post(&b->cmut); sem_post(&b->empty); return (item); }
为了进一步提高效率,又分出读写锁的机制。读可以同时,写就必须是异步。
VHDL本身可以不是什么语言,只是硬件电路的描述语言,相当于FGPA的配置文件。描述了你何配置这些硬件资源。
FPGA 本质的并行性,大部分的操作都是并行的,主要是资源分配然后是其并行,基本处理流程就是信号也是电压的上升与下降来触发的时序。
流程¶
合成器, 相当于编译器的链接器的功能。把一个模块链接合成。
基本的数据类型¶
在FPGA中只有0,1而不同的数据类型,我可以让我们快速建模也来解释这些0,1,例如整 型,浮点型。
Signals Vriable Constants Variable Files
每一个数据类型代表一种数据常度,用于bit来记,并且同时定义了编码类型,这些代表了各种标准。
downto, upto
三种设计模式¶
- 结构化
- 行为模式
- 数据流
news¶
Efinix可编程芯片:可进一步推动人工智能技术发展 http://www.kejilie.com/leiphone/article/nIvmyq.html