效率篇¶
基本问题¶
工欲善其事,必先利其器。知其然,并知所以然。 然而加速那个过程。达到快速高效。 而代码的本身的技巧与工作量应该越小越好,把时间留给思考。
每一个事情都是可以有周期分阶段.

- 快速的运行起来,看到其整体的运行框架。
- 通过可视化的trace 来理解运行过程
- 能够从源码编译。
- 添加各种profiling的参数
- 如何优化
- 能够快速debug,
- 能够扩展,并且快速测试
- 快速的部署
- 如何快速的写代码
- 如何build 与优化 跨平台
- 如何调试
源码编译¶
- 各种依赖库的寻找与安装
- 编译本身,并行编译
- 编译除错, 各种编译的选项的设置 由于编译环境与原始环境不同,经常需要各种调试
- 源码的重要性,在出现问题之后,并且通过google也找不到的答案的时候,这时候最高兴的莫过于,编译一个debug版本,条件断点,一次命中的检查环境。 如果是脚本语言,那则更加方便的,直接利用解释器的断点指令来进行调试更加的方便。
调试¶
如何加快自己能够快速的速度。 最浪费的时间的地方,那就是一遍遍重复调试,因为只要复杂一些工程,整个环境搭建可能就需要很长的时间。减少重复调试的时间。 另外是充分利用中间产物,这样代码完成之时,也是第一次的整个流程完成时间。这样也就可以 保证增量开发。不然的话,等你开发完成,你需要完成的工作还没有开始。离真正的完成,之前,你还得修一轮bug,然后是运行完成所对应的任务。 基本是三倍的时间。如何将其降为一倍的生产率。
- 弄清楚整个流程
- 哪一个部分最耗时与资源,分配最多的资源。同时使自己的工程能够断点续传的功能。主要是添加一些log与status的存储的功能。 每一步要考虑模化化,例如下载的功能完成之后,就可以让其开始下载资源,而非等到最后最开始下载。
扩展开发¶
- 如何加快自己的实现编码速度。
- 生成代码
- 自己实现代码就要利用IDE工具的拼写检查,语法检查,以及自动补齐功能,来加快自己的速度。
- 找到一个template快速的运行起来,这个要不了多少时间。
- 而真正花时间的,是自己代码的逻辑设计,例如一个简单的数据迁移从trac到fogbugz,原理简单,但是用了4-5小时才完成。 主要是因为mapping关系的设计,这个需要拿到准确的数据。 原来只会用命令行的数据库来试,浪费了不少时间。没什么比可以视化的工具能更加方便的上手开始工作了。
- 参数环境的配置
- 设置一个 ROOT,TOP dir. 然后所有的文件路径以此为基础。并且这个路径也又可以命令行参数来改。
- log 即要有console,logfile。 log的分级标准
- 能够显示系统流程的用info,通过info信息可以一眼看出,现在执行到哪里,可以把log来代替注释。
- 把log当做测试。 把info当做testcase级别的信息,而把debug当做step级别的信息。
- 快速建立一个开发与测试环境。利用agile这样,实现一下快速开发的教程。最好是开发与测试能够并行。这样能快速发布一个版本。 这样可以大大地提高开发,测试与部署的并行化。 在文章与各种资料的不全的情况下,没有什么什么比一个可视化的debugger连接上去,给你一个快速的验证调试环境。 这个的速度可以的一遍一遍的print+log要高3倍以上。 在debugger的环境下,可以一遍一遍的重复,而不用害怕crash的问题,并且弄清楚API的使用方法。
- 生成代码的时候
- 尽可能使用IDE减少语法错误,与拼写错误。
- 使用一种命名规则,长短不重要,关键是统一。这样可以减少大量的错误,尽可能避免同一类变量使用不同的命名规则与缩写。 这样会引起大量的莫名其妙的错误。
IDE¶
最浪费时间的事情,莫过于,等10分钟以上,只是发现了一个拼写错误,并且一天的时间也只是解决了一些基本的语法错误。
所以在不同平台,就要使用最优化的工具来提搞效率。
对于编辑器,可视化与结构化,并且尽可能所写即所得。来加快编码的速度。 例如lighttable,以及visual code online的功能。
- 支持语法检查
- 自动补齐
- 拼写检查
- 支持重构
要想在每一个阶段达到用到最好的功具,那就需要各种灵活的配合,对于linux平台的开发,最要命的那就IDE的缺乏。现在 VS2017已经支持在linux在windows编辑,直接在linux直接编译。但是导入的模板不不是很好。不过现在github已经有一个 vclinux来帮助我们生成 vc 的工程,另一个快速的方法,那就是利用VSCODE 直接打开目录。 https://github.com/gwli/vclinux 其实这种工程的文件的生成也很简单。直接拿一个生成好的工程,然后把不变部分当做 template,可变部分,变量控制生成就行了。用一个template应该是在15分钟之内就可以完成的工程。
$ ./genvcxproj.sh ~/repos/preciouscode/ preciouscode.vcxproj
# set build command
cd ~/repos/preciouscode/; make
$ ./genfilters.sh ~/repos/preciouscode/ preciouscode.vcxproj.filters
另一个特别好用的工具那就是visualGDB 的VS 的插件,非常的周到全面。
对比工具目前最强beyond compare.¶
直接目录对比,双击文件,再自动转入文件对比。这样可以大大减少overhead.
另一个对比的办法,那就是利用 git. 把基准当做一个版本,然后另一个当做改动来进行对比。
VS for Linux¶
http://hongbomin.com/2017/03/10/using-visual-studio-as-linux-develop-IDE/
#. vs不会自动把addtional include中的头文件复制到本地来做代码补全的提示,需要手动将linux下面的/usr/include、/usr/local/include等目录复制到vs的linux header path(如:C:Program Files (x86)Microsoft Visual Studio2017CommunityCommon7IDEVCLinuxincludeusr) 头文件包含目录和库文件包含目录均为linux下的绝对路径
Build tool¶
build 本质,一个是翻译,一个链接,然后就是各种格式输出生成。当然在这个过程中也就大量的依赖树的生成。最简单一条指指令,到几条指令组成的指令块。 然后是这些依赖关系。再加上CPU的存取机制。 都是可以精确的建立一个模型。
build的难点在于各种依赖的管理,另一个那就是并行化的加速。 在需求与硬件之间的一个平衡那就是pool.
依赖的管理现在都是参考包管理的机制来进行的。现在基本是至少一个 group,componmentname,version 再加上依赖,以及一些auother,maintainer等等元信息就够了。
如何才能使翻译速度做到1分种之内就能够完成呢。
然后就是指定一个cache这样不用每一次都从云端开始下载。 在编译的过程,可能是一遍扫描,也可能是多遍扫描来实现的。 如果只用一遍扫描的话,那就要求大部分的信息都是局部化的。 多步扫描就可以利用全局的各信息。 而LLVM的优化就是采用这种多遍扫描,特别是优化这一块,可以是任意多次的扫描。
另外build的 pipeline的定义以最基本的有两个project,task. 这样每一个project与task之间都可以依赖关系。并且随时可以从中间重启。
工具的意义,管理文件本身的依赖。管理内部的库依赖。 并且能够并行编译,大大的减少编译的时间。大的工程编译也是特别耗时的。 特别是修改,编译,调试。 这样的循环中,会非常的浪费时间。
快速的修改,快速的编译,快速的调试。
ant 的语法没有make 那样直白。
如何用ant 给aapt 传递参数呢
https://code.google.com/p/android/issues/detail?id=23894。
一个问题是自己为什么没有找到这个答案呢, ant/build.xml自己也读了。一个原因那就是没有问题提炼出来,compress 这个关键词,如果知道了这个。这个本问题简单的。
把问题 提炼成 一句话,甚至是关键词。
而java的编译选项主要是 Java.source与Java.target 详细的文档在http://docs.oracle.com/javase/6/docs/technotes/tools/windows/javac.html
所谓的build,除了编译本身,还有其他的做准备工作,例如把相关的资源也copy到对应的目录。同时做一些预处理。 编译本身,也就是指定一下头文件,以及搜索路径,同样对于库也是如此,另一个循环依赖的问题,那就只能前置声明来解决了。 没有什么特殊的东东。
其本质就是
build {
set-evn;
for * build { do each item}
}
copy something
process the resource
generate final package
对于MSBUILD例如一些库,你只是需要copy到输入目录,直接添加一个reference就直接copy过去了。 只在对应的类里添加一个文件名,或者新建一个task,并且指定一下,前后的依赖关系。 或者http://stackoverflow.com/questions/1292351/including-content-files-in-csproj-that-are-outside-the-project-cone http://stackoverflow.com/questions/7643615/how-can-i-get-msbuild-to-copy-all-files-marked-as-content-to-a-folder-preservin
代码阅读¶
如何快速理解,大的代码框架。 最好的方法,猜想+验证。 通过读代码来找到框架这个方法是最笨的方法。 通过文档,以及理论原理,就可以把框架猜的差不多。具体的操作,可以通过工具来加速。 例如VisualStudio可以动态的得到CodeMap,同时能够集成github直接查看版本记录。还能直接看动态内存使用信息。 已经把自己想要把debugger与profiler放在一起的时候给做了。
并且在一些关键的点加上一些断点与trace就知道其所以然了。没有必要一行一行代码去看。 因为代码中大量的参数检查以及其他等等会影响你的逻辑。
debugger + profiler + CodeMap/Framework原理图,就够了。
当然你需要大量的知识的框架知识,或者可以快速获取相关知识。 #. 如何快速读懂代码找到框架这个很重要。 #. 一些问题,只看到代码一眼,就能明白知道答案 #. 看了代码,还不能快速明白的事情,那就要添加测试,通过猜想验证,设计测试用例。设计测试用例的过程,就像猜想+理解的过程。这个符合人的认知过程。直接在debugger中添加一些测试这样对原代码影响较小,那外的那就是利用宏+NVTX。以及专用的debugger,它可以支持特别数据的可视化。或者直接python 的画图与显示工具。
读代码的过程与代码的过程本质就是不断在设计结构与算法之间不断trade off的过程。而读代码是一个反向工程,那就要不断猜想验证。 就像反向工程一样,一样的思维不一样的实现而己。
- 看论文以及介绍文档,再加上自己的思考得到一个大致的流程
- 拿到code编译能跑, 看看它都用到什么库,从而也就知道需要哪些相关的知识
- tracing,通过timeline 就可以看到其pipline了。可以通过callstack,来选择一个函数当做NVTX不行,不需要事先加NVTX.
- profiling 以及加论文,来从重点入手。 充分利用profiling 工具来达到trace信息,并通过定制化,把一些关键点上的数据截流可视化。这样就可以大加快自己的速度 。充分利用下一层接口工具。
- debuging + 可视化分析,来突破重点难点。 例如,在复杂的数据结构。这样就需要一个很好的可视化工具来帮助理解。 一个好的流图,不同层级的示意图,源码都可以了跑起来,就一定能让源码告诉你一切。 如何代码返回公式
- 分析总结各个过程,来实现全流程的优化。并且出论文与专利与自身的效能的提升。
什么情况下算完成¶
工具的使用¶
如何快速的写出文档¶
- 禅道项目管理式具
- ` Doxygen + Graphviz + Htmlhelp, 成为文档好手。 <http://blog.csdn.net/cuijpus/archive/2008/05/22/2471014.aspx>`_
- KFI与Graphviz分析内核
- KFT(Kernal Function Trace)
如何使用Graphviz¶
要逐渐开始使用这个dot语言,这个语言本身就像基他标记语言一样简单。其基本组成就是由图,结点,边,组成。再加上嵌套的子图来完成.在这里几种不同布线方式。其实这就像VerilogHDL一样,这样可以产生布线。同时使自己想起了画电路板。那里边就有一个自动布线的功能。要充分利用这些功能。同时在也学到了一种linux的思想,WYTIWYG(what you think is what get). 这个不同于微软的思想,所见既所得。
- 如何布局与联线
- 这个语言本身很简单,就是图,结点,边组成。同时他们也实现了几种布线方式。在布线的时候,可以这样干,可以试试几种方式。然后再决定使用哪一种.在使用的时候可以在库中找一个类似的图,然后再看看怎么实现的。然后拿来自己用。就采用cas的那个gui的界面的开发与学习方法。这样就会越来越精通。
- group,id of graphviz how to use them?
- visualization of Information
- 用 Graphviz 可视化函数调用
resource¶
- 一个经历超过十万行代码的Scrum项目经验谈
- addison.wesley.code.reading.the.open.source.perspective.chm : addison.wesley.code.reading.the.open.source.perspective.chm
HowToDebug¶
调试程序方法有很多,但最重要的是自己的思考。再好的工具的工具都不能取代你的思考。 调试的速度与精确度 思考 + 经验+实践+良好的系统知识。
gdb step 也是为了你的思考验证来准备的。通过log来分析,search才及动态的分析工具 都是为了你的思考。思考要用事实来验证,并且要基于事实,并且事实来突破自己的思维局限。 最难的那就是 mental model bugs. 在你认为最不可能出错的地方出错了。并且这种错误一般都是由引低级的错误引起来, 例如 语言中逻辑操作码的一些优先级引起的。 当遇到这种问题,要寻求外部的帮助。同时要意识可能是mental model 出错了。
思考什么呢,因果联系,这是最重要也是最基本的联系。 可以通过自己的常识不断细化这种因果联系。当然也可以即时从google上学习来的。 例如能够can’t break on sigfpe,就要能够快速学习相关知识来进一步的推理,能够判断出这个是硬件的问题。 https://devtalk.nvidia.com/default/topic/832136/nsight-tegra-visual-studio-edition/cannot-break-on-sigfpe/
原则 debugging is an art that we will practice regularly, The first thing to do is to think hard about the clues it presents. If there aren’t good clues, hard thinking is still the best step, to be followed by systematic attemps to narrow down the location of the problem.
– The Practice of Programming Page 145
- Examine the most recent change. 如果使用vs2015的话,内部集成这些git可以快速查看修改。
- Don’t make the same mistake twice. 修改的时候,最好用重构代替copy,并且进行搜索查看。反复的修改同一个问题,例如同一个问题提交很多版本会令人沮丧的。
- Debug it now, not later. 尽可能修复当前所有遇到crash以及己知问题。 因为这为后来提供更干净的环境。根据复利的计算,bug的修复越及时,成本越低。最起码不用 再手工清理恢复环境。
- Get a stack trace. 最重要的信息。
- read before typing. 多思考后动手。再没有思路的时候停下来,休息,然后再进行。
- Explain your code to someone else. 帮助自己理思路
- 发现别人的bug时,确定这个在最新version能够重现。 一般不会在一个老的版本中去修一个问题。
- 当给别人提bug时,站在owner的角度想想需要什么东东。
同时快速修复一个别人的bug时,也是根据这个原则来的。
- 看一个修改的时候历史。
- 查找一个变量的引用到的地方。
- 查看一下函数引用到地方。 就差不多,可以确定如何修改了。所以修一个bug,没有重构那么难。
- 看了解一下整体结构,看看要不要重构。 整个过程不要超过两个小时。
当遇到没有线索bugs时
- Make the bug reproducible. 然后统计分析规律(study the numerology of failures),然后narrow down问题。
- Divid and conquer, 采用二分法来narrow down.例如利用vim的undo功能,特别适合这个。 例如加入log, 例如执行到这里了。 并且记录这个过程。 当然git也支持2分法在版本之间查找。 即使是一时不出来原因,做好记录也可以为以后分析做积累。
当然这些原则再加上debugger会加速你的问题。
- 另外添加一些有用的self-checking code。也会加速你的问题解决。 并且能够把你的收集信息可视化,会大大加快你的速度。 这一点vs2015中可以在debug时生成codemap,并且随着step不断更新你的这个图。 把callstack不断可视化。 这个也可以用gdb + graphviz 来自己实现一个。
- 写好log,是你解决问题时信息的最大来源。当然对于大的工程没有现成的log可用时,可以debugger的trace功能以及profiling来产生规范的log,然后再加上自己的可视化分析。尤其是可视化可以大大地加快你的思索。
当代码在一个机器时正常,而在另一台机器不正常。 这个一般是由于环境引起的。 例如查看环境变量,以及依赖的库的版本。一些相关配置文件。 还有的那就是一些随机输入。 还有那就是共享变量,一些全局变量,无意中被不相关的东东给改掉了。 这是你采用链式逻辑推导不出来的。 这个时候就要用trace 变化来实现了。例如可以定时或者实时从 /proc/envinron 中获取这些信息。
- 要知道什么是对的,每一步中。 排除不确定因素。 特别是一些变量,指针没有初始化。使其处于未定状态。变量作用域的传递问题。 这些都是极其容易出问题的地方。
- 遇到sometimes问题,最好的办法,详细的log或者直接生成coredump,这样就能清晰的context了。 再加上合适的工具grep,diff,以及可视化工具等等。
调试程序很多方法,解决问题的最重要的方法,那就是不断narrow down,直到减少范围,直到找到root cause, 用log,debug能快速得到callstack等等线索。 因为模式设计就那几种,自己停下来想想,按照概率最大蒙也蒙的出来。 如果不能,选模块的分割,再了解流程再进一步narrow down. 就像修改那个 CMake 生成 Deploy 选项一样。 最终就只需要 else 语句就搞定了。
一个难点,那就是搭建调试环境,只要方便。最好方法那就是能在出错地方停下来(例如像pdb.set_trace()这样的功能最方便),即使不能可以打log.
调试器虽然可以用step by step,但是主要功能可不是在这里,最高效的功能在捕捉异常。所以重点是exeption,core处理,以及各种事件的支持,例如 .so load event.例如
- 自动停在main处
- 例如cuda 的自动停在kernel launch 处
- 自动停在出错那一行,尤其是cuda-memory等工具结合的时候。
set print thread-events.
如果能到源代码¶
- 添加编译选项使其具画出call_graphic. 或者直接使用 VS中智能分析出来的。
- 能否换成clang编译来优化一下代码。
- framework pipepline 查起。然后不断的narrow down.
- 通过读源码就得到答案,遇到问题,就要能够去想哪里出了问题。然后来猜想加验证。
strace and sreplay¶
应用程序分两大部分,一个是自身的计算,另一个是外面的调用,error信息肯定会体现在下层的调用上。 所以出错的时候,看一下一层的API log一般都会发现原因的。
strace 与 sreplay 可以抓取系统调用并且能够回放。例子见[streplay]_
| [sreplay] | http://people.seas.harvard.edu/~apw/sreplay/ |
如何让自己的程序变的动态可调试¶
- 在自己的代码中全用 命令行参数处理 以及 logging等级处理 例如syslog,以及NLOG等的使用。
- C 语言中可以采用
assert()函数来定制调试,并且这些是通过宏控制的。打印出错信息。然后限出。 - 每一个系统都会支持各种event,在处理前后都加上hook来capture. 同时也可以利用signal自己生成coredump.或者等待debugger连接上来,就像windows这样,只是一个hook而己。
- 另一种方式那就是把内存当成一个存储系统并在上面加载一个文件系统。这样就可以高效的存储了。充分利用各种cache. 例如debugfs,tempfs,/proc/ 都是直接存储做到内存上。可以非常方便查询各种信息。
- 充分利用配制信息,windows与linux是越来越像,都开始在home目录下写各种配制了。
- 对于windows还可以用debugView来查看这些调试log.
- 充分利用条件断点来添加log and trace.
process monitor可以实时显示文件系统,注册表和线程的活动。
如何调试并行调试¶
这个可以参考CUDA的并行调试。一个重要问题那就是对线程的控制,CUDA提供了基于lanes,warp,block,grid的,以及任意的frezen/thaw,以及支持与与或非的查询条件。可以方便过滤那些thread的查看。
调试都需要信息¶
debug Symbols 信息,有了符号表才能符号表地址对应起来,并且还源码对应起来了。对于GDB来说,那就需要设置 symbols directory, 另外那就是源码目录。还有那就是如何起动。 当调试环境与编译环境不一样.symbol path 是对应不起来的。 可以在 set substistute-path /afafa/fadfa /xxxxx 来解决这个问题。 for apk, they need androidManifest.xml to get the package name to start it.
signal¶
也就是kernel发现在东东,来通知应用程序来处理, 例如键盘有了输入,硬件中断在软件就叫signal. 也不是操作系统告诉你发生了什么事情,至于你怎么处理那是你的事情,除了一些标准的消息kernel会强制处理之外,例如kill -9 等等。 exception,就是kernel发现你做错了来通知你。你丫搞杂了。可以用kill -l 就可以看到所消息。 kernel与进程的通信,就是靠这些signal中,这些是模枋interrupt的。有些标准的signal,也有些预留的。例如进程什么停止,kernel都是利用这些signal来通知进程的。
条件断点使用¶
断点的本质,那就是各种event,例如库的加载与卸载。以及系统的其他event,callback. 道理早就懂,但是用的时候就想不起来,一个原则,那就是尽可能停下来地方尽可能接近出错的地方,包括时间与空间。再简单的场景: 你实现了一本功能,有很地方会用到它,突然其中一个调用crash了,或者出了问题。直接下断点,就会在没有crash的地方停下,停下来n多次。这个时间就需要加一些条件来帮助你停下来。
- 如果有明确的信息可以知道在什么条件下会出现,例如其caller,或者某个具体值,直接上条件断点。直接停到最佳地方,而不是手工去点next.
- 如果事先没有明确信息,可以先用trace的功能,打印出前后上下的context信息。 然后再根据这些信息设置条件断点。
- 充分利用数据断点,可以来快速调查被非法读写的内存块,数据断点,当内存被读写的时候,就会被停下来。
所以快速的解决应该最多三步就能搞定。
- 搭建环境,只需要重新编译一个代码加载symbols。
- 明确断点信息。 然后利用trace 的功能,来打印各种想要的信息,而不需要再改动代码。对于大的工程build是需要很长的赶时间的
- 停到最佳位置。直接用条件断点停到这个位置。是一部分到位。或者直接让gdb来hook signal或者exception是同样的道理。
#. 在第二步与三步之间采用二分法,无限细分下去,直到找到原因。 因为经常出错的事,我们分开验证A,B两部,都是正确的,但是合在一起就会出错。但是这两者已经离的很近了,并且或者从经验上认为是一致了。感觉已经没有办法了。实在是想不出来是哪里出错。 而实际上就是这个细微的差别出现的问题。 就像我自己项目中 从逻辑上,大的功能块上 二分,到代码行二分,再进一步到汇编指令二分。大部分时候,大家只能走到逻辑上二分,就以为到头了。
并条件断点处,打一些trace,再加上timestamp信息,格式再好一些,就可以直接profiling了. 例如在Visual 中,可以用$TICK 来打印出CPU的TICT, 对于gdb就更灵活了,各种shell命令可以用.同时python的集成. 还外也可以直接借用app本身的一些全局变量,Log模块也就可以.这样就不需要修改源码本身,就可以profiling了. 有了这个可以直接定位问题.如果能配合录屏软件时间坐标就更精确了.
例外对于一些profiling工具,如果能提供api 查找,并且显示其对应的timeline那就更方便了. 如果不行的话,又不想写代码,又想让app停在 某个位置,那个时候就要到debugger,pause的功能.如何这些功能整合在一起呢. 用expect +gdb + shell就可以搞定这一切了.
debugSymbols¶
机器在做什么,都是通过代码休现的,代码显示就是那些函数名了,通过debugsybols可以机制码与可读性代码连接起来了,方便人们理解 机器正在做什么,即使是release也是可以生成symbols的.
在大的功能快,module上二分这是逻辑问题,具体到源代码这一级,还是逻辑问题,到汇编这一级,那就是性能问题。从汇编到机器码,那就是ABI,机器构架之间的区别了。
system("fadfa")
exit(0)
实际代码中在system(“fadfa”)就已经crash了,但已经还是想当然以为exit(0)执行了。
如何在exception与handler里debug¶
特别是crash时,能够看到当前的callstack等等,并且来改变程序运行顺序,这个时候 就需要debugger,来捕捉exception and signal了。 一个最重要那就是拿到callstack,另外无非的情况那就是非法地址,首先是其owner是谁先打这个符号,例如oglContext这个值成为空词,自然对成员的访问会出错,所以这个值哪来的。我应该期望的值是多少。 根据地址段来分析可能出错。是数据本身出错,函数回指针出错。 然后根据地址来得符号表,这个地址是哪一段出现的。这个时候就需要debugger连接上去,然后hook这些exception然后就让他开始他。并且debugger attach上去之后,可以看到更多的信息。 http://www.read.seas.harvard.edu/~kohler/class/aosref/i386/s12_03.htm
SIGSEGV¶
出现段错误,指针不对, http://stackoverflow.com/questions/1564372/what-is-sigsegv-run-time-error-in-c 也就是adddress不对,读取不不该读取的地方。 https://en.wikipedia.org/wiki/Segmentation_fault
如何搭建环境¶
其实也就是现场截面的恢复。其实就是现场中断与恢复。以前也只是说一说,现在看来用到实际中了。
大的应用程序,那就是保存其环境变量以及输入与输出。 就可以直接切入环境,而不需要从头运行需要大量的时间。
对一个函数来说,也就是输入输出,以及相关的全局变量而己。而这些都是可以通过trace来得到。
还有那就是利用coredump与debug symbol来恢复现场。 例如gdb,先加载debug symbol,然后再打开coredump就可以了。 另外那就是让crash的程序自动生成dump文件,或者发生特定的事件的情况下生成dump文件,在windows就要用debug diagnostic tools了。对于linux 可以用gcore来生成,或者gdb里面也可以生成。 也可以用ulimit来指定。或者用signal SIGBRT,或者调用abort()函数就可以直接生成。 http://stackoverflow.com/questions/131439/how-can-a-c-program-produce-a-core-dump-of-itself-without-terminating/131539#131539 http://stackoverflow.com/questions/318647/what-is-a-good-way-to-dump-a-linux-core-file-from-inside-a-process http://www.codeproject.com/Articles/816527/Writing-Custom-Information-in-Linux-Core-dump-usin
同时glibc同时也开放一个backtrace的函数来得到callstack. http://skyscribe.github.io/blog/2012/11/27/linuxshang-ru-he-cong-c-plus-plus-cheng-xu-zhong-huo-qu-backtracexin-xi/
出了错了,另一个查找错误的方法,那就是读代码,如何读,通过版本的对比,同时根据依赖关系,得出一些改动的真实原因。 这时候就需要各种diff,快速编辑,以及快速navigate 同时能够做各种依赖关系的的工具。 脚本,vim,idff,vscode, git等等都是重要的工具。
NPE¶
NPE Null pointer exception.
Can’t Find resource¶
经常遇到这样的问题,例如undefined symbols,找不到的库。例如C#遇到找不到XX14.0.dll. 这样的原因有以下几种:
- 确实不存在对应的库
- 所依赖的库存在,只是依赖库的Error处理的不好,没有正确的显示
- 库确实存在,但是版本不对,有些依赖是版本要求的,所以搜索的条件也不一样。所以要仔细看它的搜索条件。
- 由于不同版本之间不兼容,例如函数名的改变,或者编译器不同而导致的格式改变。
解决办法
- 最简单的办法,在对应的目录里直接搜索,然后查看其版本信息等等。
- 用LDD 查看其依赖。 windows下用dumpbin 来查看。
#. 对于C#可以用FusionLogViewer来查看。 http://www.hanselman.com/blog/BackToBasicsUsingFusionLogViewerToDebugObscureLoaderErrors.aspx #. 最差写一个wraper来测试,直接debugger来查。
如果查看内存分配¶
如果精确查看进程的内存分配呢,在linux下有强大的 /proc 可以用,另一个方法,自己根据结构直接读内存。
从memoryWindow可以直接查看各个地址,并且还可以转换基本格式,像graphic debugger里那样显示texture
都是读取内存数据来得到的。同时还可以用来研究自动变量的分配。并且一些数据转换,例如整型,浮点型的转换,format
这些都是可以在memoryWindow直接做的。直接修改内存值。
进程数据存放无非两种,放在内存里,或者寄存器里。
内存泄漏可以inject内存管理函数,并且建立自己内存管理模型来进行监测,所谓的代码插装,在源码级别可以预处理的宏替换来实现,那就像MFC的那个消息结构一样。在宏替换原来内存管理函数后,同时利用 _FILE_, _LINE_,_FUNC_来获得动态分配函数所在的context信息。 利用exception + __FILE__,__LINE__,__FUNC__来得到callstack以及文件的对应关系。
strings的使用¶
在二制文件中查找error信息时会很有用。为什么呢,因为代码中一些字符串信息也都存储在binary中。只是编码不同的而己。
如何Goto¶
在大的工程里,因为一个小错误在重头来过,有点得浪费,怎么办呢,直接修改了,然后直接跳过去,这个是函数调用不能解决的。 只能goto才能解决的。 goto解决方法,当然用指令,另一种那就是直接修改PC寄存器值。 在Visual Studio中,那就是set Next Instruction的功能。 http://www.cprogramming.com/tutorial/visual_studio_tips.html。
利用python plugin¶
以自定的命令,再加上各种command的hooks来实现 各种测试与与调试信息。 充分利用这些可以大大减少harness的准备的工作。
对于大的并行程序,有专门的profiling与debugging工具,例如 http://www.roguewave.com/products-services/totalview
如果调查crash¶
查看log时, 有很多error,一定要找到第一个error. 就是编程时,要从第一个error来解决开始。 在查看error时,最简单的办法,那就用时间戳来决定。
minidump¶
目标是为生成一个最小的包含问题的可执行程序,这样可以大大加快troubleshot步法,特别是对于程序,每一次repro都会浪费大量的时间。 如果生成这样一个程序切片,就可以大大加快troubleshot的效度。
SIGILL¶
一些warning也会产生一些运行时错误,不要轻易忽略编译中warning. 尤其是那些类型转换 https://peeterjoot.wordpress.com/2010/05/26/a-fun-and-curious-dig-gcc-generation-of-a-ud2a-instruction-sigill/
GDB 调试¶
Introduction¶
gdb 操作,相当于直接操作CPU与内存。 CPU的状态是可以通过寄存器的状态来进行控制的。例如set next step, 相当于修改 PC,IP 寄存器值。
debug都是基于debugsymbol中,这个symbol会存储debug与source code line num 的对应关系。 断点不能hit,也就是没有dbgsymbol没有,或者你的源码位置与dymbols中是不一致的。
如果首先看没有debugsymbol, sharelibs. 然后 info lines. 就知道了。 如果不匹配,会发生在build的机器与调试机器的环境的不同。 或者当时生成不是相对路径,或者现在相对路径不对。
可以修改相对路径,或者直接替换路径,例如下面
apt-get source linux-image-2.6.32-25-generic
apt-get install linux-image-2.6.32-25-generic-dbgsym
gdb /usr/lib/debug/root/vmlinux-2.6.32-25-generic
(gdb) list schedule
(gdb) set substitute-path /build/buildd/linux-2.6.32 /home/xxx/src/linux-26.3.32
同时可以用 objdump -Wl <lib> 来查看其path是否正确,特别//,\ 这些分界符还有的那就是相对路径。
debug 的难点¶
- 如何在别人不能断的地方进行断点设置。列如线程调试、远程调试,对正在运行的程序进行调试、gdb是可以的。
- 如何理解对象的逻辑结构,进行快速地诊断。
- 能够查看当前正在运行的调用stack,通过这些可以跟踪程序的内部运行机制。只要知道了原理,然后直接debug就可以得到更加真实可靠的知识,更快的方法是猜想+验证。 找几个具有特征点来看一下其调用关系。例如正常运行,以及特殊情况下,调用关系。同时在不同的时间调用关系,就可以得到系统运行的立体信息。
- 同时debug工具能够提供汇编代码与源码之间的动态关系,并且通过查看这些可以得到一些感性的知识,例如一条正常的语句的汇编语句呢。 要把语言常用结构都给过一下。
- 一般作为人机接口的协议栈都会提供两种接口,humnable接口,还有一种那就是MI接口(machine interface),例如telnet,tl1,机器接口不会回显。 perl 语言能远程调试吗。(什么?)
- 调试分为与硬件相关的与内核相关的,与硬件相关的,例如中断信号机制,对于内存地址的转变,以及系统资源状态的变化。例外那就是进程的状态,线程的状态,以及调用堆栈的变化,同时系统调用库的变化,以及编程语言的转化,例如脚本语言到高级语言,再从高级语言到汇编的转化过程,在调试的过程要学习编译原理。
- 变量声明的语句是没有,编译之后就没有了,所以不能在变量声明的地方设置断点。但是解释型好像就可以,例如在perl里是可以的,试一下java是否可以,以及其他语言。
- 多线程如何调试。
- gdb finish 执行完这个函数余下的部分,
- gdb until 执行到当前函数的某一位置。
vS 已经实现了更新debug方式,那就是在每一个断点处生成snapshot,这样就可以来全回退,这样就不需要每一次重新运行了。对于 gdb来说,我们可以完成每一次的手工的生成与加载切换不同coredump. 同时gdb 还自身也有bookmark的功能。
bookmark start/end goto-bookmark help bookmark 这个功能是在 gdb 5.6之后就有了。
#load core-file
gdb> core-file <coredump>
#gen
gdb>generate-core-file [file]
gdb>gcore [file]
gdb>set use-coredump-filter on/off
you can check /proc/pid/coredump_filter
批量的添加断点¶
在gdb 中直接用info source 或者info functions 就看到全部函数名,并且还可以用python来操作,就像vim中一样。要把gdb练成vim 一样熟悉。 这样就可以直接用trace命令来收集数据。 VS中对于immediate Windows是可以执行一些调试命令,并且提供运行时库的相互环境,就像一个脚本语言解释环境一样。 另一种方法,那就是利用event来收集数据。还有那就是系统的signal. https://xpapad.wordpress.com/2009/05/18/debugging-and-profiling-your-cc-programs-using-free-software/ 关键就是检查了symbol table了。
gdb,attach 意味着你进入这个进程的空间,可以方便它的一切。
调试器的用途¶
- 可以动态查看程序的各种信息,ABI,以及有哪些库的依赖。所以遇到查询各种信息的可以直接debugger联接上去。
- 动态修改代码,及执行其内部的函数。
- 动态获取系统的状态。
- 如何定时debug. 可以通过添加asm(bkpt) 来实现。
如何实现引导代码¶
profiling都是支持tree 的,调试也是一样的。自己可以设置一个引导程序然后来加载自己的应用程序。然后把调试移至后面。这里用到那就是 gdb set follow-fork-mode 与 detach-on-fork 等。gdb process tree . 另外那就是 gdb wrapper see here .
Debug 的实现机理¶
实现三部分,
用户的输入¶
user interface,除了CLI接口可用各种后端,例如ddd,以及VS的MIEngine. 可以利用 readline/history等库。
gdb 可以当做后台,也可以直接使用,同时也支持vim 类似的分屏功能,利用layout的函数就可以实现。 符号处理,symbol handling, 这里主要是由 BFD/opcodes来处理。
要解决的在什么加载符号表,以及如何手工加载,一般情况下,在文件被调用的同时加载符号表,如果没有加载,可以load,unload重新做。 add-symbol-file/from memory 同时在 命令行也是可以指的, –symbols, –write 可以应用程序写入信息。 目标系统控制层: 用ptrace类似的系统调用来实现。
断点原理¶
通过查找输入的断点和具体代码位置对应起来,并在该位置替换为一条断点指令,并且保存以前的指令,到目标程序运行到该断点处时,产生SIGTRAP信号,该信号被GDB捕获,GDB查找断点列表来确定是否命中断点。继续执行的时候则会把保存的指令重新放回并执行。n/s/ni/si/finish/uitil也会自动设置断点。 条件断点的实现,也就是对于SIGTRAP的event callback chain上的一个而己。
断点插入的时机, gdb 将断点实际插入目标程序的时机:当用户通过 break 命令设置一 个断点时,这个断点并不会立即生效,因为 gdb 此时只是在内部的断 点链表中为这个断点新创建了一个节点而已。 gdb 会在用户下次发出 继续目标程序运行的命令时,将所有断点插入目标程序,新设置的断 点到这个时候才会实际存在于目标程序中。与此相呼应,当目标程序 停止时, gdb 会将所有断点暂时从目标程序中清除。
http://www.kgdb.info/wp-content/uploads/2011/04/GdbPrincipleChinese.pdf
信号¶
内核传递给被调试进程所有的信号,都会先传递给GDB再由gdb采取定义的动作来和被调试进程之间进行相互协调操作。gdb暂停目标程序运行的方法是向其发送SIGSTOP信号,GDB对于随机信号(非GDB产生的)的处理包括,可以通过handle signals命令来预定义
对于信号的处理,gdb如何反应,另一个那就是要不要传给debugee本身。
GDB的实现 原理 以及如何手工操作 /proc*
目标的系统的控制¶
而在对子进程数据访问过程中,ptrace函数中对用户空间的访问通过辅助函数write_long()和read_long()函数完成的。访问进程空间的内存是通过调用Linux的分页管理机制完成的。从要访问进程的task结构中读出对进程内存的描述mm结构,并依次按页目录、中间页目录、页表的顺序查找到物理页,并进行读写操作。函数put_long()和get_long()完成的是对一个页内数据的读写操作。
除了修改数据,同时CPU的结构也是可以改的,各种寄存器值,以及堆栈的值,如何确定特定的位置呢。
一种是通过寄存器,因为各个寄存器在ABI上有对应的分配,例如一般R3放返回值,PC程序寄存器值,SP,BP,是段值。 直接用汇编就可以任意的指定。
虽然用汇编是灵活了,但是细节太多,太麻烦呢。如何在C语言达到汇编的效果呢。问题的关键是一些高级语言与低级语言没有直接mapping关系.其实也不是没有关系,而是以前不知道分配策略而己。一是可以用ASM接口而做,二是直接特殊变量的位置,来得到邻居的位置。 例如 不同类型的变量,static,global变量,还有函数中第一个变量,它的地址进行加加减减就可以得到其他变量的值,例如最后一个变量地址+1就是return或者call之前的 寄存器的值,这时候只需要用指针来修改一下内存就行了。同时也可以用函数指针,就可以得到代码段的数据本身。
研究编程这么久,从开始就把这一点给忽略了,从学习微机原理时候就知道CPU有单步执行的模式。其实也是通过中断的来实现的。在汇编语言中可以直接加入bkpt,或者trap 指令来实现。这也就是breakpoint与tracepoint的源头了。执行这个指令CPU就会停下,你可以查看CPU的各种信息。也就是所谓的调试。这个其实与python pdb.settrace()的功能是一样的(今天才知道它是如何实现的)。其实就是bkpt 的功能。如果自己在代码的任何地方停,就可以在里面直接加入asm(“bkpt;”)就会断下来,这个然后再进程发一个 SIGCON来走下去。现在知道如何利用汇编直接操作硬件了。这也就是今天看CUDE asmdebug的代码的成果吧。如果这一下能停,可以查看或者硬件各种寄存器了。就是现在linux也只是利用CPU的部分功能。例如linux只用CPU的执行等级中二级。如果充分利用硬件功能,那就要是汇编了。
同时硬件也提供硬件hardware,也有采用软中断的方式。 硬件本身可以提供一个断点表,同进也是软断点,实现。对于汇编来说直接就是bkpt这些指令了。对于高层代码是如何实现的,那就是debugInfo的表,这里有每一行有效代码对应的汇编地址。这里会提供每个函数的入口与出口地址,也就是LOW_PC 与HOW_PC,有了这个表,可以生成callgraphic, 一旦有这个表,就像往你的代码里注入任意的代码,所谓的那些profile参数就是这么看的,每一个函数执行的开始与结束都加进代码。或者直接全用tracepoint 来实现。 通过分析,每一个函数指令位置,然后查看中间的jump指令,就看ABI是如何规定函数调用。就可以画出这个图了。这样通过objdump 得到debug infotable,然后根据这个表生成call graph. 并且已经有这样工具利用h -finstrument-functions,在编译的时候加上这些选项。
- 556-creating-dynamic-function-call-graphs
- egypt
- module List的作用* 可以用查看真实应用程序使用哪些库,并且库的版本信息等等。直接attach到可执行程序就可以得到这些信息了。例如battle的vcrt 就是这样查到的。当然在linux下会有ldd.
- debugger是如何知道各种映射关系呢* 就是app中debug info. /how-debuggers-work-part-3-debugging-information
- 调试信息
如何在任意地方设置断点,如何找到函数的指始点,只要是可以执行文件,必然会有一个entry address,得到这个地址,看看其对应的代码的哪一个函数也就自然找到入口点了。
现在知道如何编译来进行分析source code了。
另外一点,那就是调试的那些信息都从哪里来的呢。
同时可以在 通过 info share 来查看指令段,就可以知道在哪里哪一个库crush,并且还可以知道在哪里设置断点。并且利用addr2line 就可以得到。
当然也可以直接在 gdb 中实现这些事情。例如 info address symbol等等。
info address symbol
info symbols addr
whatis expr
whatis
这些可以非常方便让我来查看 ELF的生成格式,这个要比 objdump要直接有效的多。
in linux, you can use signal and /proc and some CPU interrupt do debug, don’t need the GDB. for example on the production line. You can do like this. send Pause signal to the process and check the /proc directory to get the status of the process. Proc interrupts , /proc/interrupts 和 /proc/stat 查看中断的情况 那到底是用的硬中断来软中断来实现的呢。并且gdb 还支持对gdt,ldt,idt的查看DJGPP 。
info dos gdt/ldt/idt/pde/pte ;info w32 info dll
几种方式是插入汇编asm(bkpt) 代码,或者采用指令替换的方式,例如在原理断点处插入跳转指令。把原来指令给换掉。 BP的插入也是代码注入的一种。 汇编的bkpt指令是一个字节,然后把第一个字节换掉,然后把原始指令保存下来。有两种做法,single-stepping inline,Single-step out of line.
gdb 主要是基于ptrace来实现,ptrace系统调用可以修改,进程的数据段与代码段的数据的,同时修改CPU的指令模模式。 进程是即有CPU的模型信息,又有代码与数据的信息。通用ptrace可以控制进程各种信息,例如加载什么包,调用过什么函数都可以用这个来进行控制调用。 http://www.spongeliu.com/240.html 可以参考这本书GDB Pocket Reference。 http://www.cnblogs.com/catch/p/3476280.html, 使用ptrace可以实现进程各种定制操作。 http://www.linuxjournal.com/article/6100?page=0,1
ptrace是通过发送SIGSTOP让进程挂起的,ptrace也是通过系统信号来与进程交互的。ptrace是通过修改断点处的指令为trap指令来实现的。ptrace采用SIGCHLD的编程模型,即目标进程发送SIGCHLD,调试器调用waitpid来等进程。
但是ptrace也有很多的缺点,例如一个进程只能被ptrace attach一次。将来会用utrace来取代。 http://www.ibm.com/developerworks/cn/linux/l-cn-utrace/index.html
当然主要是也sigtrap信号的实现,不管CPU的硬件实现,还是软件实现。原理都是一样的,因为在于速度:http://stackoverflow.com/questions/3475262/what-causes-a-sigtrap-in-a-debug-session
并且虚拟机也是通过ptrace,来实现的,现在可以用utrace来实现。
变量的值¶
我们在调试器里看到的变量的值,都是从哪里来的呢。是在内存里,还是在寄存里。对于CPU这种时分复用的机器,变量基本上就都存在内存里,而寄存上只是短暂的时间片的瞬间, 所以说这些值是内存的哪一段放着,并且它的邻居是谁呢,这样同样会大大影响存取的性能的。如何得到这个变量的赋值表呢,就是简单的bss段以及.data段吗。
一种是全局变量,文件静态变量,函数的静态变量如何查看,通过
file::variable
function::variable
同时 gdb创建了 variable object 这个是为 frontend与gdbserver之间同步信息使用。哪些内容我关系,我发一个variable object过去。有更新变化就得通知我的方式。 http://ftp.gnu.org/old-gnu/Manuals/gdb/html_node/gdb_231.html https://sourceware.org/gdb/onlinedocs/gdb/GDB_002fMI-Variable-Objects.html
经常看到些结构是欠套的,所以经常看到 -var-create next的东东。
为了减少数据的传输,也做了各种优化。例如 trust-readonly-sections. 只读数据不就需要从传输了,从本地取就可以了。
这是同步一种方式,相当于双方建立同样的符号表状态表,server那些有变化就通知client,没有的话就只用保持同步的heartbeat了。 当然client自身还是可以做别的事情。 那就是通过event来同步,可以是同步,也可是异步的。例如step in/out/over应该是同步。 其他的就可以是异步的。
module列表¶
elf结构的哪一些块放着呢。 module 加载的顺序采用深度优先的模式,并且得不断改写进程中GOT表,来进行重定位那些lib。这些module都是按照顺序加载的。逐section加载的。然后需要不断的调整各个.got表,以及.got.plt。 各个module就是通过自己.got 与.got.plt形成一个module链。 这个列表是可以用:command:info file 来看到的。 对于动态的链接库来说,第一个加载就应该是 /system/bin/app_linker. 在哪里寻找这些库,可以用set-solibsearchpath 来设置,原理path的一样的,不支持递归。 或者直接用 sysroot来进行统一的设置。 同时加载 moudle还可以定制化,
set stop-on-solib-events 0/1
show stop-on-solib-events
auto-solib-load
来设置加载lib是否加载, lib. 当然也可以用sharelibrary来强制加载一个或者全部的symbol单独来做。
http://visualgdb.com/gdbreference/commands/set_auto-solib-add http://visualgdb.com/gdbreference/commands/set_stop-on-solib-events
GDB 会在solibpaths 中按照顺序查找匹配的lib. 匹配的标准:
- 名字相同
- 有DWARF section
- Arch match
- build-id RSA 签名验证一致
同一个库,加载找到第一个,如果每一个失败,停止继续寻找这个库。

VS 给的link 顺序为 A,D,C,B;而gcc 需要顺序为 A,B,C,D.
代码块¶
既然代码可是每一个代码一个section,那在内存里呢,这个表又是如何组织的呢。在内存里是把所有代码放在一起呢,还是每一份独立放置的。这些都是可以通过调试器可以得到的。
写两个函数直接放在一起,然后最后两个内存地址相距多远。
callstack是如何查询的¶
这个当然是通过进程的栈来查看的,如果在不出栈的情况下就知道下函数调用在哪里,是如知道一个函数占用了多少呢。
disassmbly window¶
这个window是把代码段给解析了出来。
Auto local Watch¶
三者分别在哪里,
- auto 应该是当前指令正在执行的变量,应该这个时候就都已经在寄存里的。
- local 变量应该是函数内部变量,就是当前栈里所能看到变量。前auto一样是动态的。
- watch 而是 .bss 以及 .data对应的内存段。
通过这些地址就可以知道,进程大概的内存分布状况了,并且只要找到起始值,就知道其范围了。
而那些debug info 这些默认起动不加载呢,还是根据文件本身,有了就加载,没有就不加。
而这些是通过 GDB variable object 来实现的。
符号表以及其加载机制¶
debug_info 表对于调试起着至关重要的意义,它是源码与二制码之间的桥梁,只有debug_info 表认出来了,才能知道走到了源码的哪一行了,没有符号表那只能调试汇编了。另外没有符号表,BP就认不出来,因为你的断点是加在源码上。所以不能hit断点,两个东西要去查,符号表是否加载了,一个是相关库是否加载,另外库是带有符号表,还是被stripped, 库加载了,但是符号表没有加载。如何判断呢,在加载之前设置断点,然后一步步来,看看能不加载。例如module列表,是不是加载。另外还要看符号表有没有。
一般情况下debug_info表生成是绝对路径,当然也可以设置生成相对路径。当采用remote debug时,采用相对路径就会相对方便一些。
debug_info表与 符号表是不同的两表,符号是要程序动态加载的用的。具体见符号表。
对于gdb中要设置的一个是 solib-search-path. 另一个就是源码目录,directory
同时当大的obj文件中,加载symbol本身也会很慢,gdb 支持 生成index来加速这个过程,同时一些编译也支持生成。 另一方面在remotedebug时,把远程的sysroot给提前cache到本地就也可以加块速度。 例如 android的备份的是
同时也可以 set sysroot target://
system/bin
system/lib
system/vendor/lib
gdb -batch -nx -ex "save gdb-index C:\\directory_path" "C:\path_to_UE4_project_output_directory\libUE4.so"
自动加载原理¶
符号表放在obj文件中一个独立的section.符号的加载随着.so的加载而加载。所以.so加载顺序就决定了符号表的加载顺序。而 .so 的加载顺序是按照链接的顺序,并根据依赖树,采取深度优先的机制来加载的。 并且如果前面已经加载了,后面就不会再加载了。 而module 列表会显示加载顺序。这个顺序与 solib-search-path 一般情况是不一样的。 这是由于加载是根据依赖树深度优先来的。
手动加载symbol¶
info symbol
查看加载加了.so
info share
构造路径
set sysroot
加载symbol
symbol-file filename
一旦符号表加载了可以查看符号表的内容
| Name | Content |
|---|---|
| info line | 查看符号与源码行的对应关系 |
| info source/sources | 查看源代码的信息 |
| info symbols | 查看符号表 |
| info function | 查看加所有函数 |
Note
这些都通过查看online help来得到更多的信息
例如遇到了中途遇到crash,但是此时没有debug 信息怎么办,这里可以要求重新加载一下 lib,重新进行一次解析就可以。 这时候就需要用到
symbol-reloading symbol-reload 当然自动加载的时候,也要注意库的名字,名字不一样的时候,也是找不到的。 这样时候ln 就可以来帮忙了。当然也可以直接改名换路径。当然如加载的lib不对时,会报linkzip error.
![digraph gdb {
rankdir=LR;
gdb -> {BP; CPU;Program;OS;target;server;Interface;ownSettings;stack;SourceCodeView;DataView};
// break point
BP -> {breakpoints;watchpoints;catchpoints;tracepoints};
breakpoints [shape=record, label = "break | break function | break +/- offset | break linenum | break filename:linenum | break filename:function | break \*address |break if | tbreak|hbreak |thbreak | rbreak regex "];
watchpoints [shape =record, label ="watch | watch expr | rwatch expr | awatch expr | info watchpoints "];
tracepoints [shape=record, label = "{trace|tfind,tstart,tstop,tstatus,tdump,save-tracepoints|passcount | actions |collect data | while-stepping }"]
Interface-> {HI;MI};
//
Program -> {Inputs;Outputs;Execution};
Inputs [shape=record,label ="<f0> Inputs |<f1> args |<f2> corefile| <f3> attach "];
Outputs [shape=record, label ="<f0>Outputs |<f1> STDOUT |<f2> STDERR" ];
Execution -> {Step,Continue;Next;Until;Jump;Thread};
Thread [shape=record; label = "thread | thread threadno | info threads | thread apply "];
//stack
stack->stackOps;
stackOps [shape=record, label = "frame args |select-frame"];
//SourceCodeView
SourceCodeView -> viewOpts;
viewOpts [shape=record,
label="{list|set listsize |linenumer |function |*address} | \
{search regexp | forward-search|reverse-search} | \
{dir |directory show directories }| \
{file | symbol file | core-file, exec-file |add-symbol-file |add-shared-symbol-file | section } | \
{mapping linetoaddress |info line *address|disassemble range | set disassemble-flavor }"
];
//DataView;
DataView [shape=record,
label= "{DataView || \
p/xuf \*array@len \l \
x (type) \*array@len \l}"
]
}](../_images/graphviz-71fda8e6c34860b36e4d9db7c76607b71b8bceae.png)
breakpoint¶
,不仅能够disable/enable以及one stop,还能设置回调函数,不仅可以使用gdb脚本还可以被调试对象函数,以及第三张通过环境变量shell=指定的脚本。是支持python的。
watchpoint¶
用完就会背删除,并且不能直接加断点,必须每一次用完之后要,要重新设置,pentak是否会保存,并且如果是软件实现的话,速度会非常的慢,并且在多线程里,如果是软件实现只对当前的线程有效。
catchpoint¶
gdb 提供对load,try,catch,throw等等支持,另一个更加直接方式那就是对用__raise_exception.加一个断点,类似于perl中把把DIE包装一下。
对于程序的执行控制,利用exception, singal 等等控制。
例如对不起trhow, catch,exec fork,load等等控制,都可以直接用catch 命令设置,而对于程序自身那就是raise() 来发启signal,可以用raise(),signal()结合起来实现一个状态机。http://www.csl.mtu.edu/cs4411.ck/www/NOTES/signal/raise.html
tracepoint¶
this is just a pm point of SDH. you monitor the system state at the tracepoint, you can collect the data. so you that %RED%how to use tracepoint to make write down execution log just bash set +x%ENDCOLOR% the core-file is implemented use this.I guess so. there are three target for GDB: process, corefile,and executable file. what is more, GDB could offer some simulator for most of the GDB.
next,step,until,contil,return,jump,fg,ignore¶
这些命令都有两种xxxi这种,是针对机器指令,也就是汇编指定的,另一种是针对源码的。并且后面都可以跟一个数值来实现循环。 进入了gdb后,你完全可以重起组织代码执行顺序,甚至把应用当做一个库,利用gdb脚本重新实现一遍应用程序,例如直接把attach上当前的进程,然后,加载自己的东西,因为gdb是支持写回功能的。这样就可以强hacking 的目的。
—
display automation display the info display /i $pc —print and x you can also control the scope and format of data. by <verbatim>set print XXX //static-memebers ,vtbl </verbatim> and meanwhile you can retrive the history value of the variable. by *.$. $ is special symbol. $$n refers to the nth value from the end.
In GDB there is convenience variable(prefix with $ $AAA,$BB) you use it during the whole GDB life. register you can also get the register value from =info registers= or = print/x $<registername>=
the strongest point is that GDB could manipulate the memory directly. <verbatim>mem address1 address2 attributes …</verbatim> there is also a cache for data.
BP set¶
when I can I set the BP. 在今天的测试中,断点能设置在哪,并且是否被击中,并且什么被解析了。例如在空白处是不能设的,编译形与解释型debug有区别吗,
working language and native language.¶
you do extension for gdb as native lanuage or working language. you control these by show/set language. info extensions. different language supported different type and range check.
GDB extension¶
gdb 支持自身命令的扩展,一种是通过<verbatim>define commandname</verbatim>. 另一种通过命令hook来实现。另外现在gdb 都支持 python来进行扩展 。并且gdb也是可以`http://docs.python.org/devguide/gdb.html <直接调试python>`_ .
..cas-table:
meta element , define commandname , define a new function ,
^ , if,while document,echo,printf,output ,
^ , help user-defined,show user ,
hook , hookpost-XXX , after ,
^ , hook-XXX , before ,
command file , source, .gdbinit <verbatim>gdb <cmds >log 2>&1</verbatim> ,查一下pentak这个是在什么时候调用的 ,
now, there is good example for define command, ndk/common/gdb/common.setup for art on.
pretty printer¶
GDB 是支持python,并且可以通过python来实现大量的定制化,例如正好的显示,当然也可以利用python 起动一个socket 然后当做一个server,来远程操作一些东东。当然今天先看python 对于显示的优化。 c-gdb-python-pretty-printing-tutorial gdb 如何直接执行python
python
import sys
print afa
end
通过学习 ndk 中ndk-gdb-python 来作为参考。 gdb 扩展可以参考`Extending GDB using Python <https://sourceware.org/gdb/onlinedocs/gdb/Python.html#Python>`_ visual-studio-debugger-related-attributes-cheat-sheet 这里讲了一些 debug的设置。
gdb 中使用 python 类似于 vim 中使用 python 一样的。
对于一些负责的数据内存数据结构,完成可且numpy + Image 等等方式来进行可视化。这个是最简单有效方式,加载一个解释器,能够访问进程的内存空间 然后对其可以做任何操作。
也可以利用gdb + python来做各种单元测试。
对于PentaK 与VSAuto 都会 visualize功能。基本用法那就是根据结构体类型如何显示其内容,例如只显示头,以及如何以树形展开,因为对于基本的基本的数据结构的组合。 浅谈autoexp.dat文件的配置 以及我们http://devtools.nvidia.com/fogbugz/default.asp?30959
How to write Visualizer 分两部分 debugger,与debugee两部分。然后根据模板来显示。
VS 自身的模板在 C:Program Files (x86)Microsoft Visual Studio <version>Common7PackagesDebuggerautoexp.dat 里。
基本类型,整型,长整型,十六进制,以及浮点树,以及字符串。 这里分preview and stringView,children, 基本的数据结构有#array,#list,#tree, # 本身,以及特殊的自由变量。
$e,$c 是自由变量,m_pszData等等结构体自身变量。
这个类似于python中pytable的功能,可以直接table值。
type=[text]<member[,format]>....
http://www.xuebuyuan.com/1300115.html 这是一个不错的教程 http://blogs.msdn.com/b/joshpoley/archive/2008/01/24/custom-debugger-auto-expansion-tips.aspx http://www.manicai.net/comp/debugging/visualizer/
GUI¶
gdb 两种方式支持GUI就像VS那样,一种是自带的TUI接口,另一种那就是利用Emacs做为界面。
while 循环的汇编实现¶
汇编的时候是直接跳到第一内部第一行执行的。dissembly window 提供行号,源代码等等东西,可以很方便的找出其翻译的对应关系。 调试信息表都有哪些信息,为什么没有源码,调试就跟不进去,能否调试Java虚拟机的原语操作呢。
反编译¶
反向工程向来是个大课题,把C语言翻译成汇编,并反过来,就一定成立,因为语言之间不是一一切对应的关系。所以可读性会非常差。但是也是可以参考的。` 反汇编 <http://baike.baidu.com/view/637356.htm>`_ IDA pro 5.2 反汇编代码转C语言插件
core dump 调试¶
- 开启core 文件的生成 ulimit -c unlimited
- gdb 分析core文件 gdb debugme core.xyz
- 动态生成core, gcore pid.
- 动态生成strace strace -p pid .
#. 调试正在运行的程序 gdb debuggee pid. http://linux.maruhn.com/sec/glibc-debug.html
利用信用号来进行调试¶
http://www.ibm.com/developerworks/cn/linux/l-sigdebug.html. 在代码里自己给发一个停下来的信号就行了,然后gdb在attach 上来就行了。
See also
- jdb IBM web %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- VS 调试技巧 VS 的immediately Window 就像tcl那个调试器的功能,也就是给你一个运行时环境,就像脚本语言的解释器一样。可以直接调用你的所有函数。MSDN 参考命令
- vs2010调试技巧 %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- 符号表 %IF{” ‘二进制可执行文件结构’ = ‘’ ” then=”” else=”- “}%二进制可执行文件结构
- MSdebug %IF{” ‘NV debug wiki’ = ‘’ ” then=”” else=”- “}%NV debug wiki
- core file for debug %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- sparc-stub.c %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- Extending gdb %IF{” ‘you can use python ,gdb cmd, alias to shell programming.’ = ‘’ ” then=”” else=”- “}%you can use python ,gdb cmd, alias to shell programming.
- Visualgdb %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
- GDB学习总结–实现原理 , Linux信号列表 gdb 是利用SIGTRAP信号来实现的。至于SIGTRAP是用硬件还是软件这个要看内核了。
- gdb server manual %IF{” ‘gdb server 也是可以直接加载应用程序,而不是只能attach,只是pentaK 对于APK采用这种方式’ = ‘’ ” then=”” else=”- “}%gdb server 也是可以直接加载应用程序,而不是只能attach,只是pentaK 对于APK采用这种方式
- gdb 如何调试多进程 %IF{” ‘一个方法,gdb wrapper. 一旦设置的断点,就会引用SIGTRAP信号。’ = ‘’ ” then=”” else=”- “}%一个方法,gdb wrapper. 一旦设置的断点,就会引用SIGTRAP信号。
- Miscellaneous GDB/MI Commands %IF{” ‘’ = ‘’ ” then=”” else=”- “}%
Thinking¶
远程调试 远端与近端要配套才行,有两种情况,一种是远端可以执行文件本身含有调试信息的,第二种那就是远端没有调试信息,而是需要本地提供的,加载各种调试信息以及原码,只是依赖远端的进程与本地拥有相同地址,通过地址对应来实现调试。当然你可以自己实现一个gdbserver,并且gdb已经预留了接口与模板,remote.c 并且在attach的过程,gdbserver 会先向进程发一个暂停信号,然后连接上去。这些是根据进程与内核的之间的调度来实现的。A minimal GDB stub for embedded remote debugging. ,`GDBstub的剖析与改进 <http://www.mcu123.com/news/Article/ARMsource/ARM/200705/4297.html>`_ ,并且gdb源码为库中还提供了大量的模板与例子。对于常见一些CPU架构的支持。 例如android 的调试 use Project Symbol 参数一样。你要选择:
"/system/bin/app_process", "/system/lib/", "/system/bin/linker C:\Users\vili\AppData\Local\Temp\Android 并且按照设备号来存放的。
为什么要linker 这个linker是做什么用,如果不需要本地的话,就只需要app_process与linker.
gdbserver + unix_debug_socket --attach 123
Debugging an already-running process –attach function need system support. there is an process concept. how about the bare board target.
其实也很简单, –tty是可以直接指tty的。 – Main.GangweiLi - 05 Feb 2013
数据一致性 特别是在troubleshot的时候,尤其要注意这个问题,例如你改的文件,没有保存,保存了没有重新编译,编译了没有重新deploy,以及远程调试两边的版本不一致。都会感觉到莫名其妙。怎么看都对,就是结果不对。
– Main.GangweiLi - 05 Feb 2013
多线程调试 step by step时,能不能跨线程或者手工进行线程切换 是根据CPU的架构以及 scheduler-locking 来决定的,在gdb中是可以设置的,set scheduler-locking mode。线程内部的调用关系,都要很方便的显示出来。多进程调试有同样的问题。可以查看每一个线程的状态,并且可以进入每一个进程。 All-Stop-Mode
– Main.GangweiLi - 07 Feb 2013
quickly debug call stack and filter BP. One more is diff with the baseline. the first get workable path, and then look at the difference between each other.
– Main.GangweiLi - 08 Mar 2013
execution control you execute an command just like tclsh. should be able to jump at the source code for example skip some step. The arguments to your program can be specified by the arguments of the run command, They are passed to a shell, which expands wildcard characters and performed redirection of I/O, and then to your program, Your shell environment variable specifies what shell GDB uses.
the environment of software : working directory. lib search path, stdio.
– Main.GangweiLi - 14 Mar 2013
#!/bin/bash
echo "run -c test.conf" > test.gdb
echo "bt" >> test.gdb
echo "bt full" >> test.gdb
echo "info thread" >> test.gdb
echo "thread apply all backtrace full" >> test.gdb
until gdb ./core -x test.gdb --batch >test.log 2>test.err
do date && echo "test server died with exit code $?. Restarting..."
grep -B 10 -A 1800 "SIGSEGV" "test.log" > "testtrace.log"
cat "testtrace.log" | ./paster | grep "http" >> "test.link"
cat "test.err" > "testerror.log"
sleep 31;
done;
shell interpretor You can regard the gdb as shell interpretor, the software you prime command you can use you shell language. the gdb shell include two: target language that you the language you debug. the scripts language, gdb support by it self. you can use both. Once the program you load, you can use all of this function. and you source the other scripts. GDB-Python-API , Extending-GDB there is .gdbinit file. and during the execution, you can source the scripts file. all the gdb cmd you can use it. and the input and output is every regular, you use the annotationlevel and machine Interface to do the automation.
– Main.GangweiLi - 24 Mar 2013
you can just load the nostripped binary code. it just load it, not run it. and -g also include sourcecode in the binary execution file? when debugging, do we need the sourcecode, normally, we didn’t need the sourcecode. and meanwhile, it means that -g binary and .so lib has the sourcecode information. how can we get the sourcecode from debug version binary.
– Main.GangweiLi - 02 Apr 2013
How to hit boot code normally, it execute quickly pass the stage. how to make this, one way is that you add a dead loop for exmaple int i=1;while(i). so when you hit it. and then change it i=0, and continue the execution. for the debugger, you can change the value at local window. 自己包引导程序等待一个信号来起动eglretrace,这样就可以给我足够的时候来–attach上去,当然引导程序,如果通用shell来直接来做就会更加方便。perl应该就可以,但是android只有简单的sh,如果可以这样最好,还有一个办法,直接–attach到程序的加载器上,然后可以控制后面的加载函数。
– Main.GangweiLi - 10 Apr 2013
info locals window how to implement it. is it using this command?
– Main.GangweiLi - 15 Apr 2013
如何例出所有函数 如何查询代码,所有函数名呢。不只是当前的文件。these operation is regard about symbol table. you set -n read symbol all at the inital. then you can do query the symbol(function name, varible name, CPU struction, address, any label). by these command | info address symbol | Describle where the data for symbol is stored | | info symbol add | print the name of a symbol which is stored at the addresss addr| | whatis expr | print the data type of expression expr | | whatis | | ptype typename | print a description od data type typename | | ptype expr | | ptype | | info types regexp | | info scope addr | | info source | Show the name of current source file | | info functions [regexp ] | print the names and data types of all functions | | info variable [regexp ] | print the names and data types of all vrables |
the other hand, GDB offer another way to manipulate the symbol file just like (operation on section). you load it into gdb and query and modify it and save it.
– Main.GangweiLi - 16 Apr 2013
GDB的命令行编辑习惯 你可以用VI-style, emacs-style, csh-like. it use readline lib to implement it. and readline lib support vi-style and emacs-style 以及history 功能。并且这个history 支持正则查找替换。 <verbatim> set editing on/off show editing set history filename/size/save set debug arch/event/expression/overload/remote/target/varojb/screen/versbose/complaints/confirm
</verbatim>
– Main.GangweiLi - 16 Apr 2013
GDB machineInterface this one is just like tl1. there is two mode. human readable/raw. and the telnet has two mode too. at the early age, gdb annotation to change this mode and emacs use it.
– Main.GangweiLi - 17 Apr 2013
JUST IN TIME DEBUGGER http://msdn.microsoft.com/en-us/library/5hs4b7a6.aspx 如何使用,并且今天看了,VS调试壳,是否可以利用vim或者emacas也来招调试器。
– Main.GangweiLi - 06 Jun 2013
gdb就可以实现debug,看见汇编之间的关系吗?
– Main.GegeZhang - 25 Jun 2013
什么是声明变量
– Main.GegeZhang - 25 Jun 2013
– Main.GangweiLi - 22 Jul 2013
– Main.GangweiLi - 30 Jul 2013
对于指针内容的显示 在我们使用指针时,常用的变量的类型就没有办法显示其内容了,使用指针,你可以任意组装任意的东西。但是如何查看了,就时候用到了,gdb 查看内存的方式了,p/xuf 等等。例如在native_globe里,生成那些顶点数据时都是使用的指针。如何查看这些值呢。使用immediateWindows现在是支持不了,直接连到GDB上发送一些命令。
– Main.GangweiLi - 29 Aug 2013
Debugging Infomation In Seperate Files¶
https://sourceware.org/gdb/onlinedocs/gdb/Separate-Debug-Files.html
可以通过同名文件 xxx.debug或者build-id 进行同步,如果使用前者还会有一个 CRC的校验和。
同样可以用
objcopy --only-keep-debug foo foo.debug; strip -g foo 就可以得到 debug info table file.
Ptrace¶
gdb 主要原理就是动态修改的进程的所有状态与内容,还有寄存器的能力。例如修改返回寄存器的值,就可以改其反回值了。
#include <sys/ptrace.h>
Long ptrace(enum_ptrace_request request,pid_t pid, void *addr, void *data)
/**/
request 是具体的操作。
整个过程就是追踪者先通过PTRACE_ATTACH与被追踪进程建立关系,或者说attach到被追踪进程。 然后,就可以通过各种PEEK和POKE操作来读/写进程的代码段,数据段,或各寄存器,每一次4个字节 通过data 域传递,由addr 指明地址,或可全用PTRACE_SINGLESTEP,PTRACE_KILL,PTRACE_SYSCALL各 PTRACE_CONT等操作来控制被追踪进程的运行,最后通过 PTRACE_DETACH与被追踪进程脱离关系。
但是当多线程的时候,有可能PTRACE_CONT有可能会失败。http://stackoverflow.com/questions/16360366/ptraceptrace-cont-cannot-resume-just-attached-processes
脚本扩展¶
简单可以用gdb的本的shell来做,while,for,if也都是支持的。复杂的可以用python来做。就像vim一样。 https://sourceware.org/gdb/onlinedocs/gdb/Python-Commands.html#Python-Commands
如何用gdb来收集数据¶
tracepoint一个一个加太麻烦,有什么更快的一点方法,那就用gdb来做,最灵活。 具体某几个点可以用直接用tracepoint来做。 大面积可以用event,以及signal来做。 http://stackoverflow.com/questions/2281739/automatically-adding-enter-exit-function-logs-to-a-project
对于gdb.event可以python来做https://sourceware.org/gdb/onlinedocs/gdb/Events-In-Python.html gdb.events.inferior_call_pre/post 事件。
对于SIGNAL直接用`handle SIGUSER` 来实现https://sourceware.org/gdb/onlinedocs/gdb/Events-In-Python.html
一些其他的事件,http://visualgdb.com/gdbreference/commands/set_stop-on-solib-events http://stackoverflow.com/questions/7481091/in-gdb-how-do-i-execute-a-command-automatically-when-program-stops-like-displ
https://sourceware.org/gdb/current/onlinedocs/gdb/Hooks.html#Hooks
最终看代码实现 https://sourceware.org/gdb/current/onlinedocs/gdb/Hooks.html#Hooks
define hook-stop
如果只是看stack,有这样的工具https://github.com/yoshinorim/quickstack http://poormansprofiler.org/ http://readwrite.com/2010/11/01/using-gdb-as-a-poor-mans-profi/ https://github.com/Muon/gdbprof
用gdb来进行测试¶
起真实的进程是最好的环境。如果能起app然后在这个context里,利用gdb来直接执行。 http://stackoverflow.com/questions/16734783/in-gdb-i-can-call-some-class-functions-but-others-cannot-be-resolved-why
但是一些编译复杂的结构,gdb是没有办法直接编译的,这个时候就需要JIT来帮忙了。
另外把测试的函数单独放在一个dll中,然后 dlopen来加载。 http://stackoverflow.com/questions/2604715/add-functions-in-gdb-at-runtime
即使没有,也可以临时写一个,只要编译的时候加上一个 -fPIC 就可以了。
先生成一个coredump,然后再coredump中来进行各种各样的测试。
在crash直接调用gdb. http://stackoverflow.com/questions/22509088/is-it-possible-to-attach-gdb-to-a-crashed-process-a-k-a-just-in-time-debuggin
尽可能不要在头文件中下断点,这样可能造成n多断点,在n多地方。 是由于断点寻找机制造成。
shared object 在加载之前,是加不上断点的。 这也就是为什么我们hack lib-loaded event的原因。
ProfilingAndAnalysis¶
实现原理¶
要么是静态的分析各种资源的分析,或者硬件本身支持。 软件库的实现APIC的功能,主要是inject来实现的。
当硬件资源有限的情况下,采用multi-passes 来实现,多跑几遍,每一次只测量一段,尽量减少对被测对象的干扰与破坏。 同时inject可以LD_PRELOAD 这种一次ALL_IN的模式,也可以自定义实现dll_export 功能来定制某一些API。 最有可能破坏,malloc函数。 操作的对象就是ABI的 ELF的符号解析与跳转这一块, 经常会出现的问题,随意injection会破坏内存对齐从而导致程序crash.
Optimization 的过程,本身就可以是寻径的过程,最终变成汇编语言之后,每条汇编指定有一个定cost,把哪有cost的分类到一个group,然后每一个group生成group 的cost函数,这样就可得到每下代码块的cost了,同时也就生成一个cost函数,这样基于callgraph图来生成路径。
- 传统的 tree只能看到单一调用关系,例如多个函数调用同一个基层的函数是看不出来的。 利用callgraph,就可以清楚看到哪一个节点,最调用最多,并且是从哪些路径来的。
- 并且现在DL的代码生成也都是直接计算图,中得出来的。完全是可以计算图。
profiling的本质找到所有stakeholder,并且找到这个系统的最大平衡点。 所谓profiling,也就是各个资源的利用率。 pipeline以及算法本身都是约束条件。那些PMUcounter能统计那就是离开始点的,绝对时间例如ns值,另一种那就是CPU cyclyes的数。 例如然后那就是自身的counter,指令数,以及读写的数等等,并且他们的状态以及各种统计值,total,max,min,avg,std. 当硬件PMU不够的时候,就采用多次pass的方式来分次分段采样。
每一层,只要不是只有一个个体,存在完备的个体,做同样的事情应该不会只有一条,但是哪一条效率最高呢,只要是一个集体,就会排兵部署的要求。
每个体的各种属性,最终也会变成在上一个维度时,的一个属性以及cost, 在计算各种path cost,就是这样来的。
优化最后结果,那就是功耗比。 具体的上层算法本身的流程要求,还有框架本身的pipline,以及硬件各种资源的occupancy.等等。
工作的流程¶

Moduling, 建模,根据具体问题建模,形成算法,并且相应算法复杂度分析,也就是所谓的常,对,线,平,立,指。形成算法多项式。
生成代码,现有各种代码生成工具,把各种计算模型直接生成代码。
优化的级别
直接调用更好,优化的库,工作量最小就是换一个API。
利用 openacc 来标记,让编译来优化。
代码级优化 例如LLVM,
硬件指令级优化
因为现在硬件结构都是流水线的,pipline,而分支就是pipline的杀手,同时如何使硬件的资源的load balance,这是编译器可以提高与优化的地方。 branchless program
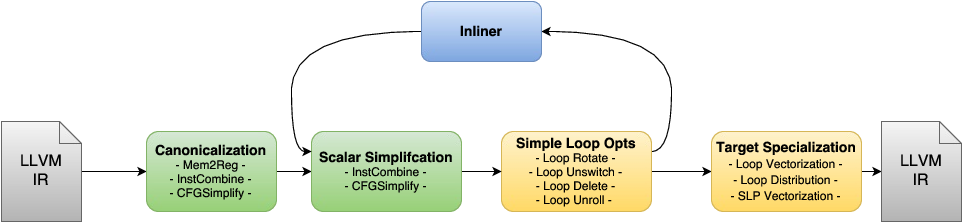
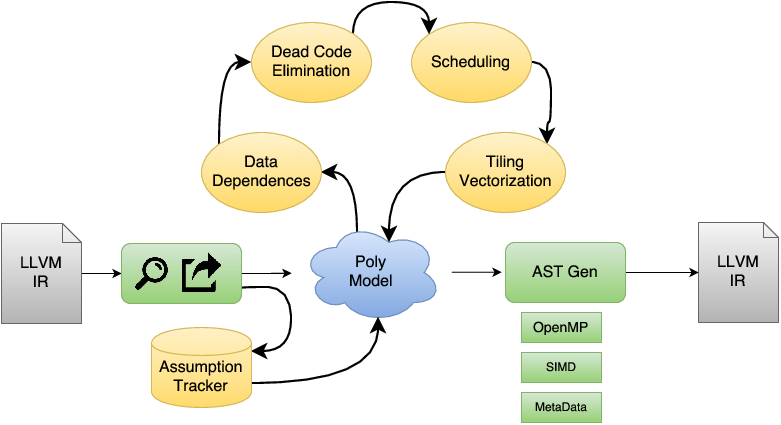
为什么优化¶
程序慢 ,首先要看系统的资源使用的如何,如果系统还是比较空,那就要改程序来充分利用系统资源,系统资源已经很紧张,那就优化程序本身
程序占的资源太多 ,首先要保证速度的情况下,优化程序内部结构。
但是如何量化这些标准呢,而些标准是来源于哪呢,是源于应用本身的要求。对于游戏来说,其中一条那就是framerate,最低要达到24frame来达到动画效果,不过一般情况下都要求做到60fps, 对于3D的显示可能要求更高的fps,例如通过切换左右眼的影像来得到3D效果,这个就需要120fps。
其实这些就是所谓的用户体验的一部分吧。最终反应终端用户面前的,一个是流程本身的合理性,另一部分则操作的流畅性。而所有的这些都是技术指标的。例如视频本身fps.不同的应用会有不同的需求。对于破解会对破解速度有要求。对于仿真对于仿真的精度有要求。对于计算机的不可靠性很大一部分就是指的其精度的问题。这个对于大型科学计算尤为重要。
- Reduce IT spend, find and eliminate waste,find areas to tune, and do more with less.
- Build scalable architectures - understand system limits and develop around them
- Solve issues -locate bottlenecks and latency outliers
对于产品的需求一般是两部分:¶
- 功能性需求 来解决特定的问题,对于我们来说,大部分时间是在解决这种问题。特别是自己平时的写的大部分脚本。对于产品的开发就要做到人无我有,就是指功能。人有我精指的是性能。
- 性能要求 对于种技术指标的要求。
同时大家所谓的80/20原则。也就是20%时间就解决了80%功能。80%的时间用在解决那20%的性能。
如果对于性能要求不高的,你的solution的选择就会很多,会有各种各样的库可以供你用。但是考虑到性能化那就未必了。那就是为什么相同的功能为什么会有这么多库。并且基本上大的项目,很多东东都是自己实现的,而非用一些语言本身的实现或者库的实现。最明显的例子,就是那些队列,以及reference count之类的东东都基本上都上是自己实现的。根据性能要求,来做不同编译,例如满足精度的情况下,尽可能用硬件浮点计算。或者换用不同库会有质的变化。
优化的前提 是保证正确性,在编译器的一些激进的优化,可能会出错,同时采用近似的计算。
优化的目标¶
- 算法本身的优化,减少计算量
- 指令优化,减少指令条数
- 删除掉不必要的负载,看看是不是加载不了不必要的库,以及是不是有更优化的库可以用。
硬件的优化¶
尽可能大的利用硬件资源。 改变读取pattern提高cache的命中率。 可以把整数部分换成浮点数, 提高系统的利用率
终级优化人工优化汇编指令
这个是最难的,对于每一个具体问题,都会有一个很多很好的solution.但是所有问题放在一块,就不见得有了。所以要在保证效率的情况下来提高效用性.
因为汇编指令是一个完备集,所以对于指令的统计状态,就是当前状态反映,例如每一类指令执行数量与频率就体现相应的资源利用率。现在终于明白了 CUDA Analaysis 对于每一类的指令分析的用途了
如何使用timeline¶
要使用 timeline 首先要能读懂timeline. timeline是一个立体的图形,x轴代表时间线。而y轴代表并行的资源。它反映的在某一时刻,各种并行资源都在做什么。例如这个时间CPU在做什么,GPU在做什么。并在每一条横轴都有会数据,显示各个资源自己的参数。实际采集实际最少三维的数据。时间轴,并行轴,每一个并行轴的资源的每一个参数。 使用timeline可以时间轴来看某个时间点,系统都发生了什么事情。当然这个只是从时间关系上。当然还有一些依赖关系是不能直接时间分析来得到,但是可以从那里得到一些线索。
从timeline中能读出什么呢:
系统资源的调度效率,速度很慢,并且系统各种资源的使用率也不高。这个说明资源调度效率不同。
- CPU Core Utilization Avg(black) & Max(gray)
- Thread 状态
- 使用率
- CPU 的core 占有率
- Thread State (running,blocked) 通过这些看到这个线程在做什么,为什么会blocked.
- Event Trace (various APIs cuda/opengl/nvtx)
可以看到并行与串行的真实分配情况。并且计算 Amdahl’s law 优化最终效果,是取于不能优化的部分所占的比重,求极值,可以知道极限在哪里。
- 那些时间片中大量的空间,就是要需要优化的地方
- 能时通过下方的函数统计,就知道,这个时间点,哪些函数在执行并且在做什么。
- 并且在这个时间点,哪些函数是blocking issue
timeline的时间轴就是一段段的时间片,其最小单位也就是一个pixel代表多少时间片的问题。在timeline上会标出这个时间片里某种精源利用率。
quadD gravy->maxium heavy->middle vaule NSight android systrace 从timeline上看trace.
- 直接看代码太多的细节,不利于快速掌握整个的workflow, 如果添加了nvtx之类的标记的话,可以直接用。 如果没有可以直接根据timeline上的时间片来观察,在sample freq足够高的情况下,如果timeline上没有空隙,那就说明现在CPU正在集中一件事,一个大的函数。 没有发生的大的线程切换。
- 从线程数中,可以看是否启用了多线程,如果用了,一般都会是生产消费者模型或者fork-join. 得到大体流程。
- 先找到主线程,然后根据其timeline上的大的时间片,来查看其相对应的callstack,来得到其执行的trace. 而不要再debug来看其执行了。
- 再每一个线程中,看其执行的函数在timeline上有重复,就说明这里是一个循环。
- 如果工程太大,或者复杂,可以选择添加在代码中添加nvtx来实现,进一步合理颗粒度的注释。
- 调用关系可以从下callstack来搜索。某一个函数的调用。
如何优化¶
各种书上都讲了各种方法与规则但是如何动手呢,NSight Analysis就提供这样一套分析工具。并且是从上到下从粗到细的,并且从定性到定量的。
例如GPU的thread如何分配呢,主要靠分析occupancy.
follow the CUDA_Best_Practice.pdf and CUDA_Profiling_Guide.pdf这两个就够了。
看了那这么多,至少从前下一层来看。所谓的优化,也是资源的使用率是不是符合预期。 而基本现在系统都是分层模块的设计。 由于计算机的透明性,每一层都是系统资源的一种抽象,要想知道当前使用的是否合理,至少下一层去看了。 这也就是为各级probe了。 微内核模式的,每一级都可以是指令集,而非微内核的模式。一般是函数为边界。 想到函数更小一级,那就是利用nvtx之类东东,或者到指令集的,直接用模拟器或者PMU硬件来得到。 这也是各种profiler工具存在的原因。
当然为了减少overhead,人们是想进各种办法,使用独立的硬件。 独立的线程。 减少context切换,例如内核态与用户态的切换。 当然使用JIT动态插入断点的办法来提高灵活性。
要想底层的支持
- kernel本身支持, 查看 /proc/config.gz 查看其编译选项是否打开,如果没有打开,是不是可以通过补丁来解决,或换一个更新的kernel.
- 对应的debug info是否有,其原理也是添加断点hook来实现的。
- module的build 环境要有, probe的实现原理,也是当写一个.ko 插入内核,只不过内核补丁自己提供一些函数,例如systemtap,你的probe可以调用这些内部函数。 例如打印pid,tid,callstack等等。例如systemtap会提供一个DSL,然后JIT编译直接使用。断点的插入在register module中实现,所以当你insmod时,就插入了。
- 对应kernel的工具的perf 工具,例如linux-tools-$(uname -r) . 没有的话,就得自己下载 kernel编译的环境,工具本身的source code来进行编译了。
- DUT本身的source code, 方便hack使用。
- 对应平台的 debugger 方便出现问题的时候,快速troubleshot.
- API层的probe,就是通过inject实现,实际上在动态链接的inject lib api来实现。利用LD_PRELOAD来实现。
如何手工uprobe, 能有现成的binary,版本都能对应上直接用,没有的话,就要从源码来了,先看内核 +硬件支持不。然后再按照流程来进行就可以了。可以独立编译或者在 源码树中进行编译。
如果各个性定制¶
如果Nsight Analysis提供的那些方法还不行,还有办法,那就是定制化。如GPU有profilingAPI的,例如最简单的`CuProfilingStart(),CuProfilingStop()`控制。当然你还可以取得另一些数据控制。让应用程序自身实现终身的优化。
collection of Data¶
- function entry/exit
- process and thread create/destroy/stateChange
- Context Switches
- DLL load and unloaded
How to sampling¶
this system should support approach to make Snapshot quickly, may this is supported by dedicated hardware. for example, snapshot all the registe and state to somewhare, how to use the info is descided by user how to analysiz these. the sampling frequency is resticted by two things:
- offline analyise , it is simple, only the speed of snapshot and store the info.
- RT analysis, in addition to the the above restrict, the analysis speed is also a restrict.
直接在CUDA中直接加入 PTX代码 这样可以解决编译转化效率的问题,这个结论从何而来,可以利用CUDA的analysis的 kernel/source 来这样,可以看到每条指令使用的次数,与每行原码执行时间。如何使用PTX 可以见帮助文档,Inline_PTX_Assembly.pdf与ptx_isa_4.0.pdf
– Main.GangweiLi - 18 May 2014
- 存取加速 缓存,寄存器,显存,内存,外部存储设置等。为了达到更块的速度,从两方面入手:
- 1. 用更块的硬件,例如 GPUDirect 直接与第三方设备读取DMA方式,而不需要CPU与经过内统的内存。另外那就是NVlink来加速CPU的通信的方式。主要来解决机器内部传输带宽的问题,原来的PCIE总线速度太低。当然也要driver库都有对应的支持才行。 1. 通过算法,并行提高register与__share__显存的利用率,以及常量的cache的利用率。
但是如何来衡量这些呢,那就是Nsight的analysis.
一个做的流程那就是APOD,道理也很简单,
| Stage | Tool | Target |
|---|---|---|
| Asset | Timeline;gprof | wark with Amdahl’s law |
| P | OPENACC;OPENMP;Thrust; Parallel. | |
| O | traceing;profiling; | |
| D | JIT | make use of new hardware. |
现在对于整个流程有所了解了,知道各个技术都在往里用,是要自己新开发应用,还是加速的应用程序。一些简单的做法,对于常用数学库直接换用GPU的函数库,对于一些数学计算也直接算用GPU的函数库,对于loop,sort,scan,reduce等可以通过Thrusts模板来实现。
当然你要改动就会有风险,那么所以要采用敏捷的方式来加入测试来验证这些。
latency VS Occupancy¶
这两个是矛盾,latency越小越好,那当在占的资源多,执行时间短,Occupancy那就是尽可能并行,系统的总的资源是有限,并行度越大,每一个可以分到资源也就越小,那么执行间可能就会越长。在CUDA里资源,那就是寄存器,share memory. Occupancy研究的是使用率,相当于CPU的的使用率,如何CPU使用率100%的问题。这个是在解决GPU资源大于所需的要求,如何原来结果更快。Occupancy高,意味着更多的线程在干活,首先要解决理论occupnacy,然后是实际的值,极限值,GPU的最大值。只有有足够多并行,才能隐藏latency的问题。一个线程不执行完,就不会被释放,并且最小调度单元是warp,也就是只有一个thread在占着,那么整warp就不能被再调度了。
解决方法有三个:
- execution configuration.
- launch bounds 用来帮助NVCC来分配寄存器。
- Pipe Utilization 解决那种长尾问题。就像火车站买票一样,半个小时内票,再好看单独一队,而是在长对后面等。
如何充分利用缓存¶
如何缓存也就是要提高hit率,首先要理解缓存工作原理:缓存采取就近原理。离自己最近也是可能用到。这样的话,就只有一个原则那就是尽可能的减少跳转。如何能做到这一点呢。尽可能有序这个不管是对 data还是instruction都是有效的。 [optimizing-for-the-instruction-cache] 例如 A->A->A->A->A->B->B->B->C->C->C-> 执行起来会比 A->B->C->A->C->B->A->C 更有效。因为前者大大提高了cache hit的效率。
| [optimizing-for-the-instruction-cache] | http://www.altdev.co/2011/08/22/optimizing-for-the-instruction-cache/ |
编译本身优化¶
链接不同的库,使用不同编译选项都会改变程序的性能。特别是浮点数等等,应用性强的功能。都会特殊的优化。每一个平台都会自己特定的优势,你是否利用了其独特的优势。首先要是知道这个平台的特性有哪些。然后去查看利用了没有。有的时候,什么都不需要做,就只需要改变一下编译选项就解决问题了。
一般source code 都会有各种宏,来控制代码的生成,例如opencl,还是cuda,以及是什么GPU,都是可以配置生成对应的代码来得到优化。
对于一些策略的优化¶
对于大的工程来说,每一次编译都需要挺长的时间,并且并不是很一个工程可以定制化做的很好。这个时候怎么办呢。那就是gdb中的或者ptrace来做性能测试。同时来修改程序的各个参数来生成对应的report.再加上gdb加上python的扩展,就可以相当shell可以重复使用。
The command is “readelf -A libapp.so”. With hardware fp, you will be able to see ” Tag_ABI_VFP_args” section.
Usign armeabi-v7a, you will by default get those compiler settings ” -march=armv7-a -mfloat-abi=softfp -mfpu=vfp -mthumb”, if I am not wrong. Both “softfp” and “hard” (for mfloat-abi) are using hardware floating, here is a link for your reference: https://wiki.debian.org/ArmHardFloatPort/VfpComparison#FPU_selection
Please request them to change APP_ABI to armeabi-v7a.
t430:~/work/jiuyin$ readelf -A libapp.so Attribute Section: aeabi File Attributes
Tag_CPU_name: "5TE"
Tag_CPU_arch: v5TE
Tag_ARM_ISA_use: Yes
Tag_THUMB_ISA_use: Thumb-1
Tag_FP_arch: VFPv2
Tag_ABI_PCS_wchar_t: 4
Tag_ABI_FP_denormal: Needed
Tag_ABI_FP_exceptions: Needed
Tag_ABI_FP_number_model: IEEE 754
Tag_ABI_align_needed: 8-byte
Tag_ABI_enum_size: int
Tag_ABI_optimization_goals: Aggressive Speed xuan@xuan-t430:~/work/jiuyin$ readelf -A lib
libapp.so libfmodex.so
t430:~/work/jiuyin$ readelf -A libfmodex.so Attribute Section: aeabi File Attributes
Tag_CPU_name: "5TE"
Tag_CPU_arch: v5TE
Tag_ARM_ISA_use: Yes
Tag_THUMB_ISA_use: Thumb-1
Tag_FP_arch: VFPv1
Tag_ABI_PCS_wchar_t: 4
Tag_ABI_FP_denormal: Needed
Tag_ABI_FP_exceptions: Needed
Tag_ABI_FP_number_model: IEEE 754
Tag_ABI_align_needed: 8-byte
Tag_ABI_align_preserved: 8-byte, except leaf SP
Tag_ABI_enum_size: int
Tag_ABI_optimization_goals: Aggressive Speed xuan@xuan-t430:~/work/jiuyin$
动态的得到callstack¶
sudo gdb -ex "set pagination 0" -ex "thread apply all bt" --batch --pid `pidof python`
https://github.com/springmeyer/profiling-guide
各种profiling的核心在于数据格式交换,后期可以采用数据可视化的工具来做各种显示。 perf data format
运行框架¶
instruction, counter, trace. 不同级别的profiling方法,在性能与灵活性是不一样的。把这些数据收集上来了,后面就分析了。 counter可是硬件,也可以是软件的。
android的profiling¶
profiling¶
https://selenic.com/hg/file/tip/contrib/perf.py https://docs.python.org/2/library/hotshot.html
Yoctoproject tools usage¶
分层优化¶
每一层的优化
- Number of memory allocation
- Number of system calls
- Concurrency model
optimization should focus on the critical path. optimize where it makes difference. Optimizing pieces of code that are not on the critical path is wasted effort.
不同的操作对于scale关系是不一样的。并不是一个简单线性关系。 所以在优化的时候,不要假定只有一个最佳方案。 是要根据约束来进行解决方程的。 所以profiling一定弄清楚配置情况来进行。 例如copy 文件的大小,对性能影响也是不一样的。 copy方便,还是传指针方便,最终体现是指令数,例如小于2个字节。传个指针也得四个四字节吧。
同步的方法¶
信号,或者atomic CPU operations.
profiling也是分层模块化¶
http://www.brendangregg.com/linuxperf.html 看其图。 硬件层,一般都会对应PMUdriver与之对应。 例如CPU cycles, instructions retired, memory stall cycles, level2 cache missing. #. 找到bottleneck可以考虑是替换算法,以及数据结构 #. 减少overhead. 例如函数调用的。 #. 从callstack看到函数后,要从框架上看,从哪里动手最合理。 而不是简单只要找到最大的函数直接优化本身。有可能这个函数使用最大是由于上一层算法的调用问题。 #. 找到真正的原因。从flat模式可以看哪一个函数用的最多。 TOP-Bottom,有利于分解,bottom-top快速看到最大值,并且都是调用的。 #. 找到最大值,一般有两种方法: 换一个更好的算法与数据结构,或者重写surrouding program 把这个函数给扔掉。 具取于为什么它这么大。
生成callgraph¶
perf record -g ./cmatrix
perf report --stdio
OSkernel层¶
tracepint¶
- system calls,TCP events, file system I/O, disk I/O,
- Dynamic Tracing kprobes and uprobes.
- Timed Profiling. with CPU usage.
- process create/statechange/terminal.
- thread create/statechange/terminal
- IO event
- resource allocation
可以使用systemtrap生成kprobe hooks,只是在需要检查的指令的第一个字节中插入一个断点指令,当调用该指令时,将执行对探针的特定处理函数,执行完成之后接着执行 原始的指令(从断点开始)。就是一个中断的过程。 http://blog.csdn.net/wudongxu/article/details/6345481 先用脚本生成C语言,然后再编译插入 ko. https://www.ibm.com/developerworks/cn/linux/l-systemtap/
software¶
- event message
可视化工具¶
CPU flame graph,http://www.brendangregg.com/flamegraphs.html heat map, timeline.
从哪里寻找工具¶
- Who is causing the load? PID,UID,IP addr,…
- Why is the load called? code path
- What is the load? IOPS,tput,direction,type
- How is the load changing over time?
- Best performance wins are from eliminating unnecessary work
tuning¶
通过/sys/kernel/…来调整配置。
优化的过程就是资源重新分配的过程。也就是对数据结构重构的过程。 对于大数据结构的实现,都是基于array,list,hash,tree. 以及对应的操作。修改代码也改这些并与之相应的操作,来应对算法输入的scale要求。profiling的理论基础是计算复杂度理论。
Collect common subexpressions. 尽可能让计算只做一次,但到底是用时间换空间,还是空间换时间。
sqrt(dx*dx + dy*dy) +((sqrt(dx*dx + dy*dy)>0)....)
像这种采用一次的计算,还是多次,取决于指令的速度。 变量赋值意味着大量的move操作,一个是move本身的速度,还有move的位置,不同存储bandwith也是不一样的。
Replace expensive operations by cheap ones. 这个计算的机指令周期了。 不同硬件对不指令周期也都是不同。 例如精度要求不高,可以用单精度指令来计算。 除法,尽可能用移位来计算来进行近似计算。
Unroll or elminate loops, 这样可以大大减少overhead. 但是这样加大代码的长度。或者降低loop的次数与层数。
提高cache 的命中率,通过局部化算法来提高。
根据操作overhead,要考虑是批处理或者二分级处理。 例如内存分配,一次分配个大大。自己来做二次分配。因为默认内存管理方式可能对你应用程序来说可能并不高效。
批处理的作法,那是用buffer input and output.所以在printf的时候,在不需要 n的时候,没有必要习惯性的加。
Handle special sperately. 没必要完全大一统。 特殊的地方,特殊处理。 就像内存分配方法,可以同时支持几种不同分配方法。例如动态array的增长方法,没有都采用一个方法。 用参数来指定不同的算法。
Precompute result. 算算数据依赖需不需要动态,不需要的话,完成可以提前计算,然后查表。但是特别容易算的,也就没有必要存了,因为读取也是要时间的。
Rewrite in a lower language. 在分层实现的时候可以用。机器生成代码的效率与人优化的代码指令精减度是不一样的。
对于空间效率来说,尽量采用少的数据类型,这也是为什么arm中他们经常使用thunder指令集的一个原因。空间效率也是有代价的,例如要在内存解压。也是要时间的。
提前评估各个单元时间效率 这个表在Pactice of Programming Page 193.
指令本身
不同类型指令,同样是+,-等等不同data type也是不一样的。
存取速度
array的一维,二维,三维 hash,以及数据类型的影响。
各层API本身
当然可以读各家的数据手册,得到这些数据。 各个硬件厂商都会提供这些数据的。
对于操作系统的优化¶
- 2-20% wins, I/O or buffer size tuning, NUMA config,etc
- 2-200x wins: bugs, disable features, perturbations causing latency outliers.
- Kernels change, new devices are added, workloads scale, and new perf issue are encountered
- Analyze application perf from kernel/system context 2-2000x wins, identifing and eliminating unnecessary work.
对优化的策略¶
- 要方便可重复,保存相关元数据,例如版本,配置文件等等。并且要保持往前走,而不是回退。 保存数据,并且利用可视化工具来推动往前走。
iostat,ionice
Utrace,systemtap,Dtrace¶
http://landley.net/kdocs/ols/2007/ols2007v1-pages-215-224.pdf 为了提高profiling本身性能以及灵活性,人们已经不断探索之后。
Dtrace 采用的是 expect的 expect/action模式,并且采用D语言来实现脚本。 http://www.ibm.com/developerworks/cn/linux/l-cn-systemtap2/
可视化¶
最好的可视化,就像示波器一样,有一个系统的原理框图,并且各个模块的数据演示在上面,例如热图的变化等等。 系统图就像http://www.brendangregg.com/usemethod.html 方法里提到的一样。USE是一种比较可行的方法。
profiling experiments¶
cmatrix¶
https://github.com/abishekvashok/cmatrix
总体用一个二维的数组保存状态,然后循环更新一行,有新的一行,就随机生成。关键是加入一些垂直的空格,这样看起来就像向下滚动。并加入一颜色。 应用vim 的键盘操作也能实现。
/* Matrix typedef */
typedef struct cmatrix {
int val;
int bold;
} cmatrix;
主要是利用了库 libncurses 来实现。
主要使用到的函数.
move(i,j)
attron(COLOR_PAIR(COLOR_WHITE))
addch(matrix[i][j].val)
attroff(COLOR_PAIR(COLOR_WHITE))
namps(ms) //sleep for ms millseconds
总共用了近3个小时,code lines 总共也才725 行。正常用应该用半个小时就应该够了。
git clone
./configure --enable-debug
vim Makefile remove -O2
perf record -g ./cmatrix
perf record //flat call time usage
perf report --stdio //callgraph
#. profiling with SP
LD_PRELOAD="/opt/nvidia/system_profiler/libPerfInjection64.so" ./cmatrix
#. vscode debug the code
分析¶
动态二维数据分配是有问题,是正好,cmatrix 大小正好等于了 指针的长度。
cmatrix **matrix = (cmatrix **) NULL; .... matrix = nmalloc(sizeof(cmatrix **) * (LINES + 1)); for (i = 0; i <= LINES; i++) { matrix[i] = nmalloc(sizeof(cmatrix) * COLS); }